Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang,
Yuncheng Li,
Linjie Yang,
Ning Zhang,
Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
Similar papers
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
StrongPose: Bottom-up and Strong Keypoint Heat Map Based Pose Estimation

Auto-TLDR; StrongPose: A bottom-up box-free approach for human pose estimation and action recognition
Abstract Slides Poster Similar
Orthographic Projection Linear Regression for Single Image 3D Human Pose Estimation
Yahui Zhang, Shaodi You, Theo Gevers

Auto-TLDR; A Deep Neural Network for 3D Human Pose Estimation from a Single 2D Image in the Wild
Abstract Slides Poster Similar
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
Unsupervised 3D Human Pose Estimation in Multi-view-multi-pose Video
Cheng Sun, Diego Thomas, Hiroshi Kawasaki

Auto-TLDR; Unsupervised 3D Human Pose Estimation from 2D Videos Using Generative Adversarial Network
Abstract Slides Poster Similar
Superpixel-Based Refinement for Object Proposal Generation
Christian Wilms, Simone Frintrop

Auto-TLDR; Superpixel-based Refinement of AttentionMask for Object Segmentation
Abstract Slides Poster Similar
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Semantic Segmentation
Zhuoying Wang, Yongtao Wang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin

Auto-TLDR; Gated Scale-Transfer Operation for Semantic Segmentation
Abstract Slides Poster Similar
Motion-Supervised Co-Part Segmentation
Aliaksandr Siarohin, Subhankar Roy, Stéphane Lathuiliere, Sergey Tulyakov, Elisa Ricci, Nicu Sebe

Auto-TLDR; Self-supervised Co-Part Segmentation Using Motion Information from Videos
Tilting at Windmills: Data Augmentation for Deeppose Estimation Does Not Help with Occlusions
Rafal Pytel, Osman Semih Kayhan, Jan Van Gemert

Auto-TLDR; Targeted Keypoint and Body Part Occlusion Attacks for Human Pose Estimation
Abstract Slides Poster Similar
RefiNet: 3D Human Pose Refinement with Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara

Auto-TLDR; RefiNet: A Multi-stage Framework for 3D Human Pose Estimation
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
Learning Object Deformation and Motion Adaption for Semi-Supervised Video Object Segmentation
Xiaoyang Zheng, Xin Tan, Jianming Guo, Lizhuang Ma

Auto-TLDR; Semi-supervised Video Object Segmentation with Mask-propagation-based Model
Abstract Slides Poster Similar
GarmentGAN: Photo-Realistic Adversarial Fashion Transfer
Amir Hossein Raffiee, Michael Sollami

Auto-TLDR; GarmentGAN: A Generative Adversarial Network for Image-Based Garment Transfer
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
Unsupervised Learning of Landmarks Based on Inter-Intra Subject Consistencies
Weijian Li, Haofu Liao, Shun Miao, Le Lu, Jiebo Luo

Auto-TLDR; Unsupervised Learning for Facial Landmark Discovery using Inter-subject Landmark consistencies
Learning Semantic Representations Via Joint 3D Face Reconstruction and Facial Attribute Estimation
Zichun Weng, Youjun Xiang, Xianfeng Li, Juntao Liang, Wanliang Huo, Yuli Fu

Auto-TLDR; Joint Framework for 3D Face Reconstruction with Facial Attribute Estimation
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
Simple Multi-Resolution Representation Learning for Human Pose Estimation
Trung Tran Quang, Van Giang Nguyen, Daeyoung Kim

Auto-TLDR; Multi-resolution Heatmap Learning for Human Pose Estimation
Abstract Slides Poster Similar
Efficient Grouping for Keypoint Detection
Alexey Sidnev, Ekaterina Krasikova, Maxim Kazakov
Auto-TLDR; Automatic Keypoint Grouping for DeepFashion2 Dataset
Abstract Slides Poster Similar
Unsupervised Domain Adaptation with Multiple Domain Discriminators and Adaptive Self-Training
Teo Spadotto, Marco Toldo, Umberto Michieli, Pietro Zanuttigh

Auto-TLDR; Unsupervised Domain Adaptation for Semantic Segmentation of Urban Scenes
Abstract Slides Poster Similar
Light3DPose: Real-Time Multi-Person 3D Pose Estimation from Multiple Views
Alessio Elmi, Davide Mazzini, Pietro Tortella

Auto-TLDR; 3D Pose Estimation of Multiple People from a Few calibrated Camera Views using Deep Learning
Abstract Slides Poster Similar
Enhanced Feature Pyramid Network for Semantic Segmentation
Mucong Ye, Ouyang Jinpeng, Ge Chen, Jing Zhang, Xiaogang Yu

Auto-TLDR; EFPN: Enhanced Feature Pyramid Network for Semantic Segmentation
Abstract Slides Poster Similar
Occlusion-Tolerant and Personalized 3D Human Pose Estimation in RGB Images

Auto-TLDR; Real-Time 3D Human Pose Estimation in BVH using Inverse Kinematics Solver and Neural Networks
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Multiscale Attention-Based Prototypical Network for Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; Few-shot Semantic Segmentation with Multiscale Feature Attention
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Pierfrancesco Ardino, Yahui Liu, Elisa Ricci, Bruno Lepri, Marco De Nadai

Auto-TLDR; Semantic-Guided Inpainting of Complex Urban Scene Using Semantic Segmentation and Generation
Abstract Slides Poster Similar
Efficient High-Resolution High-Level-Semantic Representation Learning for Human Pose Estimation

Auto-TLDR; Spatial enhanced separated temporal spatial convolutional neural network
Abstract Slides Poster Similar
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
CASNet: Common Attribute Support Network for Image Instance and Panoptic Segmentation
Xiaolong Liu, Yuqing Hou, Anbang Yao, Yurong Chen, Keqiang Li

Auto-TLDR; Common Attribute Support Network for instance segmentation and panoptic segmentation
Abstract Slides Poster Similar
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar
Self-Training for Domain Adaptive Scene Text Detection
Yudi Chen, Wei Wang, Yu Zhou, Fei Yang, Dongbao Yang, Weiping Wang

Auto-TLDR; A self-training framework for image-based scene text detection
End-To-End Hierarchical Relation Extraction for Generic Form Understanding
Tuan Anh Nguyen Dang, Duc-Thanh Hoang, Quang Bach Tran, Chih-Wei Pan, Thanh-Dat Nguyen

Auto-TLDR; Joint Entity Labeling and Link Prediction for Form Understanding in Noisy Scanned Documents
Abstract Slides Poster Similar
On the Robustness of 3D Human Pose Estimation
Zerui Chen, Yan Huang, Liang Wang

Auto-TLDR; Robustness of 3D Human Pose Estimation Methods to Adversarial Attacks
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Semantic Segmentation Refinement Using Entropy and Boundary-guided Monte Carlo Sampling and Directed Regional Search
Zitang Sun, Sei-Ichiro Kamata, Ruojing Wang, Weili Chen

Auto-TLDR; Directed Region Search and Refinement for Semantic Segmentation
Abstract Slides Poster Similar
Joint Face Alignment and 3D Face Reconstruction with Efficient Convolution Neural Networks
Keqiang Li, Huaiyu Wu, Xiuqin Shang, Zhen Shen, Gang Xiong, Xisong Dong, Bin Hu, Fei-Yue Wang

Auto-TLDR; Mobile-FRNet: Efficient 3D Morphable Model Alignment and 3D Face Reconstruction from a Single 2D Facial Image
Abstract Slides Poster Similar
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
Towards Efficient 3D Point Cloud Scene Completion Via Novel Depth View Synthesis
Haiyan Wang, Liang Yang, Xuejian Rong, Ying-Li Tian

Auto-TLDR; 3D Point Cloud Completion with Depth View Synthesis and Depth View synthesis
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
P2 Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Luanxuan Hou, Jie Cao, Yuan Zhao, Haifeng Shen, Jian Tang, Ran He

Auto-TLDR; Parallel-Pyramid Net with Partial Attention for Human Pose Estimation
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
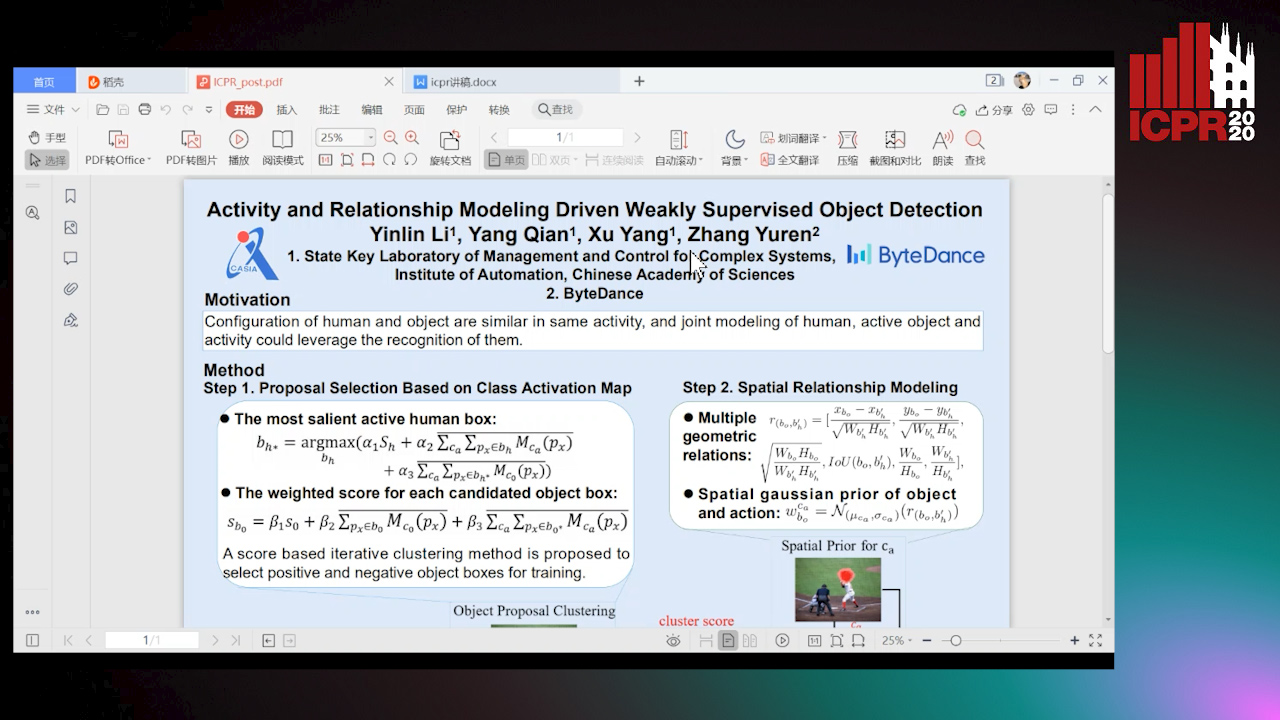
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
Semantic Object Segmentation in Cultural Sites Using Real and Synthetic Data
Francesco Ragusa, Daniele Di Mauro, Alfio Palermo, Antonino Furnari, Giovanni Maria Farinella

Auto-TLDR; Exploiting Synthetic Data for Object Segmentation in Cultural Sites
Abstract Slides Poster Similar
Learning to Implicitly Represent 3D Human Body from Multi-Scale Features and Multi-View Images
Zhongguo Li, Magnus Oskarsson, Anders Heyden

Auto-TLDR; Reconstruction of 3D human bodies from multi-view images using multi-stage end-to-end neural networks
Abstract Slides Poster Similar