A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu,
Yujia Zhang,
Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Similar papers
Heterogeneous Graph-Based Knowledge Transfer for Generalized Zero-Shot Learning
Junjie Wang, Xiangfeng Wang, Bo Jin, Junchi Yan, Wenjie Zhang, Hongyuan Zha

Auto-TLDR; Heterogeneous Graph-based Knowledge Transfer for Generalized Zero-Shot Learning
Abstract Slides Poster Similar
Prior Knowledge about Attributes: Learning a More Effective Potential Space for Zero-Shot Recognition

Auto-TLDR; Attribute Correlation Potential Space Generation for Zero-Shot Learning
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Incrementally Zero-Shot Detection by an Extreme Value Analyzer
Sixiao Zheng, Yanwei Fu, Yanxi Hou

Auto-TLDR; IZSD-EVer: Incremental Zero-Shot Detection for Incremental Learning
Concept Embedding through Canonical Forms: A Case Study on Zero-Shot ASL Recognition
Azamat Kamzin, Apurupa Amperyani, Prasanth Sukhapalli, Ayan Banerjee, Sandeep Gupta

Auto-TLDR; A canonical form of gestures in American Sign Language
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
Parallel Network to Learn Novelty from the Known
Shuaiyuan Du, Chaoyi Hong, Zhiyu Pan, Chen Feng, Zhiguo Cao
Auto-TLDR; Trainable Parallel Network for Pseudo-Novel Detection
Abstract Slides Poster Similar
Recognizing Bengali Word Images - A Zero-Shot Learning Perspective
Sukalpa Chanda, Daniël Arjen Willem Haitink, Prashant Kumar Prasad, Jochem Baas, Umapada Pal, Lambert Schomaker

Auto-TLDR; Zero-Shot Learning for Word Recognition in Bengali Script
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
TAAN: Task-Aware Attention Network for Few-Shot Classification

Auto-TLDR; TAAN: Task-Aware Attention Network for Few-Shot Classification
Abstract Slides Poster Similar
Open Set Domain Recognition Via Attention-Based GCN and Semantic Matching Optimization
Xinxing He, Yuan Yuan, Zhiyu Jiang

Auto-TLDR; Attention-based GCN and Semantic Matching Optimization for Open Set Domain Recognition
Abstract Slides Poster Similar
Complementing Representation Deficiency in Few-Shot Image Classification: A Meta-Learning Approach
Xian Zhong, Cheng Gu, Wenxin Huang, Lin Li, Shuqin Chen, Chia-Wen Lin

Auto-TLDR; Meta-learning with Complementary Representations Network for Few-Shot Learning
Abstract Slides Poster Similar
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
Pose-Robust Face Recognition by Deep Meta Capsule Network-Based Equivariant Embedding
Fangyu Wu, Jeremy Simon Smith, Wenjin Lu, Bailing Zhang

Auto-TLDR; Deep Meta Capsule Network-based Equivariant Embedding Model for Pose-Robust Face Recognition
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
Continuous Sign Language Recognition with Iterative Spatiotemporal Fine-Tuning
Kenessary Koishybay, Medet Mukushev, Anara Sandygulova

Auto-TLDR; A Deep Neural Network for Continuous Sign Language Recognition with Iterative Gloss Recognition
Abstract Slides Poster Similar
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
Facial Expression Recognition by Using a Disentangled Identity-Invariant Expression Representation

Auto-TLDR; Transfer-based Expression Recognition Generative Adversarial Network (TER-GAN)
Abstract Slides Poster Similar
Self-Supervised Learning of Dynamic Representations for Static Images
Siyang Song, Enrique Sanchez, Linlin Shen, Michel Valstar

Auto-TLDR; Facial Action Unit Intensity Estimation and Affect Estimation from Still Images with Multiple Temporal Scale
Abstract Slides Poster Similar
Identity-Aware Facial Expression Recognition in Compressed Video
Xiaofeng Liu, Linghao Jin, Xu Han, Jun Lu, Jonghye Woo, Jane You

Auto-TLDR; Exploring Facial Expression Representation in Compressed Video with Mutual Information Minimization
Cross-Lingual Text Image Recognition Via Multi-Task Sequence to Sequence Learning
Zhuo Chen, Fei Yin, Xu-Yao Zhang, Qing Yang, Cheng-Lin Liu

Auto-TLDR; Cross-Lingual Text Image Recognition with Multi-task Learning
Abstract Slides Poster Similar
Attentive Hybrid Feature Based a Two-Step Fusion for Facial Expression Recognition
Jun Weng, Yang Yang, Zichang Tan, Zhen Lei

Auto-TLDR; Attentive Hybrid Architecture for Facial Expression Recognition
Abstract Slides Poster Similar
Multi-Label Contrastive Focal Loss for Pedestrian Attribute Recognition
Xiaoqiang Zheng, Zhenxia Yu, Lin Chen, Fan Zhu, Shilong Wang

Auto-TLDR; Multi-label Contrastive Focal Loss for Pedestrian Attribute Recognition
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
GuCNet: A Guided Clustering-Based Network for Improved Classification
Ushasi Chaudhuri, Syomantak Chaudhuri, Subhasis Chaudhuri

Auto-TLDR; Semantic Classification of Challenging Dataset Using Guide Datasets
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
Incorporating Depth Information into Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; RDNet: A Deep Neural Network for Few-shot Segmentation Using Depth Information
Abstract Slides Poster Similar
2D Deep Video Capsule Network with Temporal Shift for Action Recognition
Théo Voillemin, Hazem Wannous, Jean-Philippe Vandeborre

Auto-TLDR; Temporal Shift Module over Capsule Network for Action Recognition in Continuous Videos
Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar, Mourad Oussalah, Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Learning Disentangled Representations for Identity Preserving Surveillance Face Camouflage
Jingzhi Li, Lutong Han, Hua Zhang, Xiaoguang Han, Jingguo Ge, Xiaochu Cao

Auto-TLDR; Individual Face Privacy under Surveillance Scenario with Multi-task Loss Function
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
End-To-End Triplet Loss Based Emotion Embedding System for Speech Emotion Recognition
Puneet Kumar, Sidharth Jain, Balasubramanian Raman, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; End-to-End Neural Embedding System for Speech Emotion Recognition
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Directed Variational Cross-encoder Network for Few-Shot Multi-image Co-segmentation
Sayan Banerjee, Divakar Bhat S, Subhasis Chaudhuri, Rajbabu Velmurugan

Auto-TLDR; Directed Variational Inference Cross Encoder for Class Agnostic Co-Segmentation of Multiple Images
Abstract Slides Poster Similar
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Learning Natural Thresholds for Image Ranking
Somayeh Keshavarz, Quang Nhat Tran, Richard Souvenir

Auto-TLDR; Image Representation Learning and Label Discretization for Natural Image Ranking
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Deep Multi-Task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Rui Zhao, Tianshan Liu, Jun Xiao, P. K. Daniel Lun, Kin-Man Lam

Auto-TLDR; Multi-task Learning for Facial Expression Recognition and Synthesis
Abstract Slides Poster Similar
Visual Oriented Encoder: Integrating Multimodal and Multi-Scale Contexts for Video Captioning

Auto-TLDR; Visual Oriented Encoder for Video Captioning
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
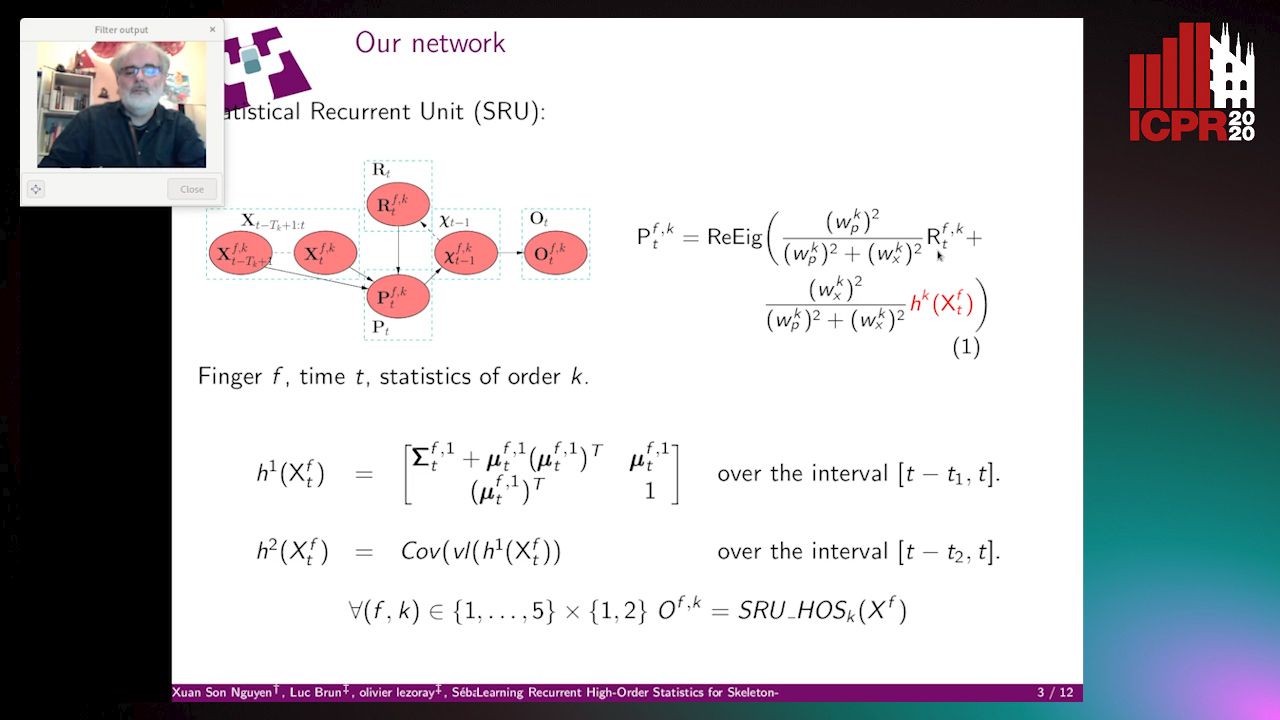
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition