Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
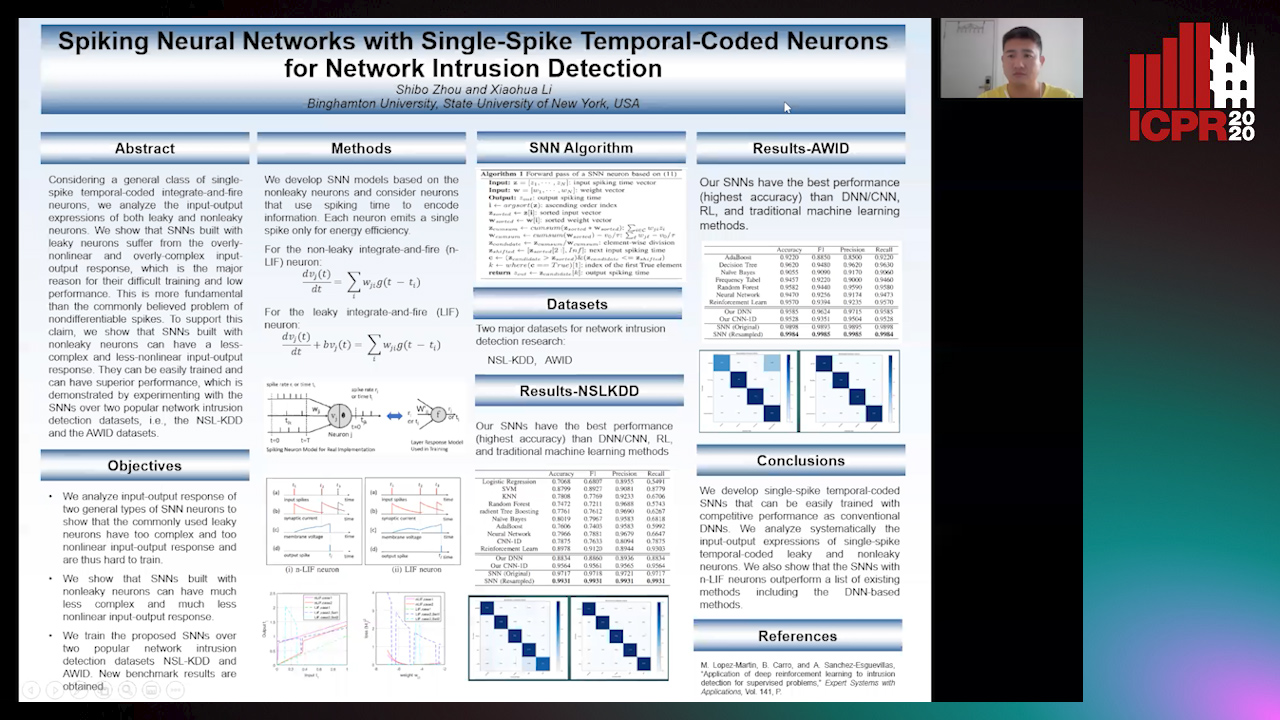
Auto-TLDR; Spiking Neural Network with Leaky Neurons
Similar papers
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang, Mingyuan Meng, Shanlin Xiao, Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
VOWEL: A Local Online Learning Rule for Recurrent Networks of Probabilistic Spiking Winner-Take-All Circuits
Hyeryung Jang, Nicolas Skatchkovsky, Osvaldo Simeone

Auto-TLDR; VOWEL: A Variational Online Local Training Rule for Winner-Take-All Spiking Neural Networks
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
Ravi Kumar Kushawaha, Saurabh Kumar, Biplab Banerjee, Rajbabu Velmurugan

Auto-TLDR; Knowledge Distillation in Spiking Neural Networks for Image Classification
Abstract Slides Poster Similar
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Dimche Kostadinov, Davide Scarammuza

Auto-TLDR; Unsupervised Representation Learning from Local Event Data for Pattern Recognition
Abstract Slides Poster Similar
ResNet-Like Architecture with Low Hardware Requirements
Elena Limonova, Daniil Alfonso, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; BM-ResNet: Bipolar Morphological ResNet for Image Classification
Abstract Slides Poster Similar
Learning Sparse Deep Neural Networks Using Efficient Structured Projections on Convex Constraints for Green AI
Michel Barlaud, Frederic Guyard

Auto-TLDR; Constrained Deep Neural Network with Constrained Splitting Projection
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Neuron-Based Network Pruning Based on Majority Voting
Ali Alqahtani, Xianghua Xie, Ehab Essa, Mark W. Jones

Auto-TLDR; Large-Scale Neural Network Pruning using Majority Voting
Abstract Slides Poster Similar
Locally-Connected, Irregular Deep Neural Networks for Biomimetic Active Vision in a Simulated Human
Masaki Nakada, Honglin Chen, Arjun Lakshmipathy, Demetri Terzopoulos

Auto-TLDR; Local-connected, Irregular Deep Neural Networks for biomimetic active vision
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Reducing-Over-Time Tree for Event-Based Data
Shane Harrigan, Sonya Coleman, Dermot Kerr, Pratheepan Yogarajah, Zheng Fang, Chengdong Wu

Auto-TLDR; Reducing-Over-Time Binary Tree Structure for Event-Based Vision Data
Abstract Slides Poster Similar
Verifying the Causes of Adversarial Examples
Honglin Li, Yifei Fan, Frieder Ganz, Tony Yezzi, Payam Barnaghi

Auto-TLDR; Exploring the Causes of Adversarial Examples in Neural Networks
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
An Efficient Empirical Solver for Localized Multiple Kernel Learning Via DNNs

Auto-TLDR; Localized Multiple Kernel Learning using LMKL-Net
Abstract Slides Poster Similar
Automatically Mining Relevant Variable Interactions Via Sparse Bayesian Learning
Ryoichiro Yafune, Daisuke Sakuma, Yasuo Tabei, Noritaka Saito, Hiroto Saigo

Auto-TLDR; Sparse Bayes for Interpretable Non-linear Prediction
Abstract Slides Poster Similar
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
Exploiting Non-Linear Redundancy for Neural Model Compression
Muhammad Ahmed Shah, Raphael Olivier, Bhiksha Raj

Auto-TLDR; Compressing Deep Neural Networks with Linear Dependency
Abstract Slides Poster Similar
An Effective Approach for Neural Network Training Based on Comprehensive Learning
Seyed Jalaleddin Mousavirad, Gerald Schaefer, Iakov Korovin

Auto-TLDR; ClPSO-LM: A Hybrid Algorithm for Multi-layer Feed-Forward Neural Networks
Ancient Document Layout Analysis: Autoencoders Meet Sparse Coding
Homa Davoudi, Marco Fiorucci, Arianna Traviglia

Auto-TLDR; Unsupervised Unsupervised Representation Learning for Document Layout Analysis
Abstract Slides Poster Similar
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar
On the Information of Feature Maps and Pruning of Deep Neural Networks
Mohammadreza Soltani, Suya Wu, Jie Ding, Robert Ravier, Vahid Tarokh

Auto-TLDR; Compressing Deep Neural Models Using Mutual Information
Abstract Slides Poster Similar
InsideBias: Measuring Bias in Deep Networks and Application to Face Gender Biometrics
Ignacio Serna, Alejandro Peña Almansa, Aythami Morales, Julian Fierrez

Auto-TLDR; InsideBias: Detecting Bias in Deep Neural Networks from Face Images
Abstract Slides Poster Similar
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Renlong Jie, Junbin Gao, Andrey Vasnev, Minh-Ngoc Tran

Auto-TLDR; Flexible Activation in Deep Neural Networks using ReLU and ELUs
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
One-Shot Learning for Acoustic Identification of Bird Species in Non-Stationary Environments
Michelangelo Acconcjaioco, Stavros Ntalampiras

Auto-TLDR; One-shot Learning in the Bioacoustics Domain using Siamese Neural Networks
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Attack-Agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
Matthew Watson, Noura Al Moubayed

Auto-TLDR; Explainability-based Detection of Adversarial Samples on EHR and Chest X-Ray Data
Abstract Slides Poster Similar
On Resource-Efficient Bayesian Network Classifiers and Deep Neural Networks
Wolfgang Roth, Günther Schindler, Holger Fröning, Franz Pernkopf

Auto-TLDR; Quantization-Aware Bayesian Network Classifiers for Small-Scale Scenarios
Abstract Slides Poster Similar
MINT: Deep Network Compression Via Mutual Information-Based Neuron Trimming
Madan Ravi Ganesh, Jason Corso, Salimeh Yasaei Sekeh

Auto-TLDR; Mutual Information-based Neuron Trimming for Deep Compression via Pruning
Abstract Slides Poster Similar
The Application of Capsule Neural Network Based CNN for Speech Emotion Recognition

Auto-TLDR; CapCNN: A Capsule Neural Network for Speech Emotion Recognition
Abstract Slides Poster Similar
Revisiting the Training of Very Deep Neural Networks without Skip Connections
Oyebade Kayode Oyedotun, Abd El Rahman Shabayek, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Optimization of Very Deep PlainNets without shortcut connections with 'vanishing and exploding units' activations'
Abstract Slides Poster Similar
Feature Engineering and Stacked Echo State Networks for Musical Onset Detection
Peter Steiner, Azarakhsh Jalalvand, Simon Stone, Peter Birkholz

Auto-TLDR; Echo State Networks for Onset Detection in Music Analysis
Abstract Slides Poster Similar
Decision Snippet Features
Pascal Welke, Fouad Alkhoury, Christian Bauckhage, Stefan Wrobel

Auto-TLDR; Decision Snippet Features for Interpretability
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
A Weak Coupling of Semi-Supervised Learning with Generative Adversarial Networks for Malware Classification
Shuwei Wang, Qiuyun Wang, Zhengwei Jiang, Xuren Wang, Rongqi Jing

Auto-TLDR; IMIR: An Improved Malware Image Rescaling Algorithm Using Semi-supervised Generative Adversarial Network
Abstract Slides Poster Similar
Beyond Cross-Entropy: Learning Highly Separable Feature Distributions for Robust and Accurate Classification
Arslan Ali, Andrea Migliorati, Tiziano Bianchi, Enrico Magli

Auto-TLDR; Gaussian class-conditional simplex loss for adversarial robust multiclass classifiers
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Human or Machine? It Is Not What You Write, but How You Write It
Luis Leiva, Moises Diaz, M.A. Ferrer, Réjean Plamondon

Auto-TLDR; Behavioral Biometrics via Handwritten Symbols for Identification and Verification
Abstract Slides Poster Similar
Norm Loss: An Efficient yet Effective Regularization Method for Deep Neural Networks
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Wei Chen, Michael Lew

Auto-TLDR; Weight Soft-Regularization with Oblique Manifold for Convolutional Neural Network Training
Abstract Slides Poster Similar
Learning Stable Deep Predictive Coding Networks with Weight Norm Supervision

Auto-TLDR; Stability of Predictive Coding Network with Weight Norm Supervision
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar