Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti,
Federico Becattini,
Federico Pernici,
Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Similar papers
RMS-Net: Regression and Masking for Soccer Event Spotting
Matteo Tomei, Lorenzo Baraldi, Simone Calderara, Simone Bronzin, Rita Cucchiara

Auto-TLDR; An Action Spotting Network for Soccer Videos
Abstract Slides Poster Similar
2D Deep Video Capsule Network with Temporal Shift for Action Recognition
Théo Voillemin, Hazem Wannous, Jean-Philippe Vandeborre

Auto-TLDR; Temporal Shift Module over Capsule Network for Action Recognition in Continuous Videos
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
Mamshad Nayeem Rizve, Ugur Demir, Praveen Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Rajendrakumar Dave, Yogesh Rawat, Mubarak Shah

Auto-TLDR; Gabriella: A Real-Time Online System for Activity Detection in Surveillance Videos
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
Late Fusion of Bayesian and Convolutional Models for Action Recognition
Camille Maurice, Francisco Madrigal, Frederic Lerasle

Auto-TLDR; Fusion of Deep Neural Network and Bayesian-based Approach for Temporal Action Recognition
Abstract Slides Poster Similar
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
Learnable Higher-Order Representation for Action Recognition

Auto-TLDR; Learningable Higher-Order Operations for Spatiotemporal Dynamics in Video Recognition
Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar, Mourad Oussalah, Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Reducing-Over-Time Tree for Event-Based Data
Shane Harrigan, Sonya Coleman, Dermot Kerr, Pratheepan Yogarajah, Zheng Fang, Chengdong Wu

Auto-TLDR; Reducing-Over-Time Binary Tree Structure for Event-Based Vision Data
Abstract Slides Poster Similar
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Continuous Sign Language Recognition with Iterative Spatiotemporal Fine-Tuning
Kenessary Koishybay, Medet Mukushev, Anara Sandygulova

Auto-TLDR; A Deep Neural Network for Continuous Sign Language Recognition with Iterative Gloss Recognition
Abstract Slides Poster Similar
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Dimche Kostadinov, Davide Scarammuza

Auto-TLDR; Unsupervised Representation Learning from Local Event Data for Pattern Recognition
Abstract Slides Poster Similar
Dynamic Resource-Aware Corner Detection for Bio-Inspired Vision Sensors
Sherif Abdelmonem Sayed Mohamed, Jawad Yasin, Mohammad-Hashem Haghbayan, Antonio Miele, Jukka Veikko Heikkonen, Hannu Tenhunen, Juha Plosila

Auto-TLDR; Three Layer Filtering-Harris Algorithm for Event-based Cameras in Real-Time
Precise Temporal Action Localization with Quantified Temporal Structure of Actions
Chongkai Lu, Ruimin Li, Hong Fu, Bin Fu, Yihao Wang, Wai Lun Lo, Zheru Chi

Auto-TLDR; Action progression networks for temporal action detection
Abstract Slides Poster Similar
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Negar Heidari, Alexandros Iosifidis

Auto-TLDR; Temporal Attention Module for Efficient Graph Convolutional Network-based Action Recognition
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
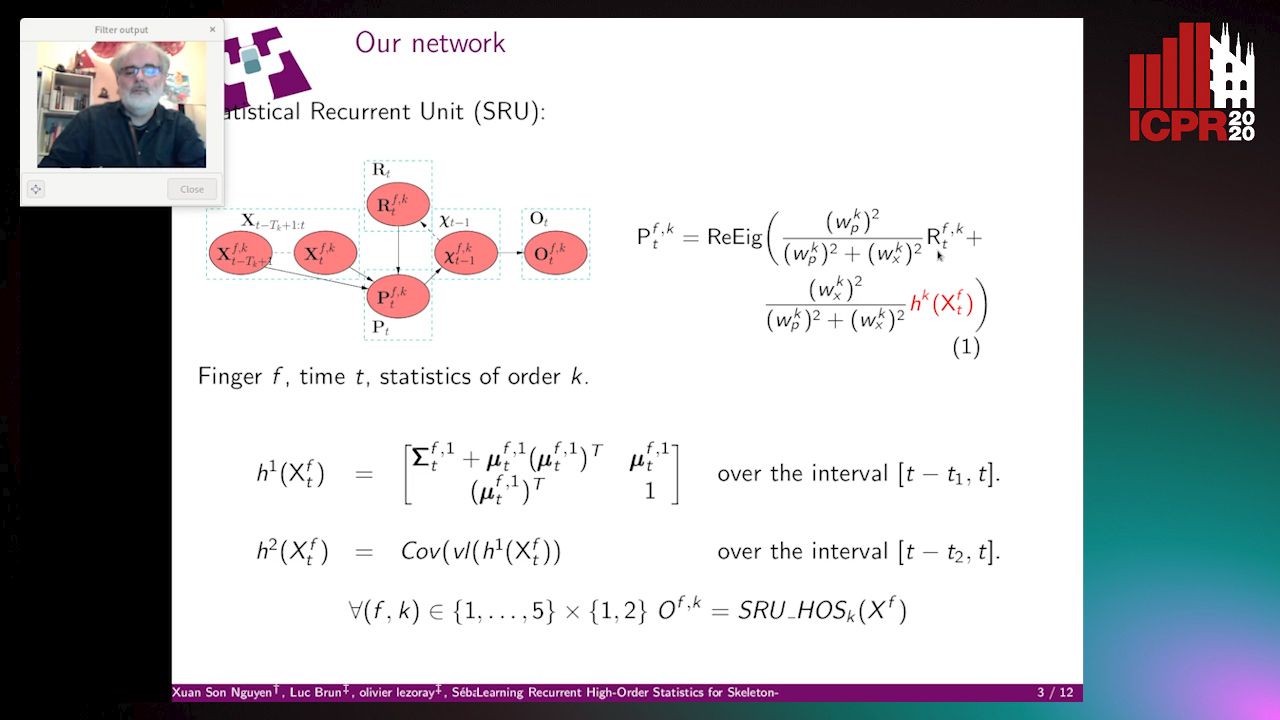
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
Self-Supervised Learning of Dynamic Representations for Static Images
Siyang Song, Enrique Sanchez, Linlin Shen, Michel Valstar

Auto-TLDR; Facial Action Unit Intensity Estimation and Affect Estimation from Still Images with Multiple Temporal Scale
Abstract Slides Poster Similar
Activity Recognition Using First-Person-View Cameras Based on Sparse Optical Flows
Peng-Yuan Kao, Yan-Jing Lei, Chia-Hao Chang, Chu-Song Chen, Ming-Sui Lee, Yi-Ping Hung

Auto-TLDR; 3D Convolutional Neural Network for Activity Recognition with FPV Videos
Abstract Slides Poster Similar
DeepPear: Deep Pose Estimation and Action Recognition
Wen-Jiin Tsai, You-Ying Jhuang

Auto-TLDR; Human Action Recognition Using RGB Video Using 3D Human Pose and Appearance Features
Abstract Slides Poster Similar
Light3DPose: Real-Time Multi-Person 3D Pose Estimation from Multiple Views
Alessio Elmi, Davide Mazzini, Pietro Tortella

Auto-TLDR; 3D Pose Estimation of Multiple People from a Few calibrated Camera Views using Deep Learning
Abstract Slides Poster Similar
You Ought to Look Around: Precise, Large Span Action Detection
Ge Pan, Zhang Han, Fan Yu, Yonghong Song, Yuanlin Zhang, Han Yuan

Auto-TLDR; YOLA: Local Feature Extraction for Action Localization with Variable receptive field
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Anomaly Detection, Localization and Classification for Railway Inspection
Riccardo Gasparini, Andrea D'Eusanio, Guido Borghi, Stefano Pini, Giuseppe Scaglione, Simone Calderara, Eugenio Fedeli, Rita Cucchiara

Auto-TLDR; Anomaly Detection and Localization using thermal images in the lowlight environment
3D Attention Mechanism for Fine-Grained Classification of Table Tennis Strokes Using a Twin Spatio-Temporal Convolutional Neural Networks
Pierre-Etienne Martin, Jenny Benois-Pineau, Renaud Péteri, Julien Morlier

Auto-TLDR; Attentional Blocks for Action Recognition in Table Tennis Strokes
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Detecting Anomalies from Video-Sequences: A Novel Descriptor
Giulia Orrù, Davide Ghiani, Maura Pintor, Gian Luca Marcialis, Fabio Roli

Auto-TLDR; Trit-based Measurement of Group Dynamics for Crowd Behavior Analysis and Anomaly Detection
Abstract Slides Poster Similar
MixTConv: Mixed Temporal Convolutional Kernels for Efficient Action Recognition
Kaiyu Shan, Yongtao Wang, Zhi Tang, Ying Chen, Yangyan Li

Auto-TLDR; Mixed Temporal Convolution for Action Recognition
Abstract Slides Poster Similar
Knowledge Distillation for Action Anticipation Via Label Smoothing
Guglielmo Camporese, Pasquale Coscia, Antonino Furnari, Giovanni Maria Farinella, Lamberto Ballan

Auto-TLDR; A Multi-Modal Framework for Action Anticipation using Long Short-Term Memory Networks
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
Vertex Feature Encoding and Hierarchical Temporal Modeling in a Spatio-Temporal Graph Convolutional Network for Action Recognition
Konstantinos Papadopoulos, Enjie Ghorbel, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Spatio-Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
Abstract Slides Poster Similar
A Detection-Based Approach to Multiview Action Classification in Infants
Carolina Pacheco, Effrosyni Mavroudi, Elena Kokkoni, Herbert Tanner, Rene Vidal

Auto-TLDR; Multiview Action Classification for Infants in a Pediatric Rehabilitation Environment
Image Sequence Based Cyclist Action Recognition Using Multi-Stream 3D Convolution
Stefan Zernetsch, Steven Schreck, Viktor Kress, Konrad Doll, Bernhard Sick

Auto-TLDR; 3D-ConvNet: A Multi-stream 3D Convolutional Neural Network for Detecting Cyclists in Real World Traffic Situations
Abstract Slides Poster Similar