Text Recognition - Real World Data and Where to Find Them
Klára Janoušková,
Lluis Gomez,
Dimosthenis Karatzas,
Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Similar papers
ReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Qi Song, Qianyi Jiang, Xiaolin Wei, Nan Li, Rui Zhang

Auto-TLDR; ReADS: Rectified Attentional Double Supervised Network for General Scene Text Recognition
Abstract Slides Poster Similar
Weakly Supervised Attention Rectification for Scene Text Recognition
Chengyu Gu, Shilin Wang, Yiwei Zhu, Zheng Huang, Kai Chen

Auto-TLDR; An auxiliary supervision branch for attention-based scene text recognition
Abstract Slides Poster Similar
Stratified Multi-Task Learning for Robust Spotting of Scene Texts
Kinjal Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; Feature Representation Block for Multi-task Learning of Scene Text
MEAN: A Multi-Element Attention Based Network for Scene Text Recognition
Ruijie Yan, Liangrui Peng, Shanyu Xiao, Gang Yao, Jaesik Min

Auto-TLDR; Multi-element Attention Network for Scene Text Recognition
Abstract Slides Poster Similar
Self-Training for Domain Adaptive Scene Text Detection
Yudi Chen, Wei Wang, Yu Zhou, Fei Yang, Dongbao Yang, Weiping Wang

Auto-TLDR; A self-training framework for image-based scene text detection
Gaussian Constrained Attention Network for Scene Text Recognition
Zhi Qiao, Xugong Qin, Yu Zhou, Fei Yang, Weiping Wang

Auto-TLDR; Gaussian Constrained Attention Network for Scene Text Recognition
Abstract Slides Poster Similar
Recognizing Multiple Text Sequences from an Image by Pure End-To-End Learning
Zhenlong Xu, Shuigeng Zhou, Fan Bai, Cheng Zhanzhan, Yi Niu, Shiliang Pu

Auto-TLDR; Pure End-to-End Learning for Multiple Text Sequences Recognition from Images
Abstract Slides Poster Similar
Text Recognition in Real Scenarios with a Few Labeled Samples
Jinghuang Lin, Cheng Zhanzhan, Fan Bai, Yi Niu, Shiliang Pu, Shuigeng Zhou

Auto-TLDR; Few-shot Adversarial Sequence Domain Adaptation for Scene Text Recognition
Abstract Slides Poster Similar
IBN-STR: A Robust Text Recognizer for Irregular Text in Natural Scenes
Xiaoqian Li, Jie Liu, Shuwu Zhang

Auto-TLDR; IBN-STR: A Robust Text Recognition System Based on Data and Feature Representation
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Eun-Soo Jung, Hyeonggwan Son, Kyusam Oh, Yongkeun Yun, Soonhwan Kwon, Min Soo Kim

Auto-TLDR; Text Detection for Document Images Using Synthetic and Real Data
Abstract Slides Poster Similar
A Multi-Head Self-Relation Network for Scene Text Recognition
Zhou Junwei, Hongchao Gao, Jiao Dai, Dongqin Liu, Jizhong Han

Auto-TLDR; Multi-head Self-relation Network for Scene Text Recognition
Abstract Slides Poster Similar
Cost-Effective Adversarial Attacks against Scene Text Recognition
Mingkun Yang, Haitian Zheng, Xiang Bai, Jiebo Luo

Auto-TLDR; Adversarial Attacks on Scene Text Recognition
Abstract Slides Poster Similar
Robust Lexicon-Free Confidence Prediction for Text Recognition
Qi Song, Qianyi Jiang, Rui Zhang, Xiaolin Wei

Auto-TLDR; Confidence Measurement for Optical Character Recognition using Single-Input Multi-Output Network
Abstract Slides Poster Similar
2D License Plate Recognition based on Automatic Perspective Rectification
Hui Xu, Zhao-Hong Guo, Da-Han Wang, Xiang-Dong Zhou, Yu Shi

Auto-TLDR; Perspective Rectification Network for License Plate Recognition
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
Sample-Aware Data Augmentor for Scene Text Recognition
Guanghao Meng, Tao Dai, Shudeng Wu, Bin Chen, Jian Lu, Yong Jiang, Shutao Xia

Auto-TLDR; Sample-Aware Data Augmentation for Scene Text Recognition
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
Cross-Lingual Text Image Recognition Via Multi-Task Sequence to Sequence Learning
Zhuo Chen, Fei Yin, Xu-Yao Zhang, Qing Yang, Cheng-Lin Liu

Auto-TLDR; Cross-Lingual Text Image Recognition with Multi-task Learning
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
Local Gradient Difference Based Mass Features for Classification of 2D-3D Natural Scene Text Images
Lokesh Nandanwar, Shivakumara Palaiahnakote, Raghavendra Ramachandra, Tong Lu, Umapada Pal, Daniel Lopresti, Nor Badrul Anuar
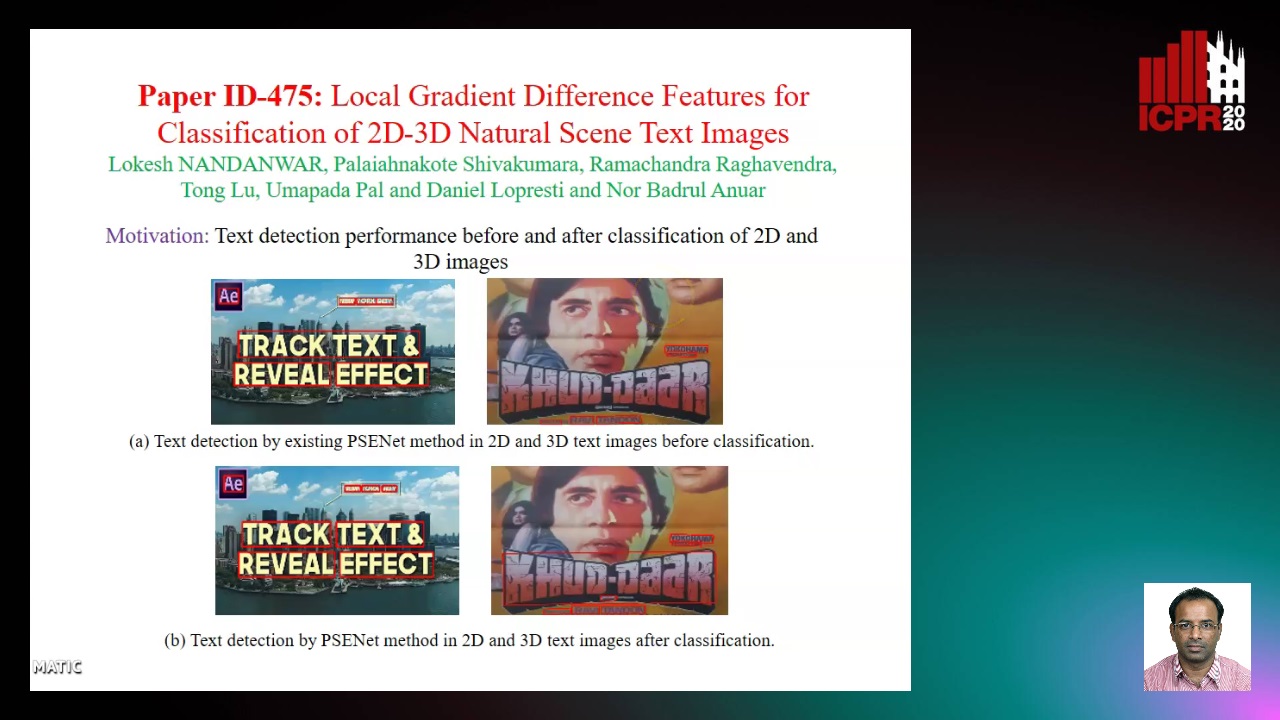
Auto-TLDR; Classification of 2D and 3D Natural Scene Images Using COLD
Abstract Slides Poster Similar
An Accurate Threshold Insensitive Kernel Detector for Arbitrary Shaped Text
Xijun Qian, Yifan Liu, Yu-Bin Yang

Auto-TLDR; TIKD: threshold insensitive kernel detector for arbitrary shaped text
Label or Message: A Large-Scale Experimental Survey of Texts and Objects Co-Occurrence
Koki Takeshita, Juntaro Shioyama, Seiichi Uchida

Auto-TLDR; Large-scale Survey of Co-occurrence between Objects and Scene Text with a State-of-the-art Scene Text detector and Recognizer
A Few-Shot Learning Approach for Historical Ciphered Manuscript Recognition
Mohamed Ali Souibgui, Alicia Fornés, Yousri Kessentini, Crina Tudor

Auto-TLDR; Handwritten Ciphers Recognition Using Few-Shot Object Detection
The HisClima Database: Historical Weather Logs for Automatic Transcription and Information Extraction
Verónica Romero, Joan Andreu Sánchez

Auto-TLDR; Automatic Handwritten Text Recognition and Information Extraction from Historical Weather Logs
Abstract Slides Poster Similar
Improving Word Recognition Using Multiple Hypotheses and Deep Embeddings
Siddhant Bansal, Praveen Krishnan, C. V. Jawahar

Auto-TLDR; EmbedNet: fuse recognition-based and recognition-free approaches for word recognition using learning-based methods
Abstract Slides Poster Similar
A Fast and Accurate Object Detector for Handwritten Digit String Recognition
Jun Guo, Wenjing Wei, Yifeng Ma, Cong Peng

Auto-TLDR; ChipNet: An anchor-free object detector for handwritten digit string recognition
Abstract Slides Poster Similar
Mutually Guided Dual-Task Network for Scene Text Detection
Mengbiao Zhao, Wei Feng, Fei Yin, Xu-Yao Zhang, Cheng-Lin Liu

Auto-TLDR; A dual-task network for word-level and line-level text detection
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
TGCRBNW: A Dataset for Runner Bib Number Detection (and Recognition) in the Wild
Pablo Hernández-Carrascosa, Adrian Penate-Sanchez, Javier Lorenzo, David Freire Obregón, Modesto Castrillon

Auto-TLDR; Racing Bib Number Detection and Recognition in the Wild Using Faster R-CNN
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
TCATD: Text Contour Attention for Scene Text Detection
Ziling Hu, Wu Xingjiao, Jing Yang

Auto-TLDR; Text Contour Attention Text Detector
Abstract Slides Poster Similar
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Transferable Adversarial Attacks for Deep Scene Text Detection
Shudeng Wu, Tao Dai, Guanghao Meng, Bin Chen, Jian Lu, Shutao Xia

Auto-TLDR; Robustness of DNN-based STD methods against Adversarial Attacks
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Fusion of Global-Local Features for Image Quality Inspection of Shipping Label
Sungho Suh, Paul Lukowicz, Yong Oh Lee

Auto-TLDR; Input Image Quality Verification for Automated Shipping Address Recognition and Verification
Abstract Slides Poster Similar
The DeepScoresV2 Dataset and Benchmark for Music Object Detection
Lukas Tuggener, Yvan Putra Satyawan, Alexander Pacha, Jürgen Schmidhuber, Thilo Stadelmann

Auto-TLDR; DeepScoresV2: an extended version of the DeepScores dataset for optical music recognition
Abstract Slides Poster Similar
PICK: Processing Key Information Extraction from Documents Using Improved Graph Learning-Convolutional Networks
Wenwen Yu, Ning Lu, Xianbiao Qi, Ping Gong, Rong Xiao

Auto-TLDR; PICK: A Graph Learning Framework for Key Information Extraction from Documents
Abstract Slides Poster Similar
Unsupervised Domain Adaptation with Multiple Domain Discriminators and Adaptive Self-Training
Teo Spadotto, Marco Toldo, Umberto Michieli, Pietro Zanuttigh

Auto-TLDR; Unsupervised Domain Adaptation for Semantic Segmentation of Urban Scenes
Abstract Slides Poster Similar
A Transformer-Based Radical Analysis Network for Chinese Character Recognition
Chen Yang, Qing Wang, Jun Du, Jianshu Zhang, Changjie Wu, Jiaming Wang

Auto-TLDR; Transformer-based Radical Analysis Network for Chinese Character Recognition
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
Fast Approximate Modelling of the Next Combination Result for Stopping the Text Recognition in a Video
Konstantin Bulatov, Nadezhda Fedotova, Vladimir V. Arlazarov

Auto-TLDR; Stopping Video Stream Recognition of a Text Field Using Optimized Computation Scheme
Abstract Slides Poster Similar
Segmenting Messy Text: Detecting Boundaries in Text Derived from Historical Newspaper Images

Auto-TLDR; Text Segmentation of Marriage Announcements Using Deep Learning-based Models
Abstract Slides Poster Similar
EAGLE: Large-Scale Vehicle Detection Dataset in Real-World Scenarios Using Aerial Imagery
Seyed Majid Azimi, Reza Bahmanyar, Corentin Henry, Kurz Franz

Auto-TLDR; EAGLE: A Large-Scale Dataset for Multi-class Vehicle Detection with Object Orientation Information in Airborne Imagery
Recognizing Bengali Word Images - A Zero-Shot Learning Perspective
Sukalpa Chanda, Daniël Arjen Willem Haitink, Prashant Kumar Prasad, Jochem Baas, Umapada Pal, Lambert Schomaker

Auto-TLDR; Zero-Shot Learning for Word Recognition in Bengali Script
Abstract Slides Poster Similar
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
An Integrated Approach of Deep Learning and Symbolic Analysis for Digital PDF Table Extraction
Mengshi Zhang, Daniel Perelman, Vu Le, Sumit Gulwani

Auto-TLDR; Deep Learning and Symbolic Reasoning for Unstructured PDF Table Extraction
Abstract Slides Poster Similar