Attention-Based Selection Strategy for Weakly Supervised Object Localization

Auto-TLDR; An Attention-based Selection Strategy for Weakly Supervised Object Localization
Similar papers
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
Multi-Order Feature Statistical Model for Fine-Grained Visual Categorization
Qingtao Wang, Ke Zhang, Shaoli Huang, Lianbo Zhang, Jin Fan

Auto-TLDR; Multi-Order Feature Statistical Method for Fine-Grained Visual Categorization
Abstract Slides Poster Similar
Skin Lesion Classification Using Weakly-Supervised Fine-Grained Method
Xi Xue, Sei-Ichiro Kamata, Daming Luo

Auto-TLDR; Different Region proposal module for skin lesion classification
Abstract Slides Poster Similar
Zoom-CAM: Generating Fine-Grained Pixel Annotations from Image Labels
Xiangwei Shi, Seyran Khademi, Yunqiang Li, Jan Van Gemert

Auto-TLDR; Zoom-CAM for Weakly Supervised Object Localization and Segmentation
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
An Improved Bilinear Pooling Method for Image-Based Action Recognition

Auto-TLDR; An improved bilinear pooling method for image-based action recognition
Abstract Slides Poster Similar
Multi-Branch Attention Networks for Classifying Galaxy Clusters
Yu Zhang, Gongbo Liang, Yuanyuan Su, Nathan Jacobs

Auto-TLDR; Multi-branch Attention Networks for Classification of Galaxy Clusters
Abstract Slides Poster Similar
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Hyunseung Chung, Woo-Jeoung Nam, Seong-Whan Lee

Auto-TLDR; Robust Remote Sensing Image Retrieval Using Group Convolution with Attention Mechanism and Metric Learning
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
Foreground-Focused Domain Adaption for Object Detection

Auto-TLDR; Unsupervised Domain Adaptation for Unsupervised Object Detection
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
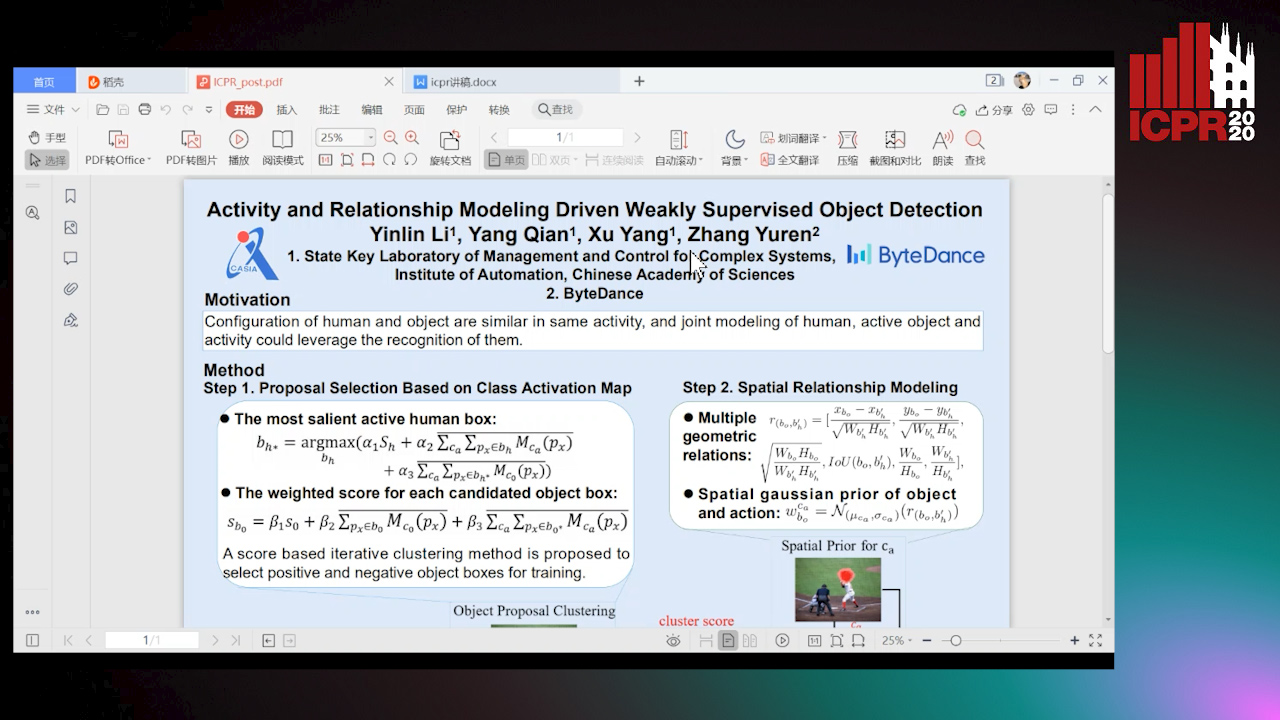
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Progressive Scene Segmentation Based on Self-Attention Mechanism
Yunyi Pan, Yuan Gan, Kun Liu, Yan Zhang

Auto-TLDR; Two-Stage Semantic Scene Segmentation with Self-Attention
Abstract Slides Poster Similar
Top-DB-Net: Top DropBlock for Activation Enhancement in Person Re-Identification

Auto-TLDR; Top-DB-Net for Person Re-Identification using Top DropBlock
Abstract Slides Poster Similar
Unsupervised Sound Source Localization From Audio-Image Pairs Using Input Gradient Map
Tomohiro Tanaka, Takahiro Shinozaki

Auto-TLDR; Unsupervised Sound Localization Using Gradient Method
Abstract Slides Poster Similar
SAT-Net: Self-Attention and Temporal Fusion for Facial Action Unit Detection
Zhihua Li, Zheng Zhang, Lijun Yin

Auto-TLDR; Temporal Fusion and Self-Attention Network for Facial Action Unit Detection
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Self and Channel Attention Network for Person Re-Identification
Asad Munir, Niki Martinel, Christian Micheloni

Auto-TLDR; SCAN: Self and Channel Attention Network for Person Re-identification
Abstract Slides Poster Similar
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
Utilising Visual Attention Cues for Vehicle Detection and Tracking
Feiyan Hu, Venkatesh Gurram Munirathnam, Noel E O'Connor, Alan Smeaton, Suzanne Little

Auto-TLDR; Visual Attention for Object Detection and Tracking in Driver-Assistance Systems
Abstract Slides Poster Similar
Local Attention and Global Representation Collaborating for Fine-Grained Classification
He Zhang, Yunming Bai, Hui Zhang, Jing Liu, Xingguang Li, Zhaofeng He

Auto-TLDR; Weighted Region Network for Cosmetic Contact Lenses Detection
Abstract Slides Poster Similar
Few-Shot Few-Shot Learning and the Role of Spatial Attention
Yann Lifchitz, Yannis Avrithis, Sylvaine Picard

Auto-TLDR; Few-shot Learning with Pre-trained Classifier on Large-Scale Datasets
Abstract Slides Poster Similar
Collaborative Human Machine Attention Module for Character Recognition
Chetan Ralekar, Tapan Gandhi, Santanu Chaudhury

Auto-TLDR; A Collaborative Human-Machine Attention Module for Deep Neural Networks
Abstract Slides Poster Similar
Robust Localization of Retinal Lesions Via Weakly-Supervised Learning

Auto-TLDR; Weakly Learning of Lesions in Fundus Images Using Multi-level Feature Maps and Classification Score
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
Attention Based Multi-Instance Thyroid Cytopathological Diagnosis with Multi-Scale Feature Fusion
Shuhao Qiu, Yao Guo, Chuang Zhu, Wenli Zhou, Huang Chen

Auto-TLDR; A weakly supervised multi-instance learning framework based on attention mechanism with multi-scale feature fusion for thyroid cytopathological diagnosis
Abstract Slides Poster Similar
Small Object Detection by Generative and Discriminative Learning
Yi Gu, Jie Li, Chentao Wu, Weijia Jia, Jianping Chen

Auto-TLDR; Generative and Discriminative Learning for Small Object Detection
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
Forground-Guided Vehicle Perception Framework
Kun Tian, Tong Zhou, Shiming Xiang, Chunhong Pan

Auto-TLDR; A foreground segmentation branch for vehicle detection
Abstract Slides Poster Similar
Deep Multiple Instance Learning with Spatial Attention for ROP Case Classification, Instance Selection and Abnormality Localization
Xirong Li, Wencui Wan, Yang Zhou, Jianchun Zhao, Qijie Wei, Junbo Rong, Pengyi Zhou, Limin Xu, Lijuan Lang, Yuying Liu, Chengzhi Niu, Dayong Ding, Xuemin Jin

Auto-TLDR; MIL-SA: Deep Multiple Instance Learning for Automated Screening of Retinopathy of Prematurity
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
Real-Time Semantic Segmentation Via Region and Pixel Context Network
Yajun Li, Yazhou Liu, Quansen Sun

Auto-TLDR; A Dual Context Network for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Dayang Yu, Rong Zhang, Shan Qin

Auto-TLDR; Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
MagnifierNet: Learning Efficient Small-Scale Pedestrian Detector towards Multiple Dense Regions
Qi Cheng, Mingqin Chen, Yingjie Wu, Fei Chen, Shiping Lin

Auto-TLDR; MagnifierNet: A Simple but Effective Small-Scale Pedestrian Detection Towards Multiple Dense Regions
Abstract Slides Poster Similar
HANet: Hybrid Attention-Aware Network for Crowd Counting
Xinxing Su, Yuchen Yuan, Xiangbo Su, Zhikang Zou, Shilei Wen, Pan Zhou

Auto-TLDR; HANet: Hybrid Attention-Aware Network for Crowd Counting with Adaptive Compensation Loss
Global Context-Based Network with Transformer for Image2latex
Nuo Pang, Chun Yang, Xiaobin Zhu, Jixuan Li, Xu-Cheng Yin

Auto-TLDR; Image2latex with Global Context block and Transformer
Abstract Slides Poster Similar
Generalized Local Attention Pooling for Deep Metric Learning
Carlos Roig Mari, David Varas, Issey Masuda, Juan Carlos Riveiro, Elisenda Bou-Balust

Auto-TLDR; Generalized Local Attention Pooling for Deep Metric Learning
Abstract Slides Poster Similar
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Semantic Segmentation
Zhuoying Wang, Yongtao Wang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin

Auto-TLDR; Gated Scale-Transfer Operation for Semantic Segmentation
Abstract Slides Poster Similar