Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li,
Han Cui,
Aftab Khan,
Usman Raza,
Robert Piechocki,
Angela Doufexi,
Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Similar papers
Translation Resilient Opportunistic WiFi Sensing
Mohammud Junaid Bocus, Wenda Li, Jonas Paulavičius, Ryan Mcconville, Raul Santos-Rodriguez, Kevin Chetty, Robert Piechocki

Auto-TLDR; Activity Recognition using Fine-Grained WiFi Channel State Information using WiFi CSI
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Radar Image Reconstruction from Raw ADC Data Using Parametric Variational Autoencoder with Domain Adaptation
Michael Stephan, Thomas Stadelmayer, Avik Santra, Georg Fischer, Robert Weigel, Fabian Lurz

Auto-TLDR; Parametric Variational Autoencoder-based Human Target Detection and Localization for Frequency Modulated Continuous Wave Radar
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
Air-Writing with Sparse Network of Radars Using Spatio-Temporal Learning
Muhammad Arsalan, Avik Santra, Kay Bierzynski, Vadim Issakov

Auto-TLDR; An Air-writing System for Sparse Radars using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Holistic Grid Fusion Based Stop Line Estimation
Runsheng Xu, Faezeh Tafazzoli, Li Zhang, Timo Rehfeld, Gunther Krehl, Arunava Seal

Auto-TLDR; Fused Multi-Sensory Data for Stop Lines Detection in Intersection Scenarios
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Feature Engineering and Stacked Echo State Networks for Musical Onset Detection
Peter Steiner, Azarakhsh Jalalvand, Simon Stone, Peter Birkholz

Auto-TLDR; Echo State Networks for Onset Detection in Music Analysis
Abstract Slides Poster Similar
Location Prediction in Real Homes of Older Adults based on K-Means in Low-Resolution Depth Videos
Simon Simonsson, Flávia Dias Casagrande, Evi Zouganeli

Auto-TLDR; Semi-supervised Learning for Location Recognition and Prediction in Smart Homes using Depth Video Cameras
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
Transfer Learning with Graph Neural Networks for Short-Term Highway Traffic Forecasting
Tanwi Mallick, Prasanna Balaprakash, Eric Rask, Jane Macfarlane

Auto-TLDR; Transfer Learning for Highway Traffic Forecasting on Unseen Traffic Networks
Abstract Slides Poster Similar
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
Multimodal End-To-End Learning for Autonomous Steering in Adverse Road and Weather Conditions
Jyri Sakari Maanpää, Josef Taher, Petri Manninen, Leo Pakola, Iaroslav Melekhov, Juha Hyyppä

Auto-TLDR; End-to-End Learning for Autonomous Steering in Adverse Road and Weather Conditions with Lidar Data
Abstract Slides Poster Similar
One-Shot Learning for Acoustic Identification of Bird Species in Non-Stationary Environments
Michelangelo Acconcjaioco, Stavros Ntalampiras

Auto-TLDR; One-shot Learning in the Bioacoustics Domain using Siamese Neural Networks
Abstract Slides Poster Similar
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang, Mingyuan Meng, Shanlin Xiao, Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Abstract Slides Poster Similar
Edge-Aware Graph Attention Network for Ratio of Edge-User Estimation in Mobile Networks
Jiehui Deng, Sheng Wan, Xiang Wang, Enmei Tu, Xiaolin Huang, Jie Yang, Chen Gong

Auto-TLDR; EAGAT: Edge-Aware Graph Attention Network for Automatic REU Estimation in Mobile Networks
Abstract Slides Poster Similar
Hybrid Network for End-To-End Text-Independent Speaker Identification
Wajdi Ghezaiel, Luc Brun, Olivier Lezoray

Auto-TLDR; Text-Independent Speaker Identification with Scattering Wavelet Network and Convolutional Neural Networks
Abstract Slides Poster Similar
CARRADA Dataset: Camera and Automotive Radar with Range-Angle-Doppler Annotations
Arthur Ouaknine, Alasdair Newson, Julien Rebut, Florence Tupin, Patrick Pérez

Auto-TLDR; CARRADA: A dataset of synchronized camera and radar recordings with range-angle-Doppler annotations for autonomous driving
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
The Application of Capsule Neural Network Based CNN for Speech Emotion Recognition

Auto-TLDR; CapCNN: A Capsule Neural Network for Speech Emotion Recognition
Abstract Slides Poster Similar
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
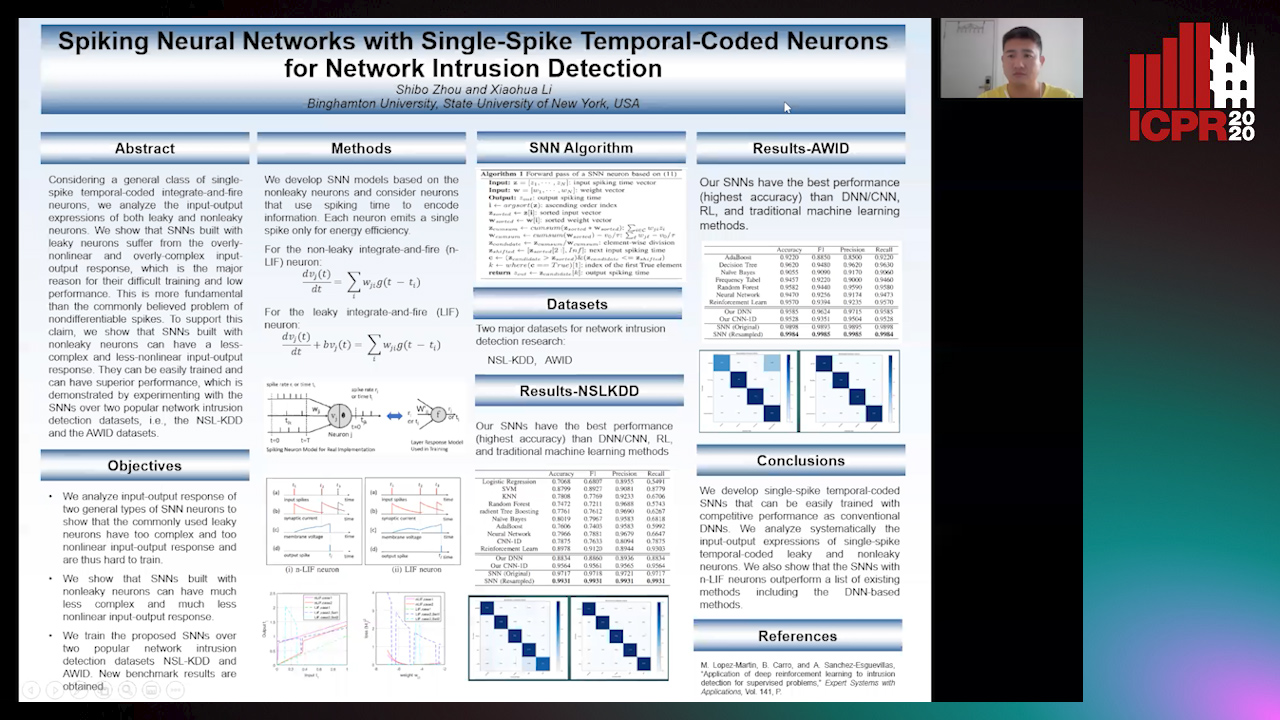
Auto-TLDR; Spiking Neural Network with Leaky Neurons
Abstract Slides Poster Similar
Fully Convolutional Neural Networks for Raw Eye Tracking Data Segmentation, Generation, and Reconstruction
Wolfgang Fuhl, Yao Rong, Enkelejda Kasneci

Auto-TLDR; Semantic Segmentation of Eye Tracking Data with Fully Convolutional Neural Networks
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Deep Learning on Active Sonar Data Using Bayesian Optimization for Hyperparameter Tuning
Henrik Berg, Karl Thomas Hjelmervik

Auto-TLDR; Bayesian Optimization for Sonar Operations in Littoral Environments
Abstract Slides Poster Similar
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
Ravi Kumar Kushawaha, Saurabh Kumar, Biplab Banerjee, Rajbabu Velmurugan

Auto-TLDR; Knowledge Distillation in Spiking Neural Networks for Image Classification
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors
Fredrik Svanström, Cristofer Englund, Fernando Alonso-Fernandez

Auto-TLDR; Automatic multi-sensor drone detection using sensor fusion
Abstract Slides Poster Similar
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Road Network Metric Learning for Estimated Time of Arrival
Yiwen Sun, Kun Fu, Zheng Wang, Changshui Zhang, Jieping Ye

Auto-TLDR; Road Network Metric Learning for Estimated Time of Arrival (RNML-ETA)
Abstract Slides Poster Similar
Map-Based Temporally Consistent Geolocalization through Learning Motion Trajectories

Auto-TLDR; Exploiting Motion Trajectories for Geolocalization of Object on Topological Map using Recurrent Neural Network
Abstract Slides Poster Similar
Neuron-Based Network Pruning Based on Majority Voting
Ali Alqahtani, Xianghua Xie, Ehab Essa, Mark W. Jones

Auto-TLDR; Large-Scale Neural Network Pruning using Majority Voting
Abstract Slides Poster Similar
Variational Information Bottleneck Model for Accurate Indoor Position Recognition

Auto-TLDR; Variational Information Bottleneck for Indoor Positioning with WiFi Fingerprints
Abstract Slides Poster Similar
Real-Time End-To-End Lane ID Estimation Using Recurrent Networks
Ibrahim Halfaoui, Fahd Bouzaraa, Onay Urfalioglu

Auto-TLDR; Real-Time, Vision-Only Lane Identification Using Monocular Camera
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
Improving Robotic Grasping on Monocular Images Via Multi-Task Learning and Positional Loss
William Prew, Toby Breckon, Magnus Bordewich, Ulrik Beierholm

Auto-TLDR; Improving grasping performance from monocularcolour images in an end-to-end CNN architecture with multi-task learning
Abstract Slides Poster Similar
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar