Locally-Connected, Irregular Deep Neural Networks for Biomimetic Active Vision in a Simulated Human
Masaki Nakada,
Honglin Chen,
Arjun Lakshmipathy,
Demetri Terzopoulos

Auto-TLDR; Local-connected, Irregular Deep Neural Networks for biomimetic active vision
Similar papers
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Occlusion-Tolerant and Personalized 3D Human Pose Estimation in RGB Images

Auto-TLDR; Real-Time 3D Human Pose Estimation in BVH using Inverse Kinematics Solver and Neural Networks
VOWEL: A Local Online Learning Rule for Recurrent Networks of Probabilistic Spiking Winner-Take-All Circuits
Hyeryung Jang, Nicolas Skatchkovsky, Osvaldo Simeone

Auto-TLDR; VOWEL: A Variational Online Local Training Rule for Winner-Take-All Spiking Neural Networks
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
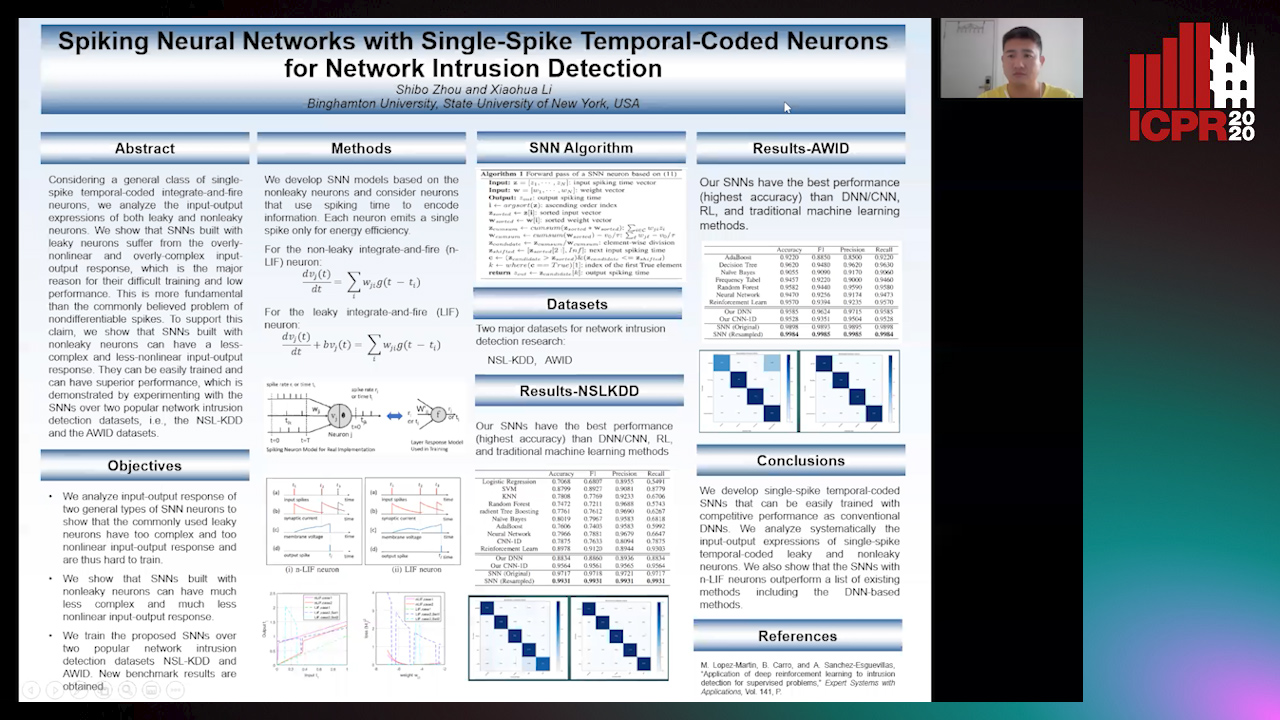
Auto-TLDR; Spiking Neural Network with Leaky Neurons
Abstract Slides Poster Similar
Fully Convolutional Neural Networks for Raw Eye Tracking Data Segmentation, Generation, and Reconstruction
Wolfgang Fuhl, Yao Rong, Enkelejda Kasneci

Auto-TLDR; Semantic Segmentation of Eye Tracking Data with Fully Convolutional Neural Networks
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang, Mingyuan Meng, Shanlin Xiao, Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Abstract Slides Poster Similar
Detection and Correspondence Matching of Corneal Reflections for Eye Tracking Using Deep Learning
Soumil Chugh, Braiden Brousseau, Jonathan Rose, Moshe Eizenman

Auto-TLDR; A Fully Convolutional Neural Network for Corneal Reflection Detection and Matching in Extended Reality Eye Tracking Systems
Abstract Slides Poster Similar
Estimating Gaze Points from Facial Landmarks by a Remote Spherical Camera

Auto-TLDR; Gaze Point Estimation from a Spherical Image from Facial Landmarks
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Map-Based Temporally Consistent Geolocalization through Learning Motion Trajectories

Auto-TLDR; Exploiting Motion Trajectories for Geolocalization of Object on Topological Map using Recurrent Neural Network
Abstract Slides Poster Similar
GazeMAE: General Representations of Eye Movements Using a Micro-Macro Autoencoder
Louise Gillian C. Bautista, Prospero Naval

Auto-TLDR; Fast and Slow Eye Movement Representations for Sentiment-agnostic Eye Tracking
Abstract Slides Poster Similar
From Early Biological Models to CNNs: Do They Look Where Humans Look?
Marinella Iole Cadoni, Andrea Lagorio, Enrico Grosso, Jia Huei Tan, Chee Seng Chan

Auto-TLDR; Comparing Neural Networks to Human Fixations for Semantic Learning
Abstract Slides Poster Similar
Collaborative Human Machine Attention Module for Character Recognition
Chetan Ralekar, Tapan Gandhi, Santanu Chaudhury

Auto-TLDR; A Collaborative Human-Machine Attention Module for Deep Neural Networks
Abstract Slides Poster Similar
Adaptive Feature Fusion Network for Gaze Tracking in Mobile Tablets
Yiwei Bao, Yihua Cheng, Yunfei Liu, Feng Lu

Auto-TLDR; Adaptive Feature Fusion Network for Multi-stream Gaze Estimation in Mobile Tablets
Abstract Slides Poster Similar
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Real-Time Driver Drowsiness Detection Using Facial Action Units
Malaika Vijay, Nandagopal Netrakanti Vinayak, Maanvi Nunna, Subramanyam Natarajan

Auto-TLDR; Real-Time Detection of Driver Drowsiness using Facial Action Units using Extreme Gradient Boosting
Abstract Slides Poster Similar
InsideBias: Measuring Bias in Deep Networks and Application to Face Gender Biometrics
Ignacio Serna, Alejandro Peña Almansa, Aythami Morales, Julian Fierrez

Auto-TLDR; InsideBias: Detecting Bias in Deep Neural Networks from Face Images
Abstract Slides Poster Similar
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
Ravi Kumar Kushawaha, Saurabh Kumar, Biplab Banerjee, Rajbabu Velmurugan

Auto-TLDR; Knowledge Distillation in Spiking Neural Networks for Image Classification
Abstract Slides Poster Similar
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Radar Image Reconstruction from Raw ADC Data Using Parametric Variational Autoencoder with Domain Adaptation
Michael Stephan, Thomas Stadelmayer, Avik Santra, Georg Fischer, Robert Weigel, Fabian Lurz

Auto-TLDR; Parametric Variational Autoencoder-based Human Target Detection and Localization for Frequency Modulated Continuous Wave Radar
Abstract Slides Poster Similar
Spatial Bias in Vision-Based Voice Activity Detection
Kalin Stefanov, Mohammad Adiban, Giampiero Salvi

Auto-TLDR; Spatial Bias in Vision-based Voice Activity Detection in Multiparty Human-Human Interactions
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Revisiting the Training of Very Deep Neural Networks without Skip Connections
Oyebade Kayode Oyedotun, Abd El Rahman Shabayek, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Optimization of Very Deep PlainNets without shortcut connections with 'vanishing and exploding units' activations'
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
Fine-Tuning Convolutional Neural Networks: A Comprehensive Guide and Benchmark Analysis for Glaucoma Screening
Amed Mvoulana, Rostom Kachouri, Mohamed Akil

Auto-TLDR; Fine-tuning Convolutional Neural Networks for Glaucoma Screening
Abstract Slides Poster Similar
Deep Ordinal Regression with Label Diversity
Axel Berg, Magnus Oskarsson, Mark Oconnor

Auto-TLDR; Discrete Regression via Classification for Neural Network Learning
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
Generalization Comparison of Deep Neural Networks Via Output Sensitivity
Mahsa Forouzesh, Farnood Salehi, Patrick Thiran

Auto-TLDR; Generalization of Deep Neural Networks using Sensitivity
A Neural Lip-Sync Framework for Synthesizing Photorealistic Virtual News Anchors
Ruobing Zheng, Zhou Zhu, Bo Song, Ji Changjiang

Auto-TLDR; Lip-sync: Synthesis of a Virtual News Anchor for Low-Delayed Applications
Abstract Slides Poster Similar
Edge-Aware Graph Attention Network for Ratio of Edge-User Estimation in Mobile Networks
Jiehui Deng, Sheng Wan, Xiang Wang, Enmei Tu, Xiaolin Huang, Jie Yang, Chen Gong

Auto-TLDR; EAGAT: Edge-Aware Graph Attention Network for Automatic REU Estimation in Mobile Networks
Abstract Slides Poster Similar
A General End-To-End Method for Characterizing Neuropsychiatric Disorders Using Free-Viewing Visual Scanning Tasks
Hong Yue Sean Liu, Jonathan Chung, Moshe Eizenman

Auto-TLDR; A general, data-driven, end-to-end framework that extracts relevant features of attentional bias from visual scanning behaviour and uses these features
Abstract Slides Poster Similar
Rotational Adjoint Methods for Learning-Free 3D Human Pose Estimation from IMU Data
Caterina Emilia Agelide Buizza, Yiannis Demiris

Auto-TLDR; Learning-free 3D Human Pose Estimation from Inertial Measurement Unit Data
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
Audio-Video Detection of the Active Speaker in Meetings
Francisco Madrigal, Frederic Lerasle, Lionel Pibre, Isabelle Ferrané

Auto-TLDR; Active Speaker Detection with Visual and Contextual Information from Meeting Context
Abstract Slides Poster Similar
Local Attention and Global Representation Collaborating for Fine-Grained Classification
He Zhang, Yunming Bai, Hui Zhang, Jing Liu, Xingguang Li, Zhaofeng He

Auto-TLDR; Weighted Region Network for Cosmetic Contact Lenses Detection
Abstract Slides Poster Similar
RefiNet: 3D Human Pose Refinement with Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara

Auto-TLDR; RefiNet: A Multi-stage Framework for 3D Human Pose Estimation
Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors
Fredrik Svanström, Cristofer Englund, Fernando Alonso-Fernandez

Auto-TLDR; Automatic multi-sensor drone detection using sensor fusion
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Reducing-Over-Time Tree for Event-Based Data
Shane Harrigan, Sonya Coleman, Dermot Kerr, Pratheepan Yogarajah, Zheng Fang, Chengdong Wu

Auto-TLDR; Reducing-Over-Time Binary Tree Structure for Event-Based Vision Data
Abstract Slides Poster Similar
Transfer Learning through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Abdullah Sarhan, Jon Rokne, Reda Alhajj, Andrew Crichton

Auto-TLDR; Deep Learning for Segmentation of Blood Vessels in Retinal Images
Abstract Slides Poster Similar