Xu Yang
Papers from this author
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
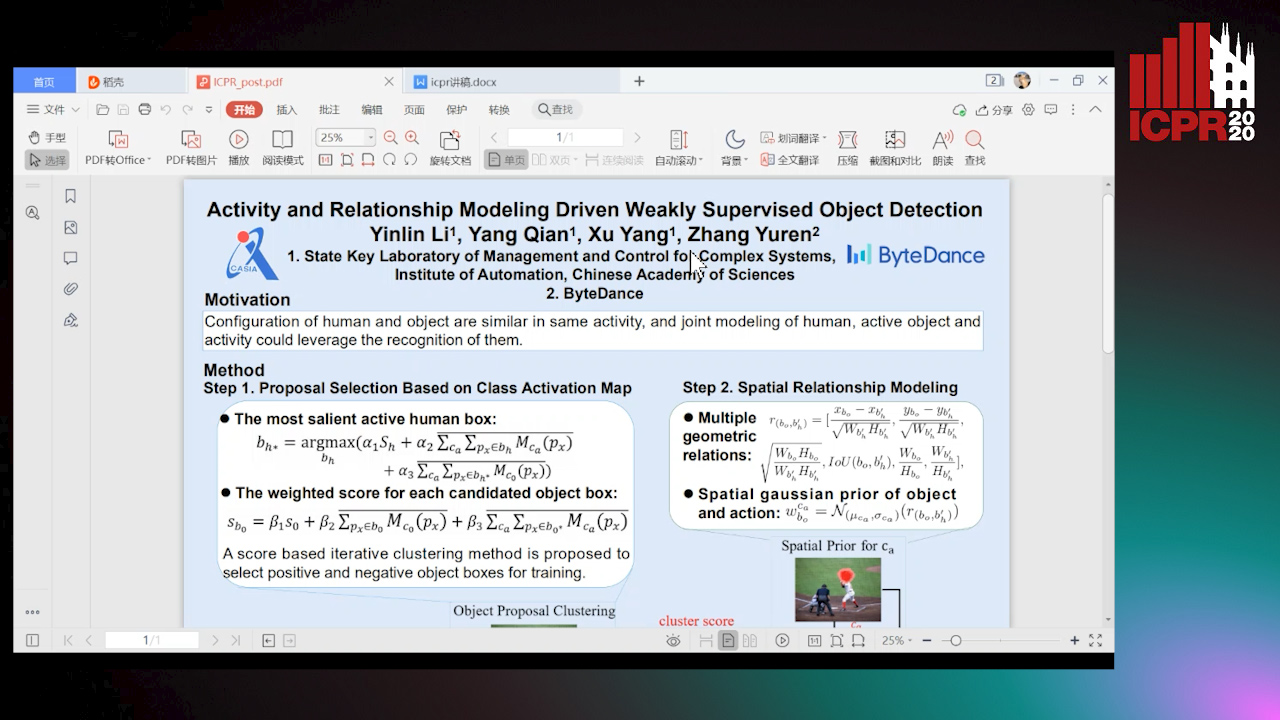
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
MixedFusion: 6D Object Pose Estimation from Decoupled RGB-Depth Features
Hangtao Feng, Lu Zhang, Xu Yang, Zhiyong Liu

Auto-TLDR; MixedFusion: Combining Color and Point Clouds for 6D Pose Estimation
Abstract Slides Poster Similar