Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
Ravi Kumar Kushawaha,
Saurabh Kumar,
Biplab Banerjee,
Rajbabu Velmurugan

Auto-TLDR; Knowledge Distillation in Spiking Neural Networks for Image Classification
Similar papers
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang, Mingyuan Meng, Shanlin Xiao, Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
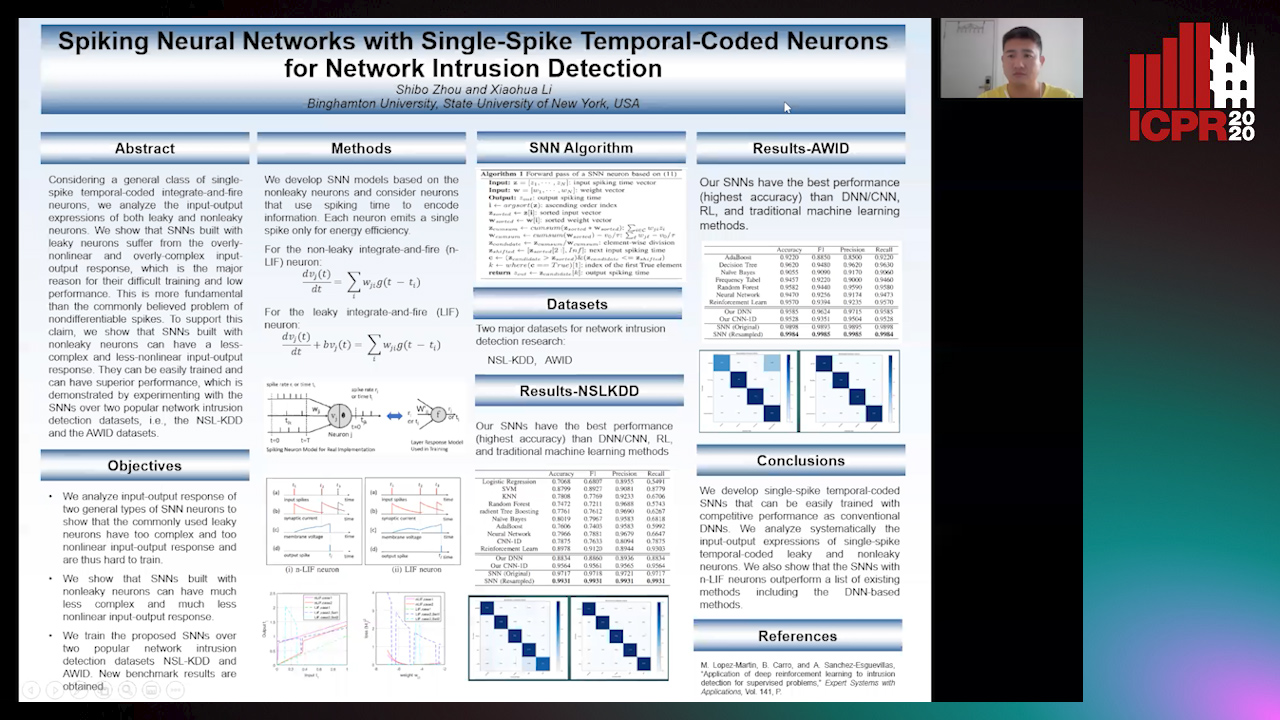
Auto-TLDR; Spiking Neural Network with Leaky Neurons
Abstract Slides Poster Similar
VOWEL: A Local Online Learning Rule for Recurrent Networks of Probabilistic Spiking Winner-Take-All Circuits
Hyeryung Jang, Nicolas Skatchkovsky, Osvaldo Simeone

Auto-TLDR; VOWEL: A Variational Online Local Training Rule for Winner-Take-All Spiking Neural Networks
Knowledge Distillation with a Precise Teacher and Prediction with Abstention

Auto-TLDR; Knowledge Distillation using Deep gambler loss and selective classification framework
Abstract Slides Poster Similar
Efficient Online Subclass Knowledge Distillation for Image Classification
Maria Tzelepi, Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; OSKD: Online Subclass Knowledge Distillation
Abstract Slides Poster Similar
Knowledge Distillation Beyond Model Compression
Fahad Sarfraz, Elahe Arani, Bahram Zonooz

Auto-TLDR; Knowledge Distillation from Teacher to Student
Abstract Slides Poster Similar
Channel Planting for Deep Neural Networks Using Knowledge Distillation
Kakeru Mitsuno, Yuichiro Nomura, Takio Kurita

Auto-TLDR; Incremental Training for Deep Neural Networks with Knowledge Distillation
Abstract Slides Poster Similar
Automatic Student Network Search for Knowledge Distillation
Zhexi Zhang, Wei Zhu, Junchi Yan, Peng Gao, Guotong Xie

Auto-TLDR; NAS-KD: Knowledge Distillation for BERT
Abstract Slides Poster Similar
Towards Low-Bit Quantization of Deep Neural Networks with Limited Data
Yong Yuan, Chen Chen, Xiyuan Hu, Silong Peng

Auto-TLDR; Low-Precision Quantization of Deep Neural Networks with Limited Data
Abstract Slides Poster Similar
Compact CNN Structure Learning by Knowledge Distillation
Waqar Ahmed, Andrea Zunino, Pietro Morerio, Vittorio Murino

Auto-TLDR; Knowledge Distillation for Compressing Deep Convolutional Neural Networks
Abstract Slides Poster Similar
FastSal: A Computationally Efficient Network for Visual Saliency Prediction

Auto-TLDR; MobileNetV2: A Convolutional Neural Network for Saliency Prediction
Abstract Slides Poster Similar
Learning Sparse Deep Neural Networks Using Efficient Structured Projections on Convex Constraints for Green AI
Michel Barlaud, Frederic Guyard

Auto-TLDR; Constrained Deep Neural Network with Constrained Splitting Projection
Abstract Slides Poster Similar
Teacher-Student Training and Triplet Loss for Facial Expression Recognition under Occlusion
Mariana-Iuliana Georgescu, Radu Ionescu

Auto-TLDR; Knowledge Distillation for Facial Expression Recognition under Occlusion
Adaptive Noise Injection for Training Stochastic Student Networks from Deterministic Teachers
Yi Xiang Marcus Tan, Yuval Elovici, Alexander Binder

Auto-TLDR; Adaptive Stochastic Networks for Adversarial Attacks
Feature Fusion for Online Mutual Knowledge Distillation
Jangho Kim, Minsung Hyun, Inseop Chung, Nojun Kwak

Auto-TLDR; Feature Fusion Learning Using Fusion of Sub-Networks
Abstract Slides Poster Similar
Neuron-Based Network Pruning Based on Majority Voting
Ali Alqahtani, Xianghua Xie, Ehab Essa, Mark W. Jones

Auto-TLDR; Large-Scale Neural Network Pruning using Majority Voting
Abstract Slides Poster Similar
Exploiting Non-Linear Redundancy for Neural Model Compression
Muhammad Ahmed Shah, Raphael Olivier, Bhiksha Raj

Auto-TLDR; Compressing Deep Neural Networks with Linear Dependency
Abstract Slides Poster Similar
Neural Compression and Filtering for Edge-assisted Real-time Object Detection in Challenged Networks
Yoshitomo Matsubara, Marco Levorato

Auto-TLDR; Deep Neural Networks for Remote Object Detection Using Edge Computing
Abstract Slides Poster Similar
A Boundary-Aware Distillation Network for Compressed Video Semantic Segmentation

Auto-TLDR; A Boundary-Aware Distillation Network for Video Semantic Segmentation
Abstract Slides Poster Similar
Rethinking of Deep Models Parameters with Respect to Data Distribution
Shitala Prasad, Dongyun Lin, Yiqun Li, Sheng Dong, Zaw Min Oo

Auto-TLDR; A progressive stepwise training strategy for deep neural networks
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Feature-Supervised Action Modality Transfer
Fida Mohammad Thoker, Cees Snoek

Auto-TLDR; Cross-Modal Action Recognition and Detection in Non-RGB Video Modalities by Learning from Large-Scale Labeled RGB Data
Abstract Slides Poster Similar
Adversarial Knowledge Distillation for a Compact Generator
Hideki Tsunashima, Shigeo Morishima, Junji Yamato, Qiu Chen, Hirokatsu Kataoka

Auto-TLDR; Adversarial Knowledge Distillation for Generative Adversarial Nets
Abstract Slides Poster Similar
Exploiting Distilled Learning for Deep Siamese Tracking
Chengxin Liu, Zhiguo Cao, Wei Li, Yang Xiao, Shuaiyuan Du, Angfan Zhu

Auto-TLDR; Distilled Learning Framework for Siamese Tracking
Abstract Slides Poster Similar
On the Information of Feature Maps and Pruning of Deep Neural Networks
Mohammadreza Soltani, Suya Wu, Jie Ding, Robert Ravier, Vahid Tarokh

Auto-TLDR; Compressing Deep Neural Models Using Mutual Information
Abstract Slides Poster Similar
Adaptive Distillation for Decentralized Learning from Heterogeneous Clients
Jiaxin Ma, Ryo Yonetani, Zahid Iqbal

Auto-TLDR; Decentralized Learning via Adaptive Distillation
Abstract Slides Poster Similar
MaxDropout: Deep Neural Network Regularization Based on Maximum Output Values
Claudio Filipi Gonçalves Santos, Danilo Colombo, Mateus Roder, Joao Paulo Papa

Auto-TLDR; MaxDropout: A Regularizer for Deep Neural Networks
Abstract Slides Poster Similar
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
Stochastic Label Refinery: Toward Better Target Label Distribution
Xi Fang, Jiancheng Yang, Bingbing Ni

Auto-TLDR; Stochastic Label Refinery for Deep Supervised Learning
Abstract Slides Poster Similar
HFP: Hardware-Aware Filter Pruning for Deep Convolutional Neural Networks Acceleration
Fang Yu, Chuanqi Han, Pengcheng Wang, Ruoran Huang, Xi Huang, Li Cui

Auto-TLDR; Hardware-Aware Filter Pruning for Convolutional Neural Networks
Abstract Slides Poster Similar
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
ResNet-Like Architecture with Low Hardware Requirements
Elena Limonova, Daniil Alfonso, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; BM-ResNet: Bipolar Morphological ResNet for Image Classification
Abstract Slides Poster Similar
MINT: Deep Network Compression Via Mutual Information-Based Neuron Trimming
Madan Ravi Ganesh, Jason Corso, Salimeh Yasaei Sekeh

Auto-TLDR; Mutual Information-based Neuron Trimming for Deep Compression via Pruning
Abstract Slides Poster Similar
Norm Loss: An Efficient yet Effective Regularization Method for Deep Neural Networks
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Wei Chen, Michael Lew

Auto-TLDR; Weight Soft-Regularization with Oblique Manifold for Convolutional Neural Network Training
Abstract Slides Poster Similar
Iterative Label Improvement: Robust Training by Confidence Based Filtering and Dataset Partitioning
Christian Haase-Schütz, Rainer Stal, Heinz Hertlein, Bernhard Sick

Auto-TLDR; Meta Training and Labelling for Unlabelled Data
Abstract Slides Poster Similar
Activation Density Driven Efficient Pruning in Training
Timothy Foldy-Porto, Yeshwanth Venkatesha, Priyadarshini Panda

Auto-TLDR; Real-Time Neural Network Pruning with Compressed Networks
Abstract Slides Poster Similar
Multi-Order Feature Statistical Model for Fine-Grained Visual Categorization
Qingtao Wang, Ke Zhang, Shaoli Huang, Lianbo Zhang, Jin Fan

Auto-TLDR; Multi-Order Feature Statistical Method for Fine-Grained Visual Categorization
Abstract Slides Poster Similar
Progressive Gradient Pruning for Classification, Detection and Domain Adaptation
Le Thanh Nguyen-Meidine, Eric Granger, Marco Pedersoli, Madhu Kiran, Louis-Antoine Blais-Morin

Auto-TLDR; Progressive Gradient Pruning for Iterative Filter Pruning of Convolutional Neural Networks
Abstract Slides Poster Similar
Beyond Cross-Entropy: Learning Highly Separable Feature Distributions for Robust and Accurate Classification
Arslan Ali, Andrea Migliorati, Tiziano Bianchi, Enrico Magli

Auto-TLDR; Gaussian class-conditional simplex loss for adversarial robust multiclass classifiers
Abstract Slides Poster Similar
Cam-Softmax for Discriminative Deep Feature Learning
Tamas Suveges, Stephen James Mckenna

Auto-TLDR; Cam-Softmax: A Generalisation of Activations and Softmax for Deep Feature Spaces
Abstract Slides Poster Similar
Variational Capsule Encoder
Harish Raviprakash, Syed Anwar, Ulas Bagci

Auto-TLDR; Bayesian Capsule Networks for Representation Learning in latent space
Abstract Slides Poster Similar
A Delayed Elastic-Net Approach for Performing Adversarial Attacks
Brais Cancela, Veronica Bolon-Canedo, Amparo Alonso-Betanzos

Auto-TLDR; Robustness of ImageNet Pretrained Models against Adversarial Attacks
Abstract Slides Poster Similar
Pretraining Image Encoders without Reconstruction Via Feature Prediction Loss
Gustav Grund Pihlgren, Fredrik Sandin, Marcus Liwicki

Auto-TLDR; Feature Prediction Loss for Autoencoder-based Pretraining of Image Encoders
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Renlong Jie, Junbin Gao, Andrey Vasnev, Minh-Ngoc Tran

Auto-TLDR; Flexible Activation in Deep Neural Networks using ReLU and ELUs
Abstract Slides Poster Similar
Resource-efficient DNNs for Keyword Spotting using Neural Architecture Search and Quantization
David Peter, Wolfgang Roth, Franz Pernkopf

Auto-TLDR; Neural Architecture Search for Keyword Spotting in Limited Resource Environments
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar