Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo,
Zhicheng Zhao,
Fei Su,
Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Similar papers
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
Bidirectional Matrix Feature Pyramid Network for Object Detection

Auto-TLDR; BMFPN: Bidirectional Matrix Feature Pyramid Network for Object Detection
Abstract Slides Poster Similar
CAggNet: Crossing Aggregation Network for Medical Image Segmentation

Auto-TLDR; Crossing Aggregation Network for Medical Image Segmentation
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
A Multi-Task Contextual Atrous Residual Network for Brain Tumor Detection & Segmentation
Ngan Le, Kashu Yamazaki, Quach Kha Gia, Thanh-Dat Truong, Marios Savvides

Auto-TLDR; Contextual Brain Tumor Segmentation Using 3D atrous Residual Networks and Cascaded Structures
Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection
Mengyuan Ding, Shanshan Zhang, Jian Yang

Auto-TLDR; Learningable Dynamic HRNet for Pedestrian Detection
Abstract Slides Poster Similar
Forground-Guided Vehicle Perception Framework
Kun Tian, Tong Zhou, Shiming Xiang, Chunhong Pan

Auto-TLDR; A foreground segmentation branch for vehicle detection
Abstract Slides Poster Similar
PRF-Ped: Multi-Scale Pedestrian Detector with Prior-Based Receptive Field
Yuzhi Tan, Hongxun Yao, Haoran Li, Xiusheng Lu, Haozhe Xie

Auto-TLDR; Bidirectional Feature Enhancement Module for Multi-Scale Pedestrian Detection
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
CenterRepp: Predict Central Representative Point Set's Distribution for Detection
Yulin He, Limeng Zhang, Wei Chen, Xin Luo, Chen Li, Xiaogang Jia

Auto-TLDR; CRPDet: CenterRepp Detector for Object Detection
Abstract Slides Poster Similar
CASNet: Common Attribute Support Network for Image Instance and Panoptic Segmentation
Xiaolong Liu, Yuqing Hou, Anbang Yao, Yurong Chen, Keqiang Li

Auto-TLDR; Common Attribute Support Network for instance segmentation and panoptic segmentation
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
Tiny Object Detection in Aerial Images
Jinwang Wang, Wen Yang, Haowen Guo, Ruixiang Zhang, Gui-Song Xia

Auto-TLDR; Tiny Object Detection in Aerial Images Using Multiple Center Points Based Learning Network
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Accurate Cell Segmentation in Digital Pathology Images Via Attention Enforced Networks
Zeyi Yao, Kaiqi Li, Guanhong Zhang, Yiwen Luo, Xiaoguang Zhou, Muyi Sun

Auto-TLDR; AENet: Attention Enforced Network for Automatic Cell Segmentation
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
Do Not Treat Boundaries and Regions Differently: An Example on Heart Left Atrial Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; Attention Full Convolutional Network for Atrial Segmentation using ResNet-101 Architecture
MagnifierNet: Learning Efficient Small-Scale Pedestrian Detector towards Multiple Dense Regions
Qi Cheng, Mingqin Chen, Yingjie Wu, Fei Chen, Shiping Lin

Auto-TLDR; MagnifierNet: A Simple but Effective Small-Scale Pedestrian Detection Towards Multiple Dense Regions
Abstract Slides Poster Similar
One-Stage Multi-Task Detector for 3D Cardiac MR Imaging
Weizeng Lu, Xi Jia, Wei Chen, Nicolò Savioli, Antonio De Marvao, Linlin Shen, Declan O'Regan, Jinming Duan

Auto-TLDR; Multi-task Learning for Real-Time, simultaneous landmark location and bounding box detection in 3D space
Abstract Slides Poster Similar
Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Dayang Yu, Rong Zhang, Shan Qin

Auto-TLDR; Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Abstract Slides Poster Similar
Small Object Detection by Generative and Discriminative Learning
Yi Gu, Jie Li, Chentao Wu, Weijia Jia, Jianping Chen

Auto-TLDR; Generative and Discriminative Learning for Small Object Detection
Abstract Slides Poster Similar
DA-RefineNet: Dual-Inputs Attention RefineNet for Whole Slide Image Segmentation
Ziqiang Li, Rentuo Tao, Qianrun Wu, Bin Li

Auto-TLDR; DA-RefineNet: A dual-inputs attention network for whole slide image segmentation
Abstract Slides Poster Similar
Attention Based Multi-Instance Thyroid Cytopathological Diagnosis with Multi-Scale Feature Fusion
Shuhao Qiu, Yao Guo, Chuang Zhu, Wenli Zhou, Huang Chen

Auto-TLDR; A weakly supervised multi-instance learning framework based on attention mechanism with multi-scale feature fusion for thyroid cytopathological diagnosis
Abstract Slides Poster Similar
Mutually Guided Dual-Task Network for Scene Text Detection
Mengbiao Zhao, Wei Feng, Fei Yin, Xu-Yao Zhang, Cheng-Lin Liu

Auto-TLDR; A dual-task network for word-level and line-level text detection
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
Image-Based Table Cell Detection: A New Dataset and an Improved Detection Method
Dafeng Wei, Hongtao Lu, Yi Zhou, Kai Chen

Auto-TLDR; TableCell: A Semi-supervised Dataset for Table-wise Detection and Recognition
Abstract Slides Poster Similar
MTGAN: Mask and Texture-Driven Generative Adversarial Network for Lung Nodule Segmentation
Wei Chen, Qiuli Wang, Kun Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; Mask and Texture-driven Generative Adversarial Network for Lung Nodule Segmentation
Abstract Slides Poster Similar
Semantic Segmentation Refinement Using Entropy and Boundary-guided Monte Carlo Sampling and Directed Regional Search
Zitang Sun, Sei-Ichiro Kamata, Ruojing Wang, Weili Chen

Auto-TLDR; Directed Region Search and Refinement for Semantic Segmentation
Abstract Slides Poster Similar
RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery

Auto-TLDR; RescueNet: End-to-End Building Segmentation and Damage Classification for Humanitarian Aid and Disaster Response
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Enhanced Feature Pyramid Network for Semantic Segmentation
Mucong Ye, Ouyang Jinpeng, Ge Chen, Jing Zhang, Xiaogang Yu

Auto-TLDR; EFPN: Enhanced Feature Pyramid Network for Semantic Segmentation
Abstract Slides Poster Similar
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
Cross-View Relation Networks for Mammogram Mass Detection
Ma Jiechao, Xiang Li, Hongwei Li, Ruixuan Wang, Bjoern Menze, Wei-Shi Zheng

Auto-TLDR; Multi-view Modeling for Mass Detection in Mammogram
Abstract Slides Poster Similar
Semantic Segmentation of Breast Ultrasound Image with Pyramid Fuzzy Uncertainty Reduction and Direction Connectedness Feature
Kuan Huang, Yingtao Zhang, Heng-Da Cheng, Ping Xing, Boyu Zhang

Auto-TLDR; Uncertainty-Based Deep Learning for Breast Ultrasound Image Segmentation
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
Multiscale Attention-Based Prototypical Network for Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; Few-shot Semantic Segmentation with Multiscale Feature Attention
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
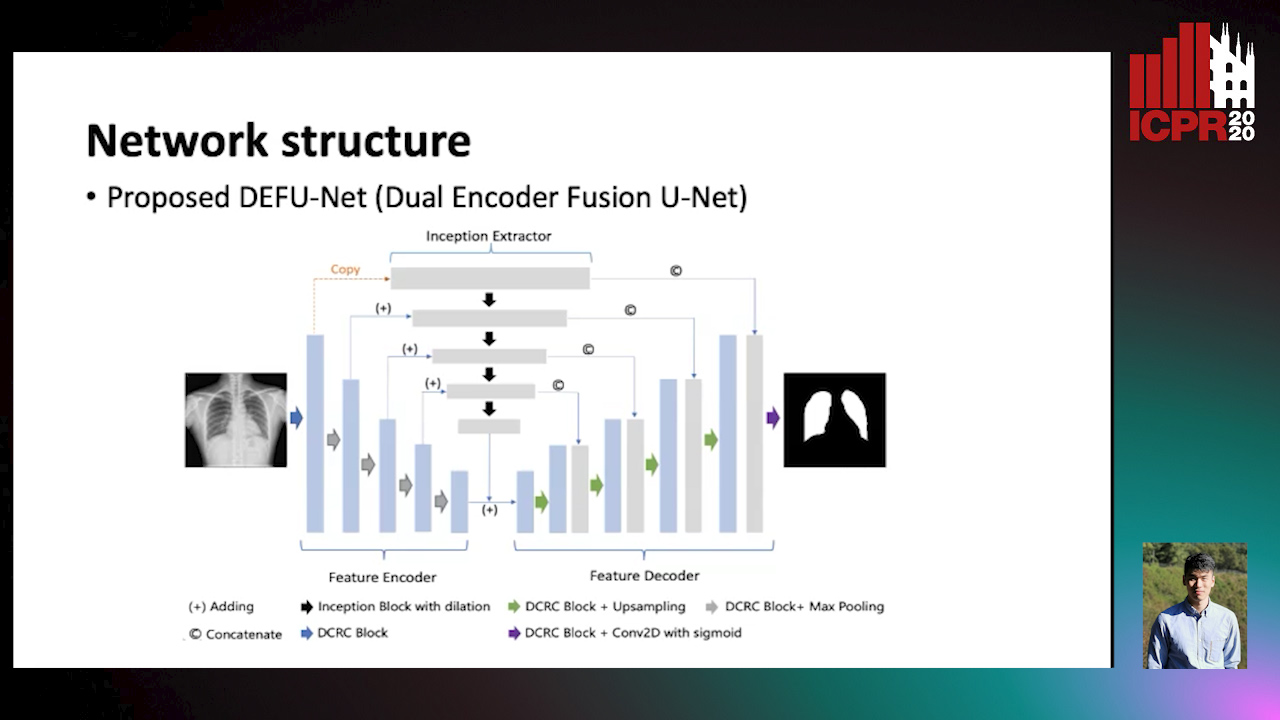
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
UHRSNet: A Semantic Segmentation Network Specifically for Ultra-High-Resolution Images

Auto-TLDR; Ultra-High-Resolution Segmentation with Local and Global Feature Fusion
Learn to Segment Retinal Lesions and Beyond
Qijie Wei, Xirong Li, Weihong Yu, Xiao Zhang, Yongpeng Zhang, Bojie Hu, Bin Mo, Di Gong, Ning Chen, Dayong Ding, Youxin Chen

Auto-TLDR; Multi-task Lesion Segmentation and Disease Classification for Diabetic Retinopathy Grading
Multi-Direction Convolution for Semantic Segmentation
Dehui Li, Zhiguo Cao, Ke Xian, Xinyuan Qi, Chao Zhang, Hao Lu

Auto-TLDR; Multi-Direction Convolution for Contextual Segmentation
Hybrid Cascade Point Search Network for High Precision Bar Chart Component Detection
Junyu Luo, Jinpeng Wang, Chin-Yew Lin

Auto-TLDR; Object Detection of Chart Components in Chart Images Using Point-based and Region-Based Object Detection Framework
Abstract Slides Poster Similar
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
Hierarchical Head Design for Object Detectors
Shivang Agarwal, Frederic Jurie

Auto-TLDR; Hierarchical Anchor for SSD Detector
Abstract Slides Poster Similar