VOWEL: A Local Online Learning Rule for Recurrent Networks of Probabilistic Spiking Winner-Take-All Circuits
Hyeryung Jang,
Nicolas Skatchkovsky,
Osvaldo Simeone

Auto-TLDR; VOWEL: A Variational Online Local Training Rule for Winner-Take-All Spiking Neural Networks
Similar papers
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang, Mingyuan Meng, Shanlin Xiao, Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Abstract Slides Poster Similar
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
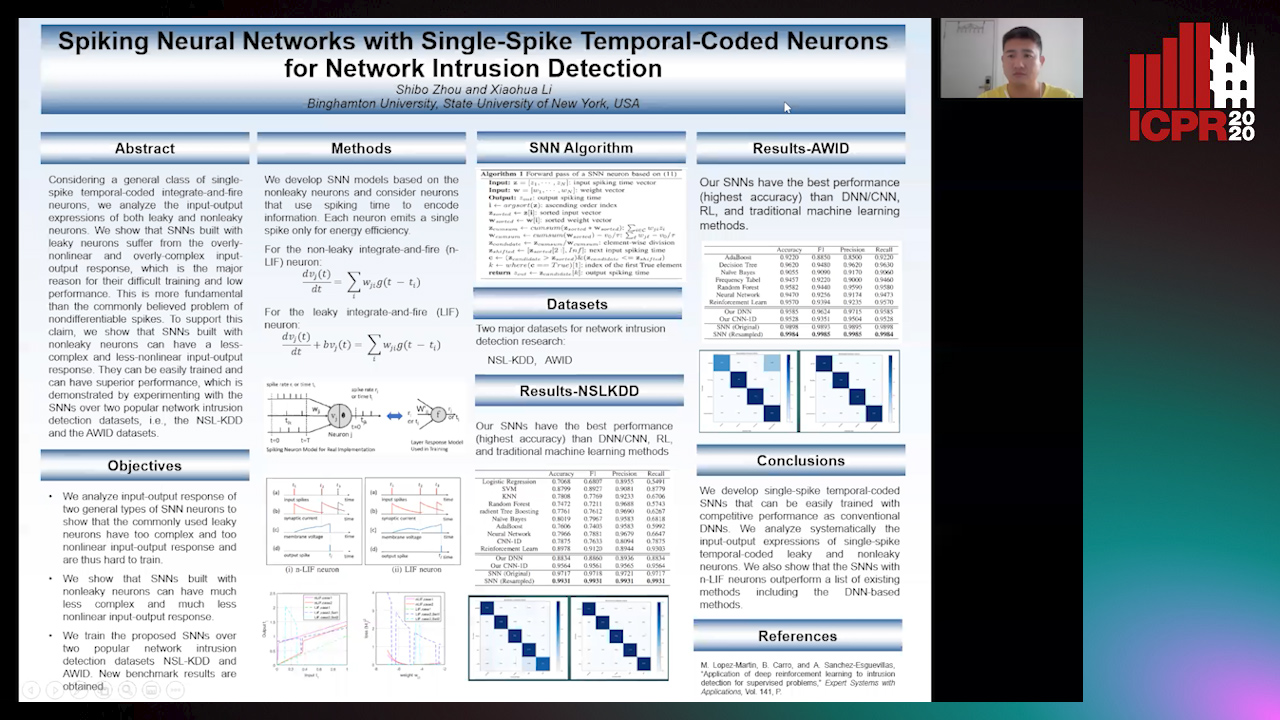
Auto-TLDR; Spiking Neural Network with Leaky Neurons
Abstract Slides Poster Similar
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
Ravi Kumar Kushawaha, Saurabh Kumar, Biplab Banerjee, Rajbabu Velmurugan

Auto-TLDR; Knowledge Distillation in Spiking Neural Networks for Image Classification
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Dimche Kostadinov, Davide Scarammuza

Auto-TLDR; Unsupervised Representation Learning from Local Event Data for Pattern Recognition
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Switching Dynamical Systems with Deep Neural Networks
Cesar Ali Ojeda Marin, Kostadin Cvejoski, Bogdan Georgiev, Ramses J. Sanchez

Auto-TLDR; Variational RNN for Switching Dynamics
Abstract Slides Poster Similar
Learning Stable Deep Predictive Coding Networks with Weight Norm Supervision

Auto-TLDR; Stability of Predictive Coding Network with Weight Norm Supervision
Abstract Slides Poster Similar
On Resource-Efficient Bayesian Network Classifiers and Deep Neural Networks
Wolfgang Roth, Günther Schindler, Holger Fröning, Franz Pernkopf

Auto-TLDR; Quantization-Aware Bayesian Network Classifiers for Small-Scale Scenarios
Abstract Slides Poster Similar
Reducing-Over-Time Tree for Event-Based Data
Shane Harrigan, Sonya Coleman, Dermot Kerr, Pratheepan Yogarajah, Zheng Fang, Chengdong Wu

Auto-TLDR; Reducing-Over-Time Binary Tree Structure for Event-Based Vision Data
Abstract Slides Poster Similar
Learning Sparse Deep Neural Networks Using Efficient Structured Projections on Convex Constraints for Green AI
Michel Barlaud, Frederic Guyard

Auto-TLDR; Constrained Deep Neural Network with Constrained Splitting Projection
Abstract Slides Poster Similar
Multi-Layered Discriminative Restricted Boltzmann Machine with Untrained Probabilistic Layer

Auto-TLDR; MDRBM: A Probabilistic Four-layered Neural Network for Extreme Learning Machine
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
Locally-Connected, Irregular Deep Neural Networks for Biomimetic Active Vision in a Simulated Human
Masaki Nakada, Honglin Chen, Arjun Lakshmipathy, Demetri Terzopoulos

Auto-TLDR; Local-connected, Irregular Deep Neural Networks for biomimetic active vision
Abstract Slides Poster Similar
Compression Strategies and Space-Conscious Representations for Deep Neural Networks
Giosuè Marinò, Gregorio Ghidoli, Marco Frasca, Dario Malchiodi

Auto-TLDR; Compression of Large Convolutional Neural Networks by Weight Pruning and Quantization
Abstract Slides Poster Similar
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar
Learning Connectivity with Graph Convolutional Networks

Auto-TLDR; Learning Graph Convolutional Networks Using Topological Properties of Graphs
Abstract Slides Poster Similar
Separation of Aleatoric and Epistemic Uncertainty in Deterministic Deep Neural Networks
Denis Huseljic, Bernhard Sick, Marek Herde, Daniel Kottke

Auto-TLDR; AE-DNN: Modeling Uncertainty in Deep Neural Networks
Abstract Slides Poster Similar
Variational Capsule Encoder
Harish Raviprakash, Syed Anwar, Ulas Bagci

Auto-TLDR; Bayesian Capsule Networks for Representation Learning in latent space
Abstract Slides Poster Similar
ResNet-Like Architecture with Low Hardware Requirements
Elena Limonova, Daniil Alfonso, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; BM-ResNet: Bipolar Morphological ResNet for Image Classification
Abstract Slides Poster Similar
One-Shot Learning for Acoustic Identification of Bird Species in Non-Stationary Environments
Michelangelo Acconcjaioco, Stavros Ntalampiras

Auto-TLDR; One-shot Learning in the Bioacoustics Domain using Siamese Neural Networks
Abstract Slides Poster Similar
Quantifying Model Uncertainty in Inverse Problems Via Bayesian Deep Gradient Descent
Riccardo Barbano, Chen Zhang, Simon Arridge, Bangti Jin

Auto-TLDR; Bayesian Neural Networks for Inverse Reconstruction via Bayesian Knowledge-Aided Computation
Abstract Slides Poster Similar
Hcore-Init: Neural Network Initialization Based on Graph Degeneracy
Stratis Limnios, George Dasoulas, Dimitrios Thilikos, Michalis Vazirgiannis

Auto-TLDR; K-hypercore: Graph Mining for Deep Neural Networks
Abstract Slides Poster Similar
Naturally Constrained Online Expectation Maximization
Daniela Pamplona, Antoine Manzanera

Auto-TLDR; Constrained Online Expectation-Maximization for Probabilistic Principal Components Analysis
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Exploiting Non-Linear Redundancy for Neural Model Compression
Muhammad Ahmed Shah, Raphael Olivier, Bhiksha Raj

Auto-TLDR; Compressing Deep Neural Networks with Linear Dependency
Abstract Slides Poster Similar
Probabilistic Latent Factor Model for Collaborative Filtering with Bayesian Inference
Jiansheng Fang, Xiaoqing Zhang, Yan Hu, Yanwu Xu, Ming Yang, Jiang Liu

Auto-TLDR; Bayesian Latent Factor Model for Collaborative Filtering
Temporal Pattern Detection in Time-Varying Graphical Models
Federico Tomasi, Veronica Tozzo, Annalisa Barla

Auto-TLDR; A dynamical network inference model that leverages on kernels to consider general temporal patterns
Abstract Slides Poster Similar
On the Information of Feature Maps and Pruning of Deep Neural Networks
Mohammadreza Soltani, Suya Wu, Jie Ding, Robert Ravier, Vahid Tarokh

Auto-TLDR; Compressing Deep Neural Models Using Mutual Information
Abstract Slides Poster Similar
Learning Sign-Constrained Support Vector Machines
Kenya Tajima, Kouhei Tsuchida, Esmeraldo Ronnie Rey Zara, Naoya Ohta, Tsuyoshi Kato

Auto-TLDR; Constrained Sign Constraints for Learning Linear Support Vector Machine
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Abstract Slides Poster Similar
Neuron-Based Network Pruning Based on Majority Voting
Ali Alqahtani, Xianghua Xie, Ehab Essa, Mark W. Jones

Auto-TLDR; Large-Scale Neural Network Pruning using Majority Voting
Abstract Slides Poster Similar
Epitomic Variational Graph Autoencoder
Rayyan Ahmad Khan, Muhammad Umer Anwaar, Martin Kleinsteuber

Auto-TLDR; EVGAE: A Generative Variational Autoencoder for Graph Data
Abstract Slides Poster Similar
Resource-efficient DNNs for Keyword Spotting using Neural Architecture Search and Quantization
David Peter, Wolfgang Roth, Franz Pernkopf

Auto-TLDR; Neural Architecture Search for Keyword Spotting in Limited Resource Environments
Abstract Slides Poster Similar
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Renlong Jie, Junbin Gao, Andrey Vasnev, Minh-Ngoc Tran

Auto-TLDR; Flexible Activation in Deep Neural Networks using ReLU and ELUs
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
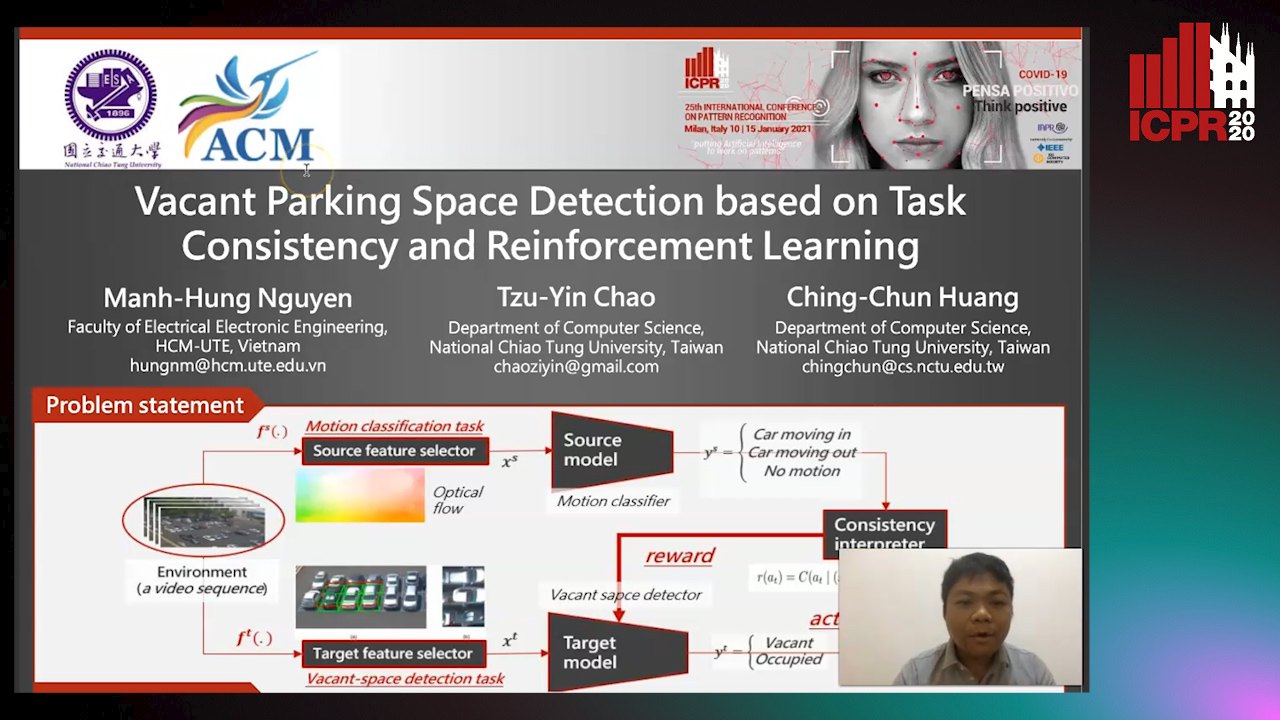
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
Leveraging Quadratic Spherical Mutual Information Hashing for Fast Image Retrieval
Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Quadratic Mutual Information for Large-Scale Hashing and Information Retrieval
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Norm Loss: An Efficient yet Effective Regularization Method for Deep Neural Networks
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Wei Chen, Michael Lew

Auto-TLDR; Weight Soft-Regularization with Oblique Manifold for Convolutional Neural Network Training
Abstract Slides Poster Similar
Map-Based Temporally Consistent Geolocalization through Learning Motion Trajectories

Auto-TLDR; Exploiting Motion Trajectories for Geolocalization of Object on Topological Map using Recurrent Neural Network
Abstract Slides Poster Similar
Aggregating Dependent Gaussian Experts in Local Approximation

Auto-TLDR; A novel approach for aggregating the Gaussian experts by detecting strong violations of conditional independence
Abstract Slides Poster Similar
Online Object Recognition Using CNN-Based Algorithm on High-Speed Camera Imaging
Shigeaki Namiki, Keiko Yokoyama, Shoji Yachida, Takashi Shibata, Hiroyoshi Miyano, Masatoshi Ishikawa

Auto-TLDR; Real-Time Object Recognition with High-Speed Camera Imaging with Population Data Clearing and Data Ensemble
Abstract Slides Poster Similar
Verifying the Causes of Adversarial Examples
Honglin Li, Yifei Fan, Frieder Ganz, Tony Yezzi, Payam Barnaghi

Auto-TLDR; Exploring the Causes of Adversarial Examples in Neural Networks
Abstract Slides Poster Similar
Interpolation in Auto Encoders with Bridge Processes
Carl Ringqvist, Henrik Hult, Judith Butepage, Hedvig Kjellstrom

Auto-TLDR; Stochastic interpolations from auto encoders trained on flattened sequences
Abstract Slides Poster Similar
Generalization Comparison of Deep Neural Networks Via Output Sensitivity
Mahsa Forouzesh, Farnood Salehi, Patrick Thiran

Auto-TLDR; Generalization of Deep Neural Networks using Sensitivity
Automatically Mining Relevant Variable Interactions Via Sparse Bayesian Learning
Ryoichiro Yafune, Daisuke Sakuma, Yasuo Tabei, Noritaka Saito, Hiroto Saigo

Auto-TLDR; Sparse Bayes for Interpretable Non-linear Prediction
Abstract Slides Poster Similar
Hierarchical Multimodal Attention for Deep Video Summarization
Melissa Sanabria, Frederic Precioso, Thomas Menguy

Auto-TLDR; Automatic Summarization of Professional Soccer Matches Using Event-Stream Data and Multi- Instance Learning
Abstract Slides Poster Similar