Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li,
Yang Qian,
Xu Yang,
Yuren Zhang
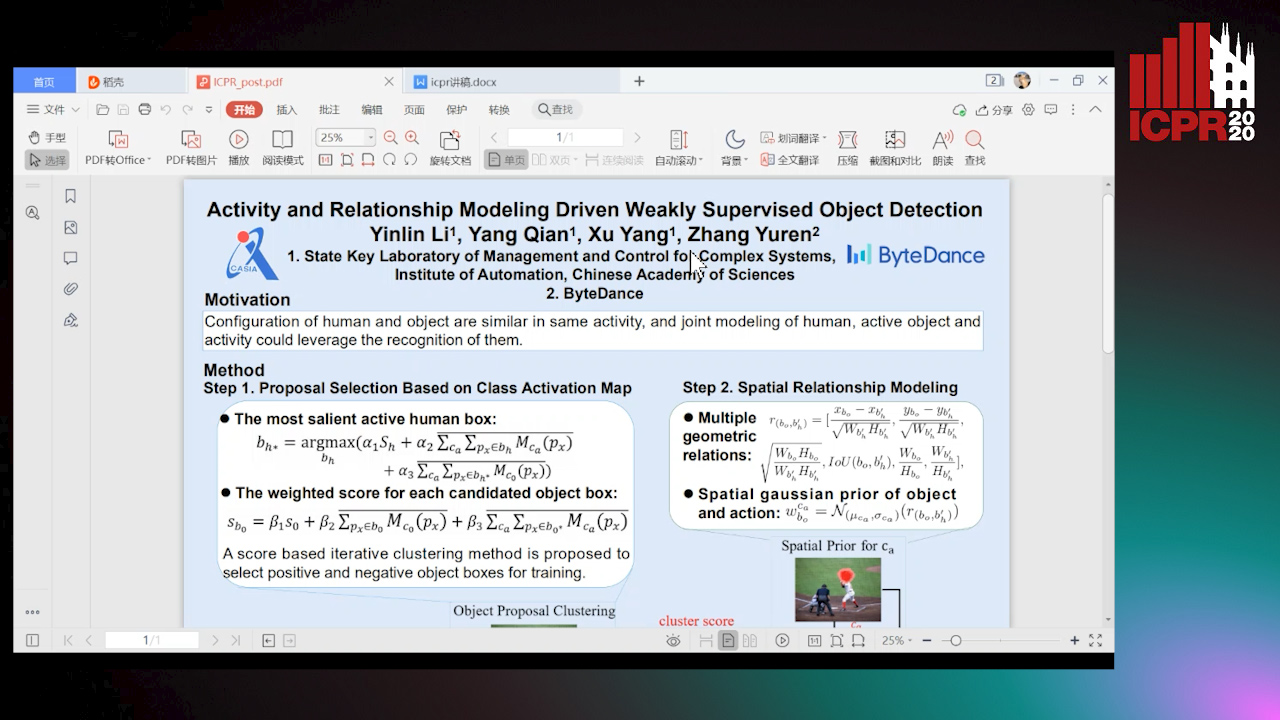
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Similar papers
Human-Centric Parsing Network for Human-Object Interaction Detection
Guanyu Chen, Chong Chen, Zhicheng Zhao, Fei Su

Auto-TLDR; Human-Centric Parsing Network for Human-Object Interactions Detection
Abstract Slides Poster Similar
Self-Selective Context for Interaction Recognition
Kilickaya Kilickaya, Noureldien Hussein, Efstratios Gavves, Arnold Smeulders

Auto-TLDR; Self-Selective Context for Human-Object Interaction Recognition
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Context Aware Group Activity Recognition
Avijit Dasgupta, C. V. Jawahar, Karteek Alahari

Auto-TLDR; A Two-Stream Architecture for Group Activity Recognition in Multi-Person Videos
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Attention-Based Selection Strategy for Weakly Supervised Object Localization

Auto-TLDR; An Attention-based Selection Strategy for Weakly Supervised Object Localization
Abstract Slides Poster Similar
StrongPose: Bottom-up and Strong Keypoint Heat Map Based Pose Estimation

Auto-TLDR; StrongPose: A bottom-up box-free approach for human pose estimation and action recognition
Abstract Slides Poster Similar
Feature Pyramid Hierarchies for Multi-Scale Temporal Action Detection

Auto-TLDR; Temporal Action Detection using Pyramid Hierarchies and Multi-scale Feature Maps
Abstract Slides Poster Similar
Mutual-Supervised Feature Modulation Network for Occluded Pedestrian Detection

Auto-TLDR; A Mutual-Supervised Feature Modulation Network for Occluded Pedestrian Detection
You Ought to Look Around: Precise, Large Span Action Detection
Ge Pan, Zhang Han, Fan Yu, Yonghong Song, Yuanlin Zhang, Han Yuan

Auto-TLDR; YOLA: Local Feature Extraction for Action Localization with Variable receptive field
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
An Improved Bilinear Pooling Method for Image-Based Action Recognition

Auto-TLDR; An improved bilinear pooling method for image-based action recognition
Abstract Slides Poster Similar
Forground-Guided Vehicle Perception Framework
Kun Tian, Tong Zhou, Shiming Xiang, Chunhong Pan

Auto-TLDR; A foreground segmentation branch for vehicle detection
Abstract Slides Poster Similar
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Object Detection Using Dual Graph Network
Shengjia Chen, Zhixin Li, Feicheng Huang, Canlong Zhang, Huifang Ma

Auto-TLDR; A Graph Convolutional Network for Object Detection with Key Relation Information
Multi-Label Contrastive Focal Loss for Pedestrian Attribute Recognition
Xiaoqiang Zheng, Zhenxia Yu, Lin Chen, Fan Zhu, Shilong Wang

Auto-TLDR; Multi-label Contrastive Focal Loss for Pedestrian Attribute Recognition
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
Precise Temporal Action Localization with Quantified Temporal Structure of Actions
Chongkai Lu, Ruimin Li, Hong Fu, Bin Fu, Yihao Wang, Wai Lun Lo, Zheru Chi

Auto-TLDR; Action progression networks for temporal action detection
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
Inferring Tasks and Fluents in Videos by Learning Causal Relations
Haowen Tang, Ping Wei, Huan Li, Nanning Zheng

Auto-TLDR; Joint Learning of Complex Task and Fluent States in Videos
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
Self-Training for Domain Adaptive Scene Text Detection
Yudi Chen, Wei Wang, Yu Zhou, Fei Yang, Dongbao Yang, Weiping Wang

Auto-TLDR; A self-training framework for image-based scene text detection
A Fast and Accurate Object Detector for Handwritten Digit String Recognition
Jun Guo, Wenjing Wei, Yifeng Ma, Cong Peng

Auto-TLDR; ChipNet: An anchor-free object detector for handwritten digit string recognition
Abstract Slides Poster Similar
Attention Based Multi-Instance Thyroid Cytopathological Diagnosis with Multi-Scale Feature Fusion
Shuhao Qiu, Yao Guo, Chuang Zhu, Wenli Zhou, Huang Chen

Auto-TLDR; A weakly supervised multi-instance learning framework based on attention mechanism with multi-scale feature fusion for thyroid cytopathological diagnosis
Abstract Slides Poster Similar
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
Coarse to Fine: Progressive and Multi-Task Learning for Salient Object Detection
Dong-Goo Kang, Sangwoo Park, Joonki Paik

Auto-TLDR; Progressive and mutl-task learning scheme for salient object detection
Abstract Slides Poster Similar
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
DualBox: Generating BBox Pair with Strong Correspondence Via Occlusion Pattern Clustering and Proposal Refinement
Zheng Ge, Chuyu Hu, Xin Huang, Baiqiao Qiu, Osamu Yoshie

Auto-TLDR; R2NMS: Combining Full and Visible Body Bounding Box for Dense Pedestrian Detection
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
CASNet: Common Attribute Support Network for Image Instance and Panoptic Segmentation
Xiaolong Liu, Yuqing Hou, Anbang Yao, Yurong Chen, Keqiang Li

Auto-TLDR; Common Attribute Support Network for instance segmentation and panoptic segmentation
Abstract Slides Poster Similar
Enhanced Vote Network for 3D Object Detection in Point Clouds

Auto-TLDR; A Vote Feature Enhancement Network for 3D Bounding Box Prediction
Abstract Slides Poster Similar
Zoom-CAM: Generating Fine-Grained Pixel Annotations from Image Labels
Xiangwei Shi, Seyran Khademi, Yunqiang Li, Jan Van Gemert

Auto-TLDR; Zoom-CAM for Weakly Supervised Object Localization and Segmentation
Abstract Slides Poster Similar
Utilising Visual Attention Cues for Vehicle Detection and Tracking
Feiyan Hu, Venkatesh Gurram Munirathnam, Noel E O'Connor, Alan Smeaton, Suzanne Little

Auto-TLDR; Visual Attention for Object Detection and Tracking in Driver-Assistance Systems
Abstract Slides Poster Similar
Cross-View Relation Networks for Mammogram Mass Detection
Ma Jiechao, Xiang Li, Hongwei Li, Ruixuan Wang, Bjoern Menze, Wei-Shi Zheng

Auto-TLDR; Multi-view Modeling for Mass Detection in Mammogram
Abstract Slides Poster Similar