Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong,
Shuhui Bu,
Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Similar papers
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Pongpisit Thanasutives, Ken-Ichi Fukui, Masayuki Numao, Boonserm Kijsirikul

Auto-TLDR; M-SFANet and M-SegNet for Crowd Counting Using Multi-Scale Fusion Networks
Abstract Slides Poster Similar
HANet: Hybrid Attention-Aware Network for Crowd Counting
Xinxing Su, Yuchen Yuan, Xiangbo Su, Zhikang Zou, Shilei Wen, Pan Zhou

Auto-TLDR; HANet: Hybrid Attention-Aware Network for Crowd Counting with Adaptive Compensation Loss
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Learning Error-Driven Curriculum for Crowd Counting
Wenxi Li, Zhuoqun Cao, Qian Wang, Songjian Chen, Rui Feng

Auto-TLDR; Learning Error-Driven Curriculum for Crowd Counting with TutorNet
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Ryota Akai, Yuzuko Utsumi, Yuka Miwa, Masakazu Iwamura, Koichi Kise

Auto-TLDR; Object Counting for Omnidirectional Images Using Stereographic Projection
VGG-Embedded Adaptive Layer-Normalized Crowd Counting Net with Scale-Shuffling Modules
Dewen Guo, Jie Feng, Bingfeng Zhou

Auto-TLDR; VadaLN: VGG-embedded Adaptive Layer Normalization for Crowd Counting
Abstract Slides Poster Similar
CT-UNet: An Improved Neural Network Based on U-Net for Building Segmentation in Remote Sensing Images
Huanran Ye, Sheng Liu, Kun Jin, Haohao Cheng

Auto-TLDR; Context-Transfer-UNet: A UNet-based Network for Building Segmentation in Remote Sensing Images
Abstract Slides Poster Similar
PHNet: Parasite-Host Network for Video Crowd Counting
Shiqiao Meng, Jiajie Li, Weiwei Guo, Jinfeng Jiang, Lai Ye

Auto-TLDR; PHNet: A Parasite-Host Network for Video Crowd Counting
Abstract Slides Poster Similar
RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery

Auto-TLDR; RescueNet: End-to-End Building Segmentation and Damage Classification for Humanitarian Aid and Disaster Response
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Attention-Based Selection Strategy for Weakly Supervised Object Localization

Auto-TLDR; An Attention-based Selection Strategy for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Multi-Resolution Fusion and Multi-Scale Input Priors Based Crowd Counting
Usman Sajid, Wenchi Ma, Guanghui Wang

Auto-TLDR; Multi-resolution Fusion Based End-to-End Crowd Counting in Still Images
Abstract Slides Poster Similar
Spatial-Related and Scale-Aware Network for Crowd Counting
Lei Li, Yuan Dong, Hongliang Bai

Auto-TLDR; Spatial Attention for Crowd Counting
Abstract Slides Poster Similar
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Coarse to Fine: Progressive and Multi-Task Learning for Salient Object Detection
Dong-Goo Kang, Sangwoo Park, Joonki Paik

Auto-TLDR; Progressive and mutl-task learning scheme for salient object detection
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
CASNet: Common Attribute Support Network for Image Instance and Panoptic Segmentation
Xiaolong Liu, Yuqing Hou, Anbang Yao, Yurong Chen, Keqiang Li

Auto-TLDR; Common Attribute Support Network for instance segmentation and panoptic segmentation
Abstract Slides Poster Similar
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
Detecting Marine Species in Echograms Via Traditional, Hybrid, and Deep Learning Frameworks
Porto Marques Tunai, Alireza Rezvanifar, Melissa Cote, Alexandra Branzan Albu, Kaan Ersahin, Todd Mudge, Stephane Gauthier

Auto-TLDR; End-to-End Deep Learning for Echogram Interpretation of Marine Species in Echograms
Abstract Slides Poster Similar
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
Learning from Web Data: Improving Crowd Counting Via Semi-Supervised Learning

Auto-TLDR; Semi-supervised Crowd Counting Baseline for Deep Neural Networks
Abstract Slides Poster Similar
SIMCO: SIMilarity-Based Object COunting
Marco Godi, Christian Joppi, Andrea Giachetti, Marco Cristani

Auto-TLDR; SIMCO: An Unsupervised Multi-class Object Counting Approach on InShape
Abstract Slides Poster Similar
Tiny Object Detection in Aerial Images
Jinwang Wang, Wen Yang, Haowen Guo, Ruixiang Zhang, Gui-Song Xia

Auto-TLDR; Tiny Object Detection in Aerial Images Using Multiple Center Points Based Learning Network
Uncertainty Guided Recognition of Tiny Craters on the Moon
Thorsten Wilhelm, Christian Wöhler

Auto-TLDR; Accurately Detecting Tiny Craters in Remote Sensed Images Using Deep Neural Networks
Abstract Slides Poster Similar
DAPC: Domain Adaptation People Counting Via Style-Level Transfer Learning and Scene-Aware Estimation
Na Jiang, Xingsen Wen, Zhiping Shi

Auto-TLDR; Domain Adaptation People counting via Style-Level Transfer Learning and Scene-Aware Estimation
Abstract Slides Poster Similar
Holistic Grid Fusion Based Stop Line Estimation
Runsheng Xu, Faezeh Tafazzoli, Li Zhang, Timo Rehfeld, Gunther Krehl, Arunava Seal

Auto-TLDR; Fused Multi-Sensory Data for Stop Lines Detection in Intersection Scenarios
An Accurate Threshold Insensitive Kernel Detector for Arbitrary Shaped Text
Xijun Qian, Yifan Liu, Yu-Bin Yang

Auto-TLDR; TIKD: threshold insensitive kernel detector for arbitrary shaped text
Attention Based Multi-Instance Thyroid Cytopathological Diagnosis with Multi-Scale Feature Fusion
Shuhao Qiu, Yao Guo, Chuang Zhu, Wenli Zhou, Huang Chen

Auto-TLDR; A weakly supervised multi-instance learning framework based on attention mechanism with multi-scale feature fusion for thyroid cytopathological diagnosis
Abstract Slides Poster Similar
SyNet: An Ensemble Network for Object Detection in UAV Images

Auto-TLDR; SyNet: Combining Multi-Stage and Single-Stage Object Detection for Aerial Images
Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Dayang Yu, Rong Zhang, Shan Qin

Auto-TLDR; Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Abstract Slides Poster Similar
DualBox: Generating BBox Pair with Strong Correspondence Via Occlusion Pattern Clustering and Proposal Refinement
Zheng Ge, Chuyu Hu, Xin Huang, Baiqiao Qiu, Osamu Yoshie

Auto-TLDR; R2NMS: Combining Full and Visible Body Bounding Box for Dense Pedestrian Detection
Abstract Slides Poster Similar
Machine-Learned Regularization and Polygonization of Building Segmentation Masks
Stefano Zorzi, Ksenia Bittner, Friedrich Fraundorfer

Auto-TLDR; Automatic Regularization and Polygonization of Building Segmentation masks using Generative Adversarial Network
Abstract Slides Poster Similar
CAggNet: Crossing Aggregation Network for Medical Image Segmentation

Auto-TLDR; Crossing Aggregation Network for Medical Image Segmentation
Abstract Slides Poster Similar
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
Mamshad Nayeem Rizve, Ugur Demir, Praveen Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Rajendrakumar Dave, Yogesh Rawat, Mubarak Shah

Auto-TLDR; Gabriella: A Real-Time Online System for Activity Detection in Surveillance Videos
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
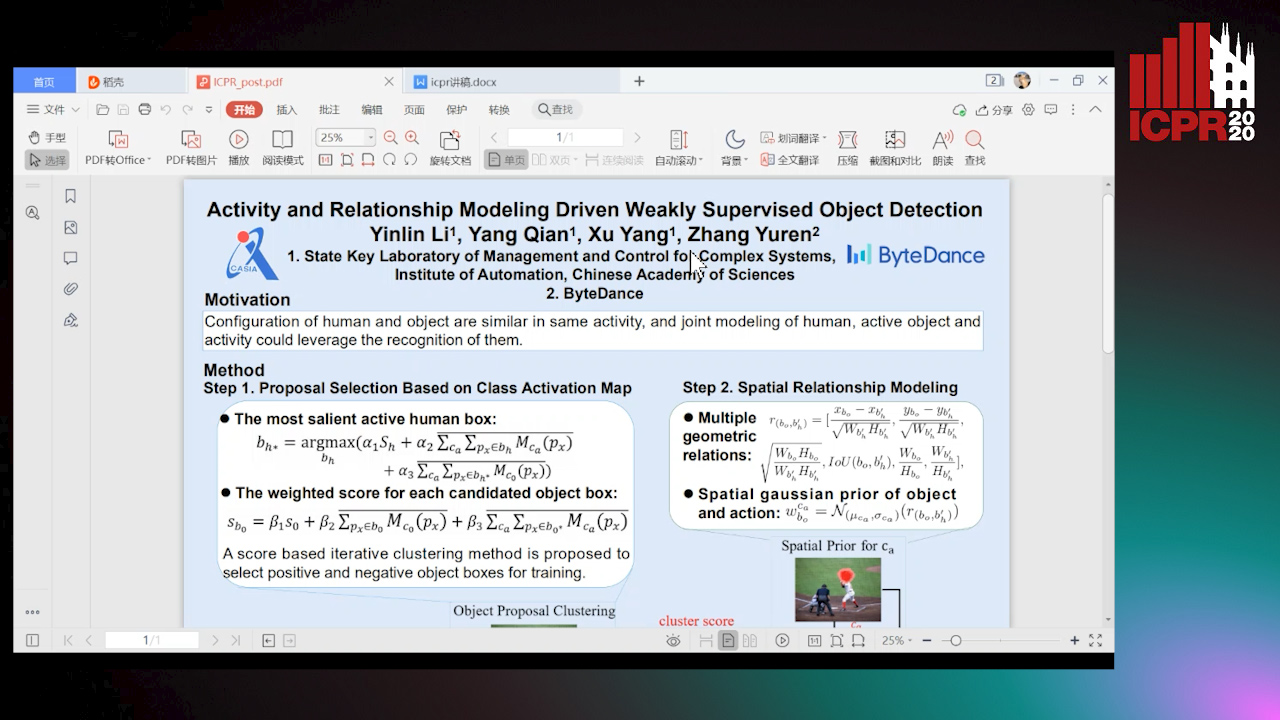
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
MagnifierNet: Learning Efficient Small-Scale Pedestrian Detector towards Multiple Dense Regions
Qi Cheng, Mingqin Chen, Yingjie Wu, Fei Chen, Shiping Lin

Auto-TLDR; MagnifierNet: A Simple but Effective Small-Scale Pedestrian Detection Towards Multiple Dense Regions
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Small Object Detection Leveraging on Simultaneous Super-Resolution
Hong Ji, Zhi Gao, Xiaodong Liu, Tiancan Mei

Auto-TLDR; Super-Resolution via Generative Adversarial Network for Small Object Detection
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
Forground-Guided Vehicle Perception Framework
Kun Tian, Tong Zhou, Shiming Xiang, Chunhong Pan

Auto-TLDR; A foreground segmentation branch for vehicle detection
Abstract Slides Poster Similar
Multiscale Attention-Based Prototypical Network for Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; Few-shot Semantic Segmentation with Multiscale Feature Attention