Zoom-CAM: Generating Fine-Grained Pixel Annotations from Image Labels
Xiangwei Shi,
Seyran Khademi,
Yunqiang Li,
Jan Van Gemert

Auto-TLDR; Zoom-CAM for Weakly Supervised Object Localization and Segmentation
Similar papers
MFPP: Morphological Fragmental Perturbation Pyramid for Black-Box Model Explanations
Qing Yang, Xia Zhu, Jong-Kae Fwu, Yun Ye, Ganmei You, Yuan Zhu

Auto-TLDR; Morphological Fragmental Perturbation Pyramid for Explainable Deep Neural Network
Abstract Slides Poster Similar
Improving Explainability of Integrated Gradients with Guided Non-Linearity
Hyuk Jin Kwon, Hyung Il Koo, Nam Ik Cho

Auto-TLDR; Guided Non-linearity for Attribution in Convolutional Neural Networks
Abstract Slides Poster Similar
A Generalizable Saliency Map-Based Interpretation of Model Outcome
Shailja Thakur, Sebastian Fischmeister

Auto-TLDR; Interpretability of Deep Neural Networks Using Salient Input and Output
Robust Localization of Retinal Lesions Via Weakly-Supervised Learning

Auto-TLDR; Weakly Learning of Lesions in Fundus Images Using Multi-level Feature Maps and Classification Score
Abstract Slides Poster Similar
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Deep Multiple Instance Learning with Spatial Attention for ROP Case Classification, Instance Selection and Abnormality Localization
Xirong Li, Wencui Wan, Yang Zhou, Jianchun Zhao, Qijie Wei, Junbo Rong, Pengyi Zhou, Limin Xu, Lijuan Lang, Yuying Liu, Chengzhi Niu, Dayong Ding, Xuemin Jin

Auto-TLDR; MIL-SA: Deep Multiple Instance Learning for Automated Screening of Retinopathy of Prematurity
Combining Similarity and Adversarial Learning to Generate Visual Explanation: Application to Medical Image Classification
Martin Charachon, Roberto Roberto Ardon, Celine Hudelot, Paul-Henry Cournède, Camille Ruppli

Auto-TLDR; Explaining Black-Box Machine Learning Models with Visual Explanation
Abstract Slides Poster Similar
Attention-Based Selection Strategy for Weakly Supervised Object Localization

Auto-TLDR; An Attention-based Selection Strategy for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
Understanding Integrated Gradients with SmoothTaylor for Deep Neural Network Attribution
Gary Shing Wee Goh, Sebastian Lapuschkin, Leander Weber, Wojciech Samek, Alexander Binder

Auto-TLDR; SmoothGrad: bridging Integrated Gradients and SmoothGrad from the Taylor's theorem perspective
CCA: Exploring the Possibility of Contextual Camouflage Attack on Object Detection
Shengnan Hu, Yang Zhang, Sumit Laha, Ankit Sharma, Hassan Foroosh

Auto-TLDR; Contextual camouflage attack for object detection
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
WeightAlign: Normalizing Activations by Weight Alignment
Xiangwei Shi, Yunqiang Li, Xin Liu, Jan Van Gemert

Auto-TLDR; WeightAlign: Normalization of Activations without Sample Statistics
Abstract Slides Poster Similar
Multi-Order Feature Statistical Model for Fine-Grained Visual Categorization
Qingtao Wang, Ke Zhang, Shaoli Huang, Lianbo Zhang, Jin Fan

Auto-TLDR; Multi-Order Feature Statistical Method for Fine-Grained Visual Categorization
Abstract Slides Poster Similar
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Enhanced Feature Pyramid Network for Semantic Segmentation
Mucong Ye, Ouyang Jinpeng, Ge Chen, Jing Zhang, Xiaogang Yu

Auto-TLDR; EFPN: Enhanced Feature Pyramid Network for Semantic Segmentation
Abstract Slides Poster Similar
Multiscale Attention-Based Prototypical Network for Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; Few-shot Semantic Segmentation with Multiscale Feature Attention
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
SyNet: An Ensemble Network for Object Detection in UAV Images

Auto-TLDR; SyNet: Combining Multi-Stage and Single-Stage Object Detection for Aerial Images
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
Color, Edge, and Pixel-Wise Explanation of Predictions Based onInterpretable Neural Network Model

Auto-TLDR; Explainable Deep Neural Network with Edge Detecting Filters
How Does DCNN Make Decisions?
Yi Lin, Namin Wang, Xiaoqing Ma, Ziwei Li, Gang Bai

Auto-TLDR; Exploring Deep Convolutional Neural Network's Decision-Making Interpretability
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
Hierarchical Head Design for Object Detectors
Shivang Agarwal, Frederic Jurie

Auto-TLDR; Hierarchical Anchor for SSD Detector
Abstract Slides Poster Similar
CASNet: Common Attribute Support Network for Image Instance and Panoptic Segmentation
Xiaolong Liu, Yuqing Hou, Anbang Yao, Yurong Chen, Keqiang Li

Auto-TLDR; Common Attribute Support Network for instance segmentation and panoptic segmentation
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Local Attention and Global Representation Collaborating for Fine-Grained Classification
He Zhang, Yunming Bai, Hui Zhang, Jing Liu, Xingguang Li, Zhaofeng He

Auto-TLDR; Weighted Region Network for Cosmetic Contact Lenses Detection
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Semantic Segmentation Refinement Using Entropy and Boundary-guided Monte Carlo Sampling and Directed Regional Search
Zitang Sun, Sei-Ichiro Kamata, Ruojing Wang, Weili Chen

Auto-TLDR; Directed Region Search and Refinement for Semantic Segmentation
Abstract Slides Poster Similar
From Early Biological Models to CNNs: Do They Look Where Humans Look?
Marinella Iole Cadoni, Andrea Lagorio, Enrico Grosso, Jia Huei Tan, Chee Seng Chan

Auto-TLDR; Comparing Neural Networks to Human Fixations for Semantic Learning
Abstract Slides Poster Similar
Explanation-Guided Training for Cross-Domain Few-Shot Classification
Jiamei Sun, Sebastian Lapuschkin, Wojciech Samek, Yunqing Zhao, Ngai-Man Cheung, Alexander Binder

Auto-TLDR; Explaination-Guided Training for Cross-Domain Few-Shot Classification
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
FastSal: A Computationally Efficient Network for Visual Saliency Prediction

Auto-TLDR; MobileNetV2: A Convolutional Neural Network for Saliency Prediction
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Unsupervised Sound Source Localization From Audio-Image Pairs Using Input Gradient Map
Tomohiro Tanaka, Takahiro Shinozaki

Auto-TLDR; Unsupervised Sound Localization Using Gradient Method
Abstract Slides Poster Similar
Object Detection Using Dual Graph Network
Shengjia Chen, Zhixin Li, Feicheng Huang, Canlong Zhang, Huifang Ma

Auto-TLDR; A Graph Convolutional Network for Object Detection with Key Relation Information
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
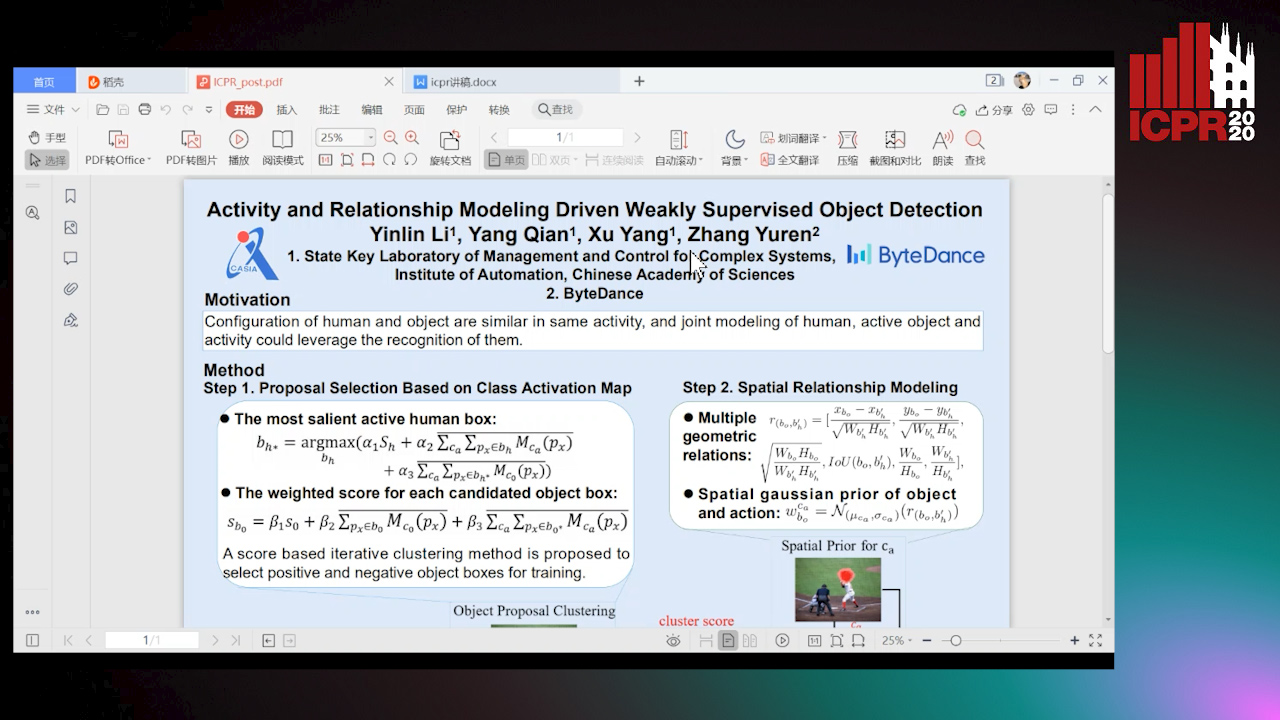
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Coarse to Fine: Progressive and Multi-Task Learning for Salient Object Detection
Dong-Goo Kang, Sangwoo Park, Joonki Paik

Auto-TLDR; Progressive and mutl-task learning scheme for salient object detection
Abstract Slides Poster Similar
Foreground-Focused Domain Adaption for Object Detection

Auto-TLDR; Unsupervised Domain Adaptation for Unsupervised Object Detection
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
ScarfNet: Multi-Scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Jin Hyeok Yoo, Dongsuk Kum, Jun Won Choi

Auto-TLDR; Semantic Fusion of Multi-scale Feature Maps for Object Detection
Abstract Slides Poster Similar
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Semantic Segmentation
Zhuoying Wang, Yongtao Wang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin

Auto-TLDR; Gated Scale-Transfer Operation for Semantic Segmentation
Abstract Slides Poster Similar