Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang,
Shibo Zhou,
Jingxi Li,
Xiaohua Li,
Junsong Yuan,
Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Similar papers
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
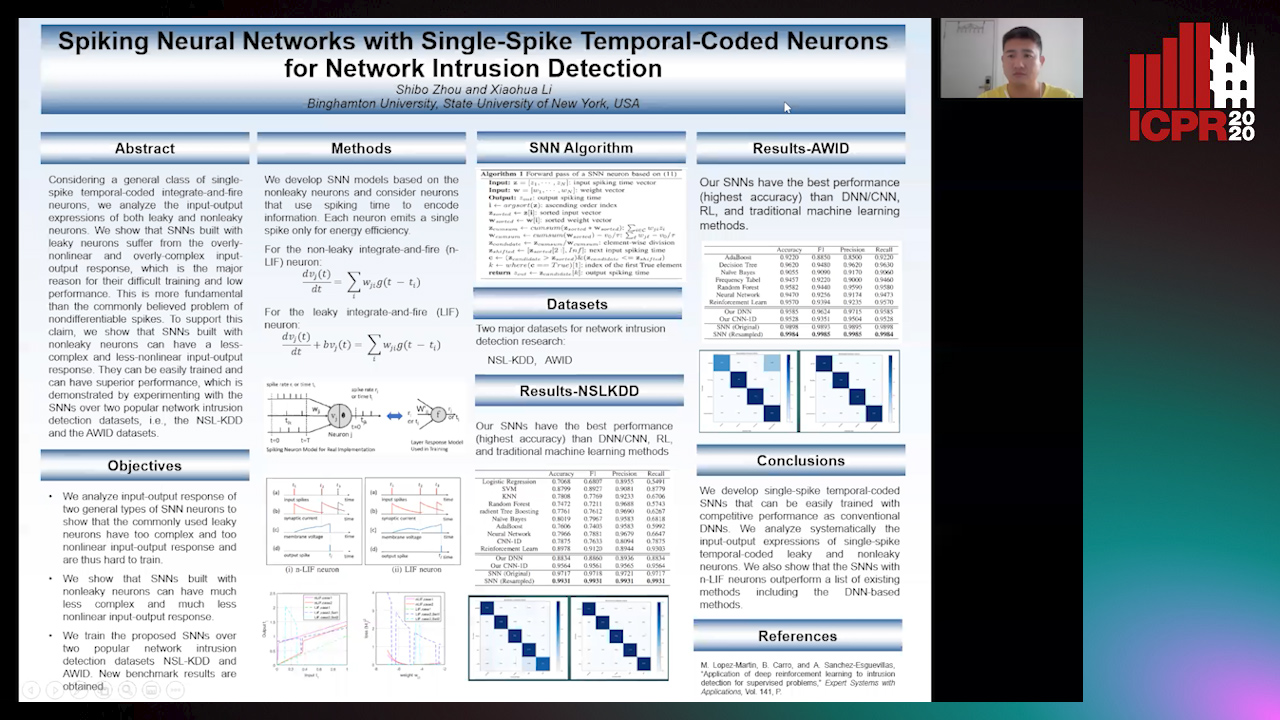
Auto-TLDR; Spiking Neural Network with Leaky Neurons
Abstract Slides Poster Similar
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang, Mingyuan Meng, Shanlin Xiao, Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Abstract Slides Poster Similar
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
Ravi Kumar Kushawaha, Saurabh Kumar, Biplab Banerjee, Rajbabu Velmurugan

Auto-TLDR; Knowledge Distillation in Spiking Neural Networks for Image Classification
Abstract Slides Poster Similar
VOWEL: A Local Online Learning Rule for Recurrent Networks of Probabilistic Spiking Winner-Take-All Circuits
Hyeryung Jang, Nicolas Skatchkovsky, Osvaldo Simeone

Auto-TLDR; VOWEL: A Variational Online Local Training Rule for Winner-Take-All Spiking Neural Networks
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
Sensor-Independent Pedestrian Detection for Personal Mobility Vehicles in Walking Space Using Dataset Generated by Simulation
Takahiro Shimizu, Kenji Koide, Shuji Oishi, Masashi Yokozuka, Atsuhiko Banno, Motoki Shino

Auto-TLDR; CosPointPillars: A 3D Object Detection Method for Pedestrian Detection in Walking Spaces
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Ghost Target Detection in 3D Radar Data Using Point Cloud Based Deep Neural Network
Mahdi Chamseddine, Jason Rambach, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; Point Based Deep Learning for Ghost Target Detection in 3D Radar Point Clouds
Abstract Slides Poster Similar
Vehicle Lane Merge Visual Benchmark

Auto-TLDR; A Benchmark for Automated Cooperative Maneuvering Using Multi-view Video Streams and Ground Truth Vehicle Description
Abstract Slides Poster Similar
CARRADA Dataset: Camera and Automotive Radar with Range-Angle-Doppler Annotations
Arthur Ouaknine, Alasdair Newson, Julien Rebut, Florence Tupin, Patrick Pérez

Auto-TLDR; CARRADA: A dataset of synchronized camera and radar recordings with range-angle-Doppler annotations for autonomous driving
Abstract Slides Poster Similar
Holistic Grid Fusion Based Stop Line Estimation
Runsheng Xu, Faezeh Tafazzoli, Li Zhang, Timo Rehfeld, Gunther Krehl, Arunava Seal

Auto-TLDR; Fused Multi-Sensory Data for Stop Lines Detection in Intersection Scenarios
Yolo+FPN: 2D and 3D Fused Object Detection with an RGB-D Camera

Auto-TLDR; Yolo+FPN: Combining 2D and 3D Object Detection for Real-Time Object Detection
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Multimodal End-To-End Learning for Autonomous Steering in Adverse Road and Weather Conditions
Jyri Sakari Maanpää, Josef Taher, Petri Manninen, Leo Pakola, Iaroslav Melekhov, Juha Hyyppä

Auto-TLDR; End-to-End Learning for Autonomous Steering in Adverse Road and Weather Conditions with Lidar Data
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Attention Based Coupled Framework for Road and Pothole Segmentation
Shaik Masihullah, Ritu Garg, Prerana Mukherjee, Anupama Ray

Auto-TLDR; Few Shot Learning for Road and Pothole Segmentation on KITTI and IDD
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
PointDrop: Improving Object Detection from Sparse Point Clouds Via Adversarial Data Augmentation
Wenxin Ma, Jian Chen, Qing Du, Wei Jia

Auto-TLDR; PointDrop: Improving Robust 3D Object Detection to Sparse Point Clouds
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Semantic Segmentation for Pedestrian Detection from Motion in Temporal Domain

Auto-TLDR; Motion Profile: Recognizing Pedestrians along with their Motion Directions in a Temporal Way
Abstract Slides Poster Similar
Human Segmentation with Dynamic LiDAR Data
Tao Zhong, Wonjik Kim, Masayuki Tanaka, Masatoshi Okutomi

Auto-TLDR; Spatiotemporal Neural Network for Human Segmentation with Dynamic Point Clouds
Manual-Label Free 3D Detection Via an Open-Source Simulator
Zhen Yang, Chi Zhang, Zhaoxiang Zhang, Huiming Guo

Auto-TLDR; DA-VoxelNet: A Novel Domain Adaptive VoxelNet for LIDAR-based 3D Object Detection
Abstract Slides Poster Similar
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Reducing-Over-Time Tree for Event-Based Data
Shane Harrigan, Sonya Coleman, Dermot Kerr, Pratheepan Yogarajah, Zheng Fang, Chengdong Wu

Auto-TLDR; Reducing-Over-Time Binary Tree Structure for Event-Based Vision Data
Abstract Slides Poster Similar
Anomaly Detection, Localization and Classification for Railway Inspection
Riccardo Gasparini, Andrea D'Eusanio, Guido Borghi, Stefano Pini, Giuseppe Scaglione, Simone Calderara, Eugenio Fedeli, Rita Cucchiara

Auto-TLDR; Anomaly Detection and Localization using thermal images in the lowlight environment
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
Dynamic Resource-Aware Corner Detection for Bio-Inspired Vision Sensors
Sherif Abdelmonem Sayed Mohamed, Jawad Yasin, Mohammad-Hashem Haghbayan, Antonio Miele, Jukka Veikko Heikkonen, Hannu Tenhunen, Juha Plosila

Auto-TLDR; Three Layer Filtering-Harris Algorithm for Event-based Cameras in Real-Time
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
Real-Time End-To-End Lane ID Estimation Using Recurrent Networks
Ibrahim Halfaoui, Fahd Bouzaraa, Onay Urfalioglu

Auto-TLDR; Real-Time, Vision-Only Lane Identification Using Monocular Camera
Abstract Slides Poster Similar
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Dimche Kostadinov, Davide Scarammuza

Auto-TLDR; Unsupervised Representation Learning from Local Event Data for Pattern Recognition
Abstract Slides Poster Similar
RefiNet: 3D Human Pose Refinement with Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara

Auto-TLDR; RefiNet: A Multi-stage Framework for 3D Human Pose Estimation
A Modified Single-Shot Multibox Detector for Beyond Real-Time Object Detection
Georgios Orfanidis, Konstantinos Ioannidis, Stefanos Vrochidis, Anastasios Tefas, Ioannis Kompatsiaris

Auto-TLDR; Single Shot Detector in Resource-Restricted Systems with Lighter SSD Variations
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Vehicle Classification from Profile Measures

Auto-TLDR; SliceNets: Convolutional Neural Networks for 3D Object Classification of Planar Slices
PolyLaneNet: Lane Estimation Via Deep Polynomial Regression
Talles Torres, Rodrigo Berriel, Thiago Paixão, Claudine Badue, Alberto F. De Souza, Thiago Oliveira-Santos

Auto-TLDR; Real-Time Lane Detection with Deep Polynomial Regression
Abstract Slides Poster Similar
PC-Net: A Deep Network for 3D Point Clouds Analysis
Zhuo Chen, Tao Guan, Yawei Luo, Yuesong Wang

Auto-TLDR; PC-Net: A Hierarchical Neural Network for 3D Point Clouds Analysis
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
DeepBEV: A Conditional Adversarial Network for Bird’s Eye View Generation

Auto-TLDR; A Generative Adversarial Network for Semantic Object Representation in Autonomous Vehicles
Abstract Slides Poster Similar
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Derivation of Geometrically and Semantically Annotated UAV Datasets at Large Scales from 3D City Models
Sidi Wu, Lukas Liebel, Marco Körner

Auto-TLDR; Large-Scale Dataset of Synthetic UAV Imagery for Geometric and Semantic Annotation
Abstract Slides Poster Similar
RONELD: Robust Neural Network Output Enhancement for Active Lane Detection
Zhe Ming Chng, Joseph Mun Hung Lew, Jimmy Addison Lee

Auto-TLDR; Real-Time Robust Neural Network Output Enhancement for Active Lane Detection
Abstract Slides Poster Similar
ResNet-Like Architecture with Low Hardware Requirements
Elena Limonova, Daniil Alfonso, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; BM-ResNet: Bipolar Morphological ResNet for Image Classification
Abstract Slides Poster Similar