Self-Training for Domain Adaptive Scene Text Detection
Yudi Chen,
Wei Wang,
Yu Zhou,
Fei Yang,
Dongbao Yang,
Weiping Wang

Auto-TLDR; A self-training framework for image-based scene text detection
Similar papers
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
An Accurate Threshold Insensitive Kernel Detector for Arbitrary Shaped Text
Xijun Qian, Yifan Liu, Yu-Bin Yang

Auto-TLDR; TIKD: threshold insensitive kernel detector for arbitrary shaped text
TCATD: Text Contour Attention for Scene Text Detection
Ziling Hu, Wu Xingjiao, Jing Yang

Auto-TLDR; Text Contour Attention Text Detector
Abstract Slides Poster Similar
Mutually Guided Dual-Task Network for Scene Text Detection
Mengbiao Zhao, Wei Feng, Fei Yin, Xu-Yao Zhang, Cheng-Lin Liu

Auto-TLDR; A dual-task network for word-level and line-level text detection
Gaussian Constrained Attention Network for Scene Text Recognition
Zhi Qiao, Xugong Qin, Yu Zhou, Fei Yang, Weiping Wang

Auto-TLDR; Gaussian Constrained Attention Network for Scene Text Recognition
Abstract Slides Poster Similar
Stratified Multi-Task Learning for Robust Spotting of Scene Texts
Kinjal Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; Feature Representation Block for Multi-task Learning of Scene Text
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Eun-Soo Jung, Hyeonggwan Son, Kyusam Oh, Yongkeun Yun, Soonhwan Kwon, Min Soo Kim

Auto-TLDR; Text Detection for Document Images Using Synthetic and Real Data
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
Text Recognition in Real Scenarios with a Few Labeled Samples
Jinghuang Lin, Cheng Zhanzhan, Fan Bai, Yi Niu, Shiliang Pu, Shuigeng Zhou

Auto-TLDR; Few-shot Adversarial Sequence Domain Adaptation for Scene Text Recognition
Abstract Slides Poster Similar
Recognizing Multiple Text Sequences from an Image by Pure End-To-End Learning
Zhenlong Xu, Shuigeng Zhou, Fan Bai, Cheng Zhanzhan, Yi Niu, Shiliang Pu

Auto-TLDR; Pure End-to-End Learning for Multiple Text Sequences Recognition from Images
Abstract Slides Poster Similar
MEAN: A Multi-Element Attention Based Network for Scene Text Recognition
Ruijie Yan, Liangrui Peng, Shanyu Xiao, Gang Yao, Jaesik Min

Auto-TLDR; Multi-element Attention Network for Scene Text Recognition
Abstract Slides Poster Similar
Weakly Supervised Attention Rectification for Scene Text Recognition
Chengyu Gu, Shilin Wang, Yiwei Zhu, Zheng Huang, Kai Chen

Auto-TLDR; An auxiliary supervision branch for attention-based scene text recognition
Abstract Slides Poster Similar
Unsupervised Domain Adaptation with Multiple Domain Discriminators and Adaptive Self-Training
Teo Spadotto, Marco Toldo, Umberto Michieli, Pietro Zanuttigh

Auto-TLDR; Unsupervised Domain Adaptation for Semantic Segmentation of Urban Scenes
Abstract Slides Poster Similar
Sample-Aware Data Augmentor for Scene Text Recognition
Guanghao Meng, Tao Dai, Shudeng Wu, Bin Chen, Jian Lu, Yong Jiang, Shutao Xia

Auto-TLDR; Sample-Aware Data Augmentation for Scene Text Recognition
Abstract Slides Poster Similar
A Multi-Head Self-Relation Network for Scene Text Recognition
Zhou Junwei, Hongchao Gao, Jiao Dai, Dongqin Liu, Jizhong Han

Auto-TLDR; Multi-head Self-relation Network for Scene Text Recognition
Abstract Slides Poster Similar
SSDL: Self-Supervised Domain Learning for Improved Face Recognition
Samadhi Poornima Kumarasinghe Wickrama Arachchilage, Ebroul Izquierdo

Auto-TLDR; Self-supervised Domain Learning for Face Recognition in unconstrained environments
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Local Gradient Difference Based Mass Features for Classification of 2D-3D Natural Scene Text Images
Lokesh Nandanwar, Shivakumara Palaiahnakote, Raghavendra Ramachandra, Tong Lu, Umapada Pal, Daniel Lopresti, Nor Badrul Anuar
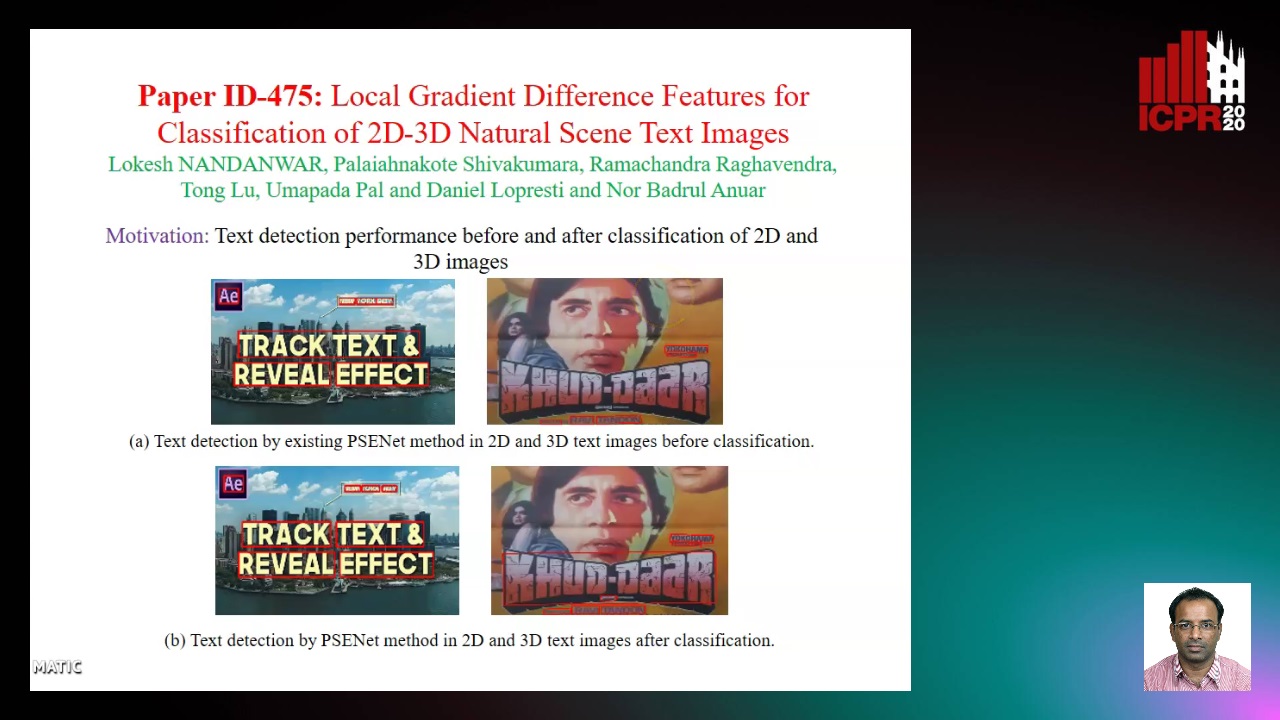
Auto-TLDR; Classification of 2D and 3D Natural Scene Images Using COLD
Abstract Slides Poster Similar
Progressive Unsupervised Domain Adaptation for Image-Based Person Re-Identification
Mingliang Yang, Da Huang, Jing Zhao

Auto-TLDR; Progressive Unsupervised Domain Adaptation for Person Re-Identification
Abstract Slides Poster Similar
Manual-Label Free 3D Detection Via an Open-Source Simulator
Zhen Yang, Chi Zhang, Zhaoxiang Zhang, Huiming Guo

Auto-TLDR; DA-VoxelNet: A Novel Domain Adaptive VoxelNet for LIDAR-based 3D Object Detection
Abstract Slides Poster Similar
Foreground-Focused Domain Adaption for Object Detection

Auto-TLDR; Unsupervised Domain Adaptation for Unsupervised Object Detection
Transferable Adversarial Attacks for Deep Scene Text Detection
Shudeng Wu, Tao Dai, Guanghao Meng, Bin Chen, Jian Lu, Shutao Xia

Auto-TLDR; Robustness of DNN-based STD methods against Adversarial Attacks
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
Energy-Constrained Self-Training for Unsupervised Domain Adaptation
Xiaofeng Liu, Xiongchang Liu, Bo Hu, Jun Lu, Jonghye Woo, Jane You

Auto-TLDR; Unsupervised Domain Adaptation with Energy Function Minimization
Abstract Slides Poster Similar
ReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Qi Song, Qianyi Jiang, Xiaolin Wei, Nan Li, Rui Zhang

Auto-TLDR; ReADS: Rectified Attentional Double Supervised Network for General Scene Text Recognition
Abstract Slides Poster Similar
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
MagnifierNet: Learning Efficient Small-Scale Pedestrian Detector towards Multiple Dense Regions
Qi Cheng, Mingqin Chen, Yingjie Wu, Fei Chen, Shiping Lin

Auto-TLDR; MagnifierNet: A Simple but Effective Small-Scale Pedestrian Detection Towards Multiple Dense Regions
Abstract Slides Poster Similar
Cost-Effective Adversarial Attacks against Scene Text Recognition
Mingkun Yang, Haitian Zheng, Xiang Bai, Jiebo Luo

Auto-TLDR; Adversarial Attacks on Scene Text Recognition
Abstract Slides Poster Similar
2D License Plate Recognition based on Automatic Perspective Rectification
Hui Xu, Zhao-Hong Guo, Da-Han Wang, Xiang-Dong Zhou, Yu Shi

Auto-TLDR; Perspective Rectification Network for License Plate Recognition
Abstract Slides Poster Similar
Semi-Supervised Domain Adaptation Via Selective Pseudo Labeling and Progressive Self-Training

Auto-TLDR; Semi-supervised Domain Adaptation with Pseudo Labels
Abstract Slides Poster Similar
SynDHN: Multi-Object Fish Tracker Trained on Synthetic Underwater Videos
Mygel Andrei Martija, Prospero Naval

Auto-TLDR; Underwater Multi-Object Tracking in the Wild with Deep Hungarian Network
Abstract Slides Poster Similar
Semi-Supervised Person Re-Identification by Attribute Similarity Guidance
Peixian Hong, Ancong Wu, Wei-Shi Zheng

Auto-TLDR; Attribute Similarity Guidance Guidance Loss for Semi-supervised Person Re-identification
Abstract Slides Poster Similar
VTT: Long-Term Visual Tracking with Transformers
Tianling Bian, Yang Hua, Tao Song, Zhengui Xue, Ruhui Ma, Neil Robertson, Haibing Guan

Auto-TLDR; Visual Tracking Transformer with transformers for long-term visual tracking
Siamese Dynamic Mask Estimation Network for Fast Video Object Segmentation
Dexiang Hong, Guorong Li, Kai Xu, Li Su, Qingming Huang

Auto-TLDR; Siamese Dynamic Mask Estimation for Video Object Segmentation
Abstract Slides Poster Similar
Online Domain Adaptation for Person Re-Identification with a Human in the Loop
Rita Delussu, Lorenzo Putzu, Giorgio Fumera, Fabio Roli

Auto-TLDR; Human-in-the-loop for Person Re-Identification in Infeasible Applications
Abstract Slides Poster Similar
Learning Object Deformation and Motion Adaption for Semi-Supervised Video Object Segmentation
Xiaoyang Zheng, Xin Tan, Jianming Guo, Lizhuang Ma

Auto-TLDR; Semi-supervised Video Object Segmentation with Mask-propagation-based Model
Abstract Slides Poster Similar
IBN-STR: A Robust Text Recognizer for Irregular Text in Natural Scenes
Xiaoqian Li, Jie Liu, Shuwu Zhang

Auto-TLDR; IBN-STR: A Robust Text Recognition System Based on Data and Feature Representation
Tracking Fast Moving Objects by Segmentation Network

Auto-TLDR; Fast Moving Objects Tracking by Segmentation Using Deep Learning
Abstract Slides Poster Similar
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
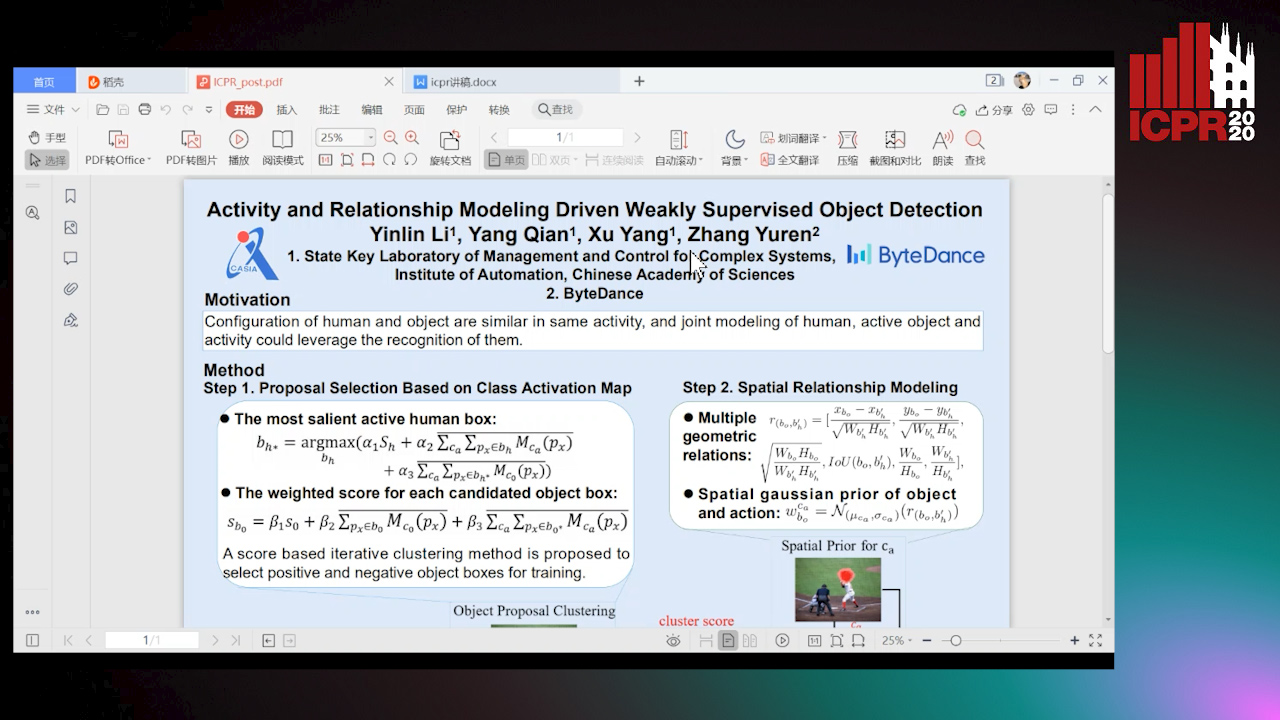
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
EAGLE: Large-Scale Vehicle Detection Dataset in Real-World Scenarios Using Aerial Imagery
Seyed Majid Azimi, Reza Bahmanyar, Corentin Henry, Kurz Franz

Auto-TLDR; EAGLE: A Large-Scale Dataset for Multi-class Vehicle Detection with Object Orientation Information in Airborne Imagery
Which Airline Is This? Airline Logo Detection in Real-World Weather Conditions
Christian Wilms, Rafael Heid, Mohammad Araf Sadeghi, Andreas Ribbrock, Simone Frintrop

Auto-TLDR; Airlines logo detection on airplane tails using data augmentation
Abstract Slides Poster Similar