Recognizing Bengali Word Images - A Zero-Shot Learning Perspective
Sukalpa Chanda,
Daniël Arjen Willem Haitink,
Prashant Kumar Prasad,
Jochem Baas,
Umapada Pal,
Lambert Schomaker

Auto-TLDR; Zero-Shot Learning for Word Recognition in Bengali Script
Similar papers
Prior Knowledge about Attributes: Learning a More Effective Potential Space for Zero-Shot Recognition

Auto-TLDR; Attribute Correlation Potential Space Generation for Zero-Shot Learning
Abstract Slides Poster Similar
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
A Few-Shot Learning Approach for Historical Ciphered Manuscript Recognition
Mohamed Ali Souibgui, Alicia Fornés, Yousri Kessentini, Crina Tudor

Auto-TLDR; Handwritten Ciphers Recognition Using Few-Shot Object Detection
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
Improving Word Recognition Using Multiple Hypotheses and Deep Embeddings
Siddhant Bansal, Praveen Krishnan, C. V. Jawahar

Auto-TLDR; EmbedNet: fuse recognition-based and recognition-free approaches for word recognition using learning-based methods
Abstract Slides Poster Similar
Heterogeneous Graph-Based Knowledge Transfer for Generalized Zero-Shot Learning
Junjie Wang, Xiangfeng Wang, Bo Jin, Junchi Yan, Wenjie Zhang, Hongyuan Zha

Auto-TLDR; Heterogeneous Graph-based Knowledge Transfer for Generalized Zero-Shot Learning
Abstract Slides Poster Similar
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Multi-Attribute Learning with Highly Imbalanced Data
Lady Viviana Beltran Beltran, Mickaël Coustaty, Nicholas Journet, Juan C. Caicedo, Antoine Doucet

Auto-TLDR; Data Imbalance in Multi-Attribute Deep Learning Models: Adaptation to face each one of the problems derived from imbalance
Abstract Slides Poster Similar
Textual-Content Based Classification of Bundles of Untranscribed of Manuscript Images
José Ramón Prieto Fontcuberta, Enrique Vidal, Vicente Bosch, Carlos Alonso, Carmen Orcero, Lourdes Márquez

Auto-TLDR; Probabilistic Indexing for Text-based Classification of Manuscripts
Abstract Slides Poster Similar
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Chebyshev-Harmonic-Fourier-Moments and Deep CNNs for Detecting Forged Handwriting
Lokesh Nandanwar, Shivakumara Palaiahnakote, Kundu Sayani, Umapada Pal, Tong Lu, Daniel Lopresti

Auto-TLDR; Chebyshev-Harmonic-Fourier-Moments and Deep Convolutional Neural Networks for forged handwriting detection
Abstract Slides Poster Similar
GuCNet: A Guided Clustering-Based Network for Improved Classification
Ushasi Chaudhuri, Syomantak Chaudhuri, Subhasis Chaudhuri

Auto-TLDR; Semantic Classification of Challenging Dataset Using Guide Datasets
Abstract Slides Poster Similar
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar
The HisClima Database: Historical Weather Logs for Automatic Transcription and Information Extraction
Verónica Romero, Joan Andreu Sánchez

Auto-TLDR; Automatic Handwritten Text Recognition and Information Extraction from Historical Weather Logs
Abstract Slides Poster Similar
Generalized Local Attention Pooling for Deep Metric Learning
Carlos Roig Mari, David Varas, Issey Masuda, Juan Carlos Riveiro, Elisenda Bou-Balust

Auto-TLDR; Generalized Local Attention Pooling for Deep Metric Learning
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar
A Multi-Head Self-Relation Network for Scene Text Recognition
Zhou Junwei, Hongchao Gao, Jiao Dai, Dongqin Liu, Jizhong Han

Auto-TLDR; Multi-head Self-relation Network for Scene Text Recognition
Abstract Slides Poster Similar
Online Trajectory Recovery from Offline Handwritten Japanese Kanji Characters of Multiple Strokes
Hung Tuan Nguyen, Tsubasa Nakamura, Cuong Tuan Nguyen, Masaki Nakagawa

Auto-TLDR; Recovering Dynamic Online Trajectories from Offline Japanese Kanji Character Images for Handwritten Character Recognition
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
PICK: Processing Key Information Extraction from Documents Using Improved Graph Learning-Convolutional Networks
Wenwen Yu, Ning Lu, Xianbiao Qi, Ping Gong, Rong Xiao

Auto-TLDR; PICK: A Graph Learning Framework for Key Information Extraction from Documents
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
A Transformer-Based Radical Analysis Network for Chinese Character Recognition
Chen Yang, Qing Wang, Jun Du, Jianshu Zhang, Changjie Wu, Jiaming Wang

Auto-TLDR; Transformer-based Radical Analysis Network for Chinese Character Recognition
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Parallel Network to Learn Novelty from the Known
Shuaiyuan Du, Chaoyi Hong, Zhiyu Pan, Chen Feng, Zhiguo Cao
Auto-TLDR; Trainable Parallel Network for Pseudo-Novel Detection
Abstract Slides Poster Similar
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar
Learning to Sort Handwritten Text Lines in Reading Order through Estimated Binary Order Relations

Auto-TLDR; Automatic Reading Order of Text Lines in Handwritten Text Documents
An Evaluation of DNN Architectures for Page Segmentation of Historical Newspapers
Manuel Burghardt, Bernhard Liebl

Auto-TLDR; Evaluation of Backbone Architectures for Optical Character Segmentation of Historical Documents
Abstract Slides Poster Similar
Local Gradient Difference Based Mass Features for Classification of 2D-3D Natural Scene Text Images
Lokesh Nandanwar, Shivakumara Palaiahnakote, Raghavendra Ramachandra, Tong Lu, Umapada Pal, Daniel Lopresti, Nor Badrul Anuar
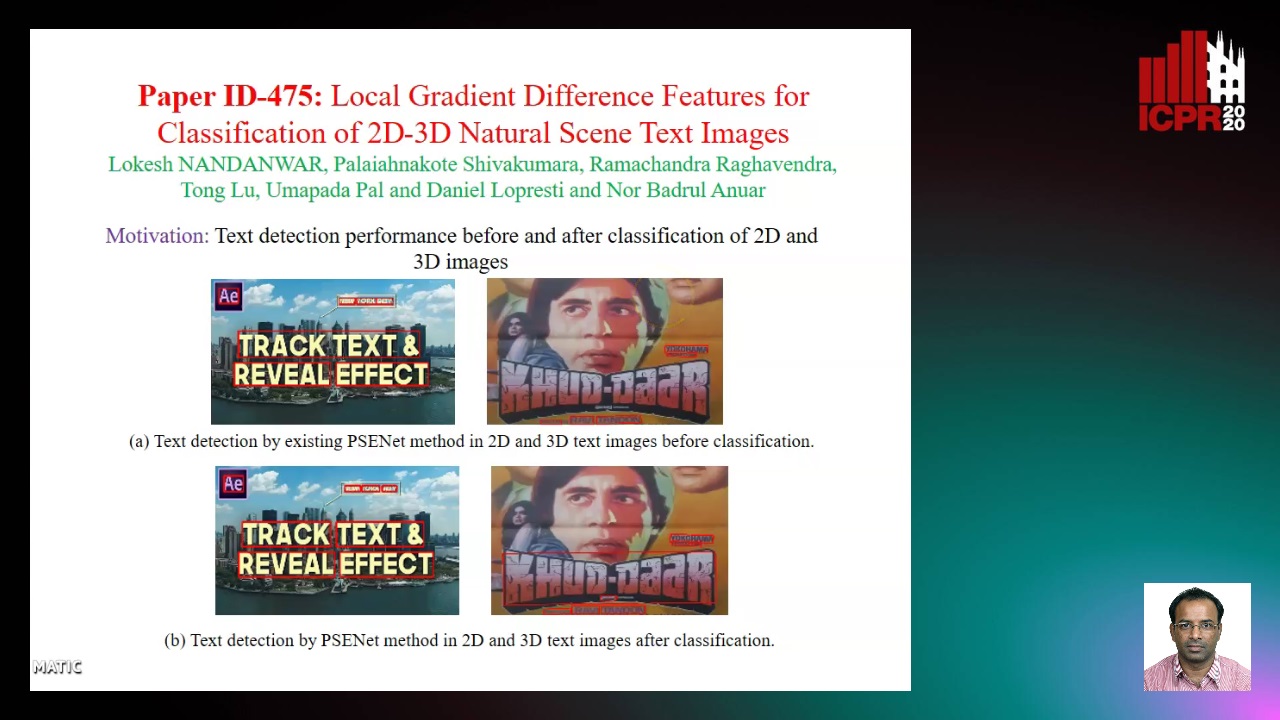
Auto-TLDR; Classification of 2D and 3D Natural Scene Images Using COLD
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Open Set Domain Recognition Via Attention-Based GCN and Semantic Matching Optimization
Xinxing He, Yuan Yuan, Zhiyu Jiang

Auto-TLDR; Attention-based GCN and Semantic Matching Optimization for Open Set Domain Recognition
Abstract Slides Poster Similar
A Fast and Accurate Object Detector for Handwritten Digit String Recognition
Jun Guo, Wenjing Wei, Yifeng Ma, Cong Peng

Auto-TLDR; ChipNet: An anchor-free object detector for handwritten digit string recognition
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
Concept Embedding through Canonical Forms: A Case Study on Zero-Shot ASL Recognition
Azamat Kamzin, Apurupa Amperyani, Prasanth Sukhapalli, Ayan Banerjee, Sandeep Gupta

Auto-TLDR; A canonical form of gestures in American Sign Language
Abstract Slides Poster Similar
Directed Variational Cross-encoder Network for Few-Shot Multi-image Co-segmentation
Sayan Banerjee, Divakar Bhat S, Subhasis Chaudhuri, Rajbabu Velmurugan

Auto-TLDR; Directed Variational Inference Cross Encoder for Class Agnostic Co-Segmentation of Multiple Images
Abstract Slides Poster Similar
Generative Latent Implicit Conditional Optimization When Learning from Small Sample

Auto-TLDR; GLICO: Generative Latent Implicit Conditional Optimization for Small Sample Learning
Abstract Slides Poster Similar
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
Vision-Based Layout Detection from Scientific Literature Using Recurrent Convolutional Neural Networks

Auto-TLDR; Transfer Learning for Scientific Literature Layout Detection Using Convolutional Neural Networks
Abstract Slides Poster Similar
Rethinking of Deep Models Parameters with Respect to Data Distribution
Shitala Prasad, Dongyun Lin, Yiqun Li, Sheng Dong, Zaw Min Oo

Auto-TLDR; A progressive stepwise training strategy for deep neural networks
Abstract Slides Poster Similar
A Close Look at Deep Learning with Small Data

Auto-TLDR; Low-Complex Neural Networks for Small Data Conditions
Abstract Slides Poster Similar
Human or Machine? It Is Not What You Write, but How You Write It
Luis Leiva, Moises Diaz, M.A. Ferrer, Réjean Plamondon

Auto-TLDR; Behavioral Biometrics via Handwritten Symbols for Identification and Verification
Abstract Slides Poster Similar
ReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Qi Song, Qianyi Jiang, Xiaolin Wei, Nan Li, Rui Zhang

Auto-TLDR; ReADS: Rectified Attentional Double Supervised Network for General Scene Text Recognition
Abstract Slides Poster Similar
Text Baseline Recognition Using a Recurrent Convolutional Neural Network
Matthias Wödlinger, Robert Sablatnig

Auto-TLDR; Automatic Baseline Detection of Handwritten Text Using Recurrent Convolutional Neural Network
Abstract Slides Poster Similar
MetaMix: Improved Meta-Learning with Interpolation-based Consistency Regularization
Yangbin Chen, Yun Ma, Tom Ko, Jianping Wang, Qing Li

Auto-TLDR; MetaMix: A Meta-Agnostic Meta-Learning Algorithm for Few-Shot Classification
Abstract Slides Poster Similar
Stratified Multi-Task Learning for Robust Spotting of Scene Texts
Kinjal Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; Feature Representation Block for Multi-task Learning of Scene Text
Incrementally Zero-Shot Detection by an Extreme Value Analyzer
Sixiao Zheng, Yanwei Fu, Yanxi Hou

Auto-TLDR; IZSD-EVer: Incremental Zero-Shot Detection for Incremental Learning