Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar,
Mourad Oussalah,
Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Similar papers
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
DeepPear: Deep Pose Estimation and Action Recognition
Wen-Jiin Tsai, You-Ying Jhuang

Auto-TLDR; Human Action Recognition Using RGB Video Using 3D Human Pose and Appearance Features
Abstract Slides Poster Similar
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Negar Heidari, Alexandros Iosifidis

Auto-TLDR; Temporal Attention Module for Efficient Graph Convolutional Network-based Action Recognition
Abstract Slides Poster Similar
JT-MGCN: Joint-Temporal Motion Graph Convolutional Network for Skeleton-Based Action Recognition

Auto-TLDR; Joint-temporal Motion Graph Convolutional Networks for Action Recognition
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
Vertex Feature Encoding and Hierarchical Temporal Modeling in a Spatio-Temporal Graph Convolutional Network for Action Recognition
Konstantinos Papadopoulos, Enjie Ghorbel, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Spatio-Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
Abstract Slides Poster Similar
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
Channel-Wise Dense Connection Graph Convolutional Network for Skeleton-Based Action Recognition
Michael Lao Banteng, Zhiyong Wu

Auto-TLDR; Two-stream channel-wise dense connection GCN for human action recognition
Abstract Slides Poster Similar
Recurrent Graph Convolutional Networks for Skeleton-Based Action Recognition
Guangming Zhu, Lu Yang, Liang Zhang, Peiyi Shen, Juan Song

Auto-TLDR; Recurrent Graph Convolutional Network for Human Action Recognition
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar
Temporal Extension Module for Skeleton-Based Action Recognition

Auto-TLDR; Extended Temporal Graph for Action Recognition with Kinetics-Skeleton
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
Feature-Supervised Action Modality Transfer
Fida Mohammad Thoker, Cees Snoek

Auto-TLDR; Cross-Modal Action Recognition and Detection in Non-RGB Video Modalities by Learning from Large-Scale Labeled RGB Data
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
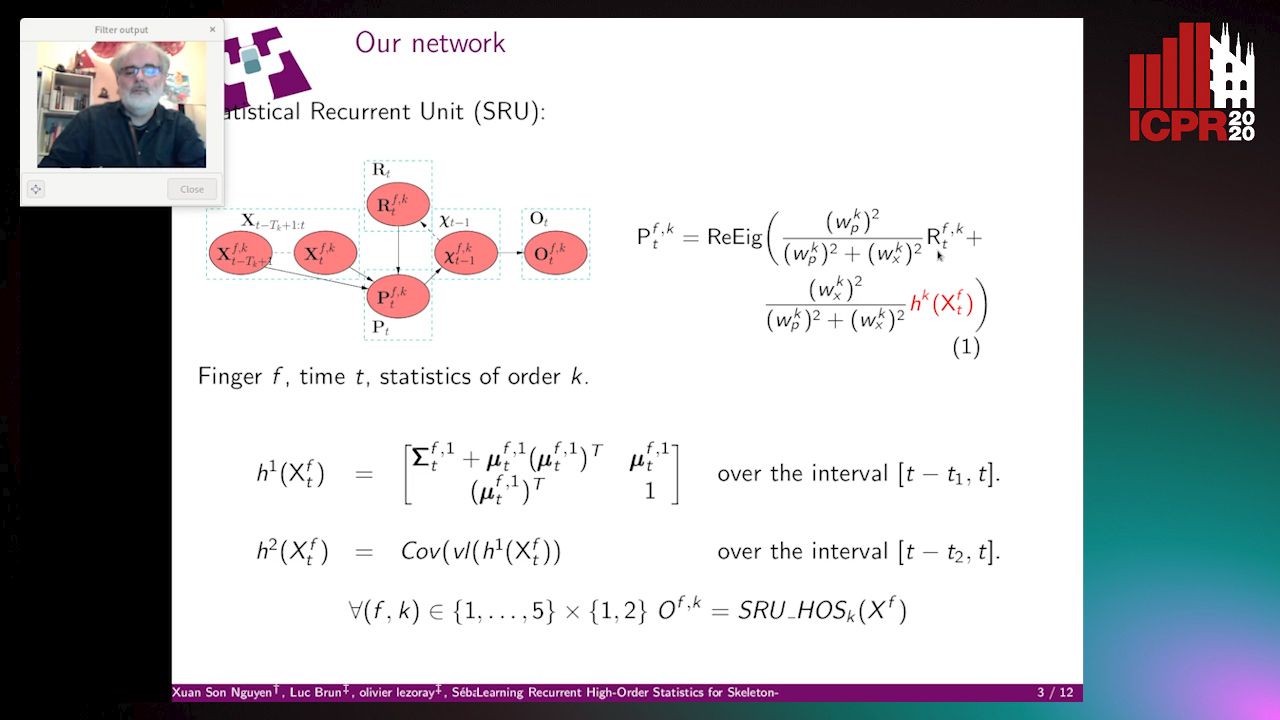
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Late Fusion of Bayesian and Convolutional Models for Action Recognition
Camille Maurice, Francisco Madrigal, Frederic Lerasle

Auto-TLDR; Fusion of Deep Neural Network and Bayesian-based Approach for Temporal Action Recognition
Abstract Slides Poster Similar
Anticipating Activity from Multimodal Signals
Tiziana Rotondo, Giovanni Maria Farinella, Davide Giacalone, Sebastiano Mauro Strano, Valeria Tomaselli, Sebastiano Battiato

Auto-TLDR; Exploiting Multimodal Signal Embedding Space for Multi-Action Prediction
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
Extracting Action Hierarchies from Action Labels and their Use in Deep Action Recognition
Konstadinos Bacharidis, Antonis Argyros

Auto-TLDR; Exploiting the Information Content of Language Label Associations for Human Action Recognition
Abstract Slides Poster Similar
A Detection-Based Approach to Multiview Action Classification in Infants
Carolina Pacheco, Effrosyni Mavroudi, Elena Kokkoni, Herbert Tanner, Rene Vidal

Auto-TLDR; Multiview Action Classification for Infants in a Pediatric Rehabilitation Environment
2D Deep Video Capsule Network with Temporal Shift for Action Recognition
Théo Voillemin, Hazem Wannous, Jean-Philippe Vandeborre

Auto-TLDR; Temporal Shift Module over Capsule Network for Action Recognition in Continuous Videos
Activity Recognition Using First-Person-View Cameras Based on Sparse Optical Flows
Peng-Yuan Kao, Yan-Jing Lei, Chia-Hao Chang, Chu-Song Chen, Ming-Sui Lee, Yi-Ping Hung

Auto-TLDR; 3D Convolutional Neural Network for Activity Recognition with FPV Videos
Abstract Slides Poster Similar
IPT: A Dataset for Identity Preserved Tracking in Closed Domains
Thomas Heitzinger, Martin Kampel

Auto-TLDR; Identity Preserved Tracking Using Depth Data for Privacy and Privacy
Abstract Slides Poster Similar
From Human Pose to On-Body Devices for Human-Activity Recognition
Fernando Moya Rueda, Gernot Fink
Auto-TLDR; Transfer Learning from Human Pose Estimation for Human Activity Recognition using Inertial Measurements from On-Body Devices
Abstract Slides Poster Similar
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Pose-Aware Multi-Feature Fusion Network for Driver Distraction Recognition
Mingyan Wu, Xi Zhang, Linlin Shen, Hang Yu

Auto-TLDR; Multi-Feature Fusion Network for Distracted Driving Detection using Pose Estimation
Abstract Slides Poster Similar
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Learning Dictionaries of Kinematic Primitives for Action Classification
Alessia Vignolo, Nicoletta Noceti, Alessandra Sciutti, Francesca Odone, Giulio Sandini

Auto-TLDR; Action Understanding using Visual Motion Primitives
Abstract Slides Poster Similar
Inferring Tasks and Fluents in Videos by Learning Causal Relations
Haowen Tang, Ping Wei, Huan Li, Nanning Zheng

Auto-TLDR; Joint Learning of Complex Task and Fluent States in Videos
Abstract Slides Poster Similar
RefiNet: 3D Human Pose Refinement with Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara

Auto-TLDR; RefiNet: A Multi-stage Framework for 3D Human Pose Estimation
3D Attention Mechanism for Fine-Grained Classification of Table Tennis Strokes Using a Twin Spatio-Temporal Convolutional Neural Networks
Pierre-Etienne Martin, Jenny Benois-Pineau, Renaud Péteri, Julien Morlier

Auto-TLDR; Attentional Blocks for Action Recognition in Table Tennis Strokes
Abstract Slides Poster Similar
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Video Representation Fusion Network For Multi-Label Movie Genre Classification
Tianyu Bi, Dmitri Jarnikov, Johan Lukkien

Auto-TLDR; A Video Representation Fusion Network for Movie Genre Classification
Abstract Slides Poster Similar