SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang,
Mingyuan Meng,
Shanlin Xiao,
Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Similar papers
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
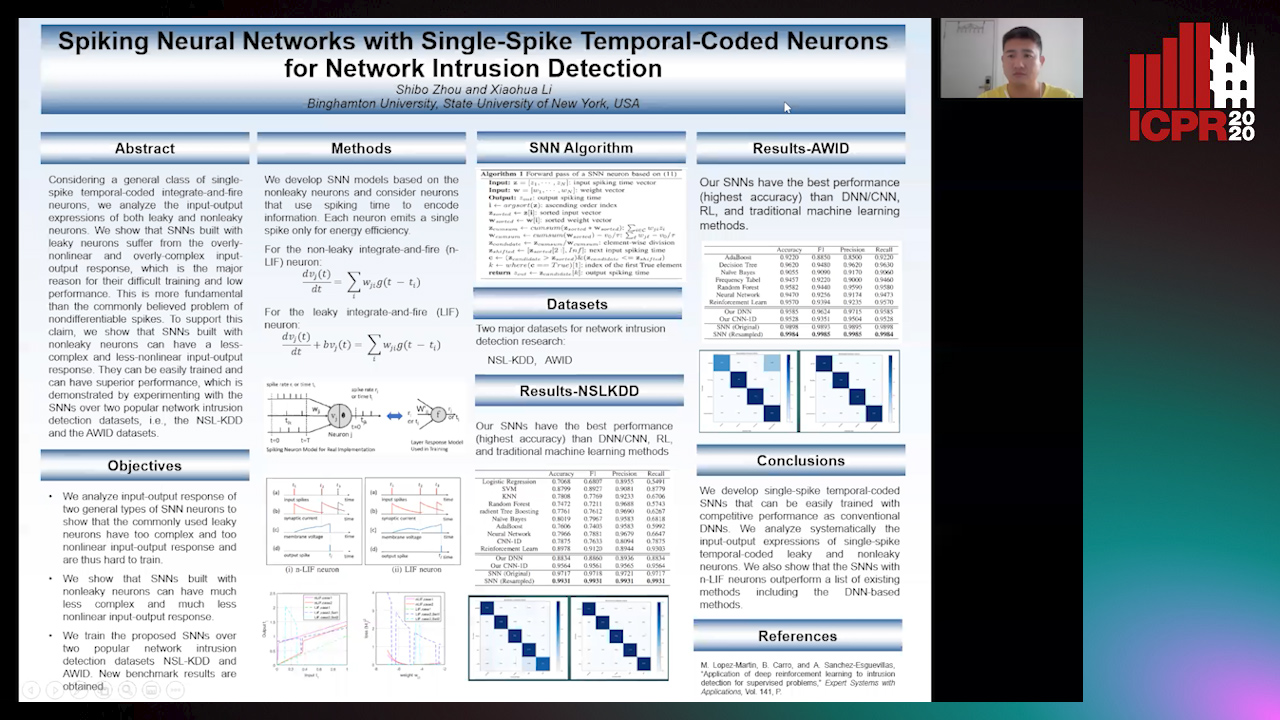
Auto-TLDR; Spiking Neural Network with Leaky Neurons
Abstract Slides Poster Similar
VOWEL: A Local Online Learning Rule for Recurrent Networks of Probabilistic Spiking Winner-Take-All Circuits
Hyeryung Jang, Nicolas Skatchkovsky, Osvaldo Simeone

Auto-TLDR; VOWEL: A Variational Online Local Training Rule for Winner-Take-All Spiking Neural Networks
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
Ravi Kumar Kushawaha, Saurabh Kumar, Biplab Banerjee, Rajbabu Velmurugan

Auto-TLDR; Knowledge Distillation in Spiking Neural Networks for Image Classification
Abstract Slides Poster Similar
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Dimche Kostadinov, Davide Scarammuza

Auto-TLDR; Unsupervised Representation Learning from Local Event Data for Pattern Recognition
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Neuron-Based Network Pruning Based on Majority Voting
Ali Alqahtani, Xianghua Xie, Ehab Essa, Mark W. Jones

Auto-TLDR; Large-Scale Neural Network Pruning using Majority Voting
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Reducing-Over-Time Tree for Event-Based Data
Shane Harrigan, Sonya Coleman, Dermot Kerr, Pratheepan Yogarajah, Zheng Fang, Chengdong Wu

Auto-TLDR; Reducing-Over-Time Binary Tree Structure for Event-Based Vision Data
Abstract Slides Poster Similar
ResNet-Like Architecture with Low Hardware Requirements
Elena Limonova, Daniil Alfonso, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; BM-ResNet: Bipolar Morphological ResNet for Image Classification
Abstract Slides Poster Similar
Verifying the Causes of Adversarial Examples
Honglin Li, Yifei Fan, Frieder Ganz, Tony Yezzi, Payam Barnaghi

Auto-TLDR; Exploring the Causes of Adversarial Examples in Neural Networks
Abstract Slides Poster Similar
Multi-Layered Discriminative Restricted Boltzmann Machine with Untrained Probabilistic Layer

Auto-TLDR; MDRBM: A Probabilistic Four-layered Neural Network for Extreme Learning Machine
Locally-Connected, Irregular Deep Neural Networks for Biomimetic Active Vision in a Simulated Human
Masaki Nakada, Honglin Chen, Arjun Lakshmipathy, Demetri Terzopoulos

Auto-TLDR; Local-connected, Irregular Deep Neural Networks for biomimetic active vision
Abstract Slides Poster Similar
Generalization Comparison of Deep Neural Networks Via Output Sensitivity
Mahsa Forouzesh, Farnood Salehi, Patrick Thiran

Auto-TLDR; Generalization of Deep Neural Networks using Sensitivity
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
One-Shot Learning for Acoustic Identification of Bird Species in Non-Stationary Environments
Michelangelo Acconcjaioco, Stavros Ntalampiras

Auto-TLDR; One-shot Learning in the Bioacoustics Domain using Siamese Neural Networks
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
Learning Stable Deep Predictive Coding Networks with Weight Norm Supervision

Auto-TLDR; Stability of Predictive Coding Network with Weight Norm Supervision
Abstract Slides Poster Similar
An Effective Approach for Neural Network Training Based on Comprehensive Learning
Seyed Jalaleddin Mousavirad, Gerald Schaefer, Iakov Korovin

Auto-TLDR; ClPSO-LM: A Hybrid Algorithm for Multi-layer Feed-Forward Neural Networks
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
MaxDropout: Deep Neural Network Regularization Based on Maximum Output Values
Claudio Filipi Gonçalves Santos, Danilo Colombo, Mateus Roder, Joao Paulo Papa

Auto-TLDR; MaxDropout: A Regularizer for Deep Neural Networks
Abstract Slides Poster Similar
CQNN: Convolutional Quadratic Neural Networks

Auto-TLDR; Quadratic Neural Network for Image Classification
Abstract Slides Poster Similar
Feature-Aware Unsupervised Learning with Joint Variational Attention and Automatic Clustering
Wang Ru, Lin Li, Peipei Wang, Liu Peiyu

Auto-TLDR; Deep Variational Attention Encoder-Decoder for Clustering
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
A Multilinear Sampling Algorithm to Estimate Shapley Values

Auto-TLDR; A sampling method for Shapley values for multilayer Perceptrons
Abstract Slides Poster Similar
Learning Sparse Deep Neural Networks Using Efficient Structured Projections on Convex Constraints for Green AI
Michel Barlaud, Frederic Guyard

Auto-TLDR; Constrained Deep Neural Network with Constrained Splitting Projection
Abstract Slides Poster Similar
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Variational Capsule Encoder
Harish Raviprakash, Syed Anwar, Ulas Bagci

Auto-TLDR; Bayesian Capsule Networks for Representation Learning in latent space
Abstract Slides Poster Similar
Nearest Neighbor Classification Based on Activation Space of Convolutional Neural Network
Xinbo Ju, Shuo Shao, Huan Long, Weizhe Wang

Auto-TLDR; Convolutional Neural Network with Convex Hull Based Classifier
Learning with Delayed Feedback
Pranavan Theivendiram, Terence Sim

Auto-TLDR; Unsupervised Machine Learning with Delayed Feedback
Abstract Slides Poster Similar
Fractional Adaptation of Activation Functions in Neural Networks
Julio Zamora Esquivel, Jesus Adan Cruz Vargas, Paulo Lopez-Meyer, Hector Alfonso Cordourier Maruri, Jose Rodrigo Camacho Perez, Omesh Tickoo

Auto-TLDR; Automatic Selection of Activation Functions in Neural Networks using Fractional Calculus
Abstract Slides Poster Similar
Mean Decision Rules Method with Smart Sampling for Fast Large-Scale Binary SVM Classification
Alexandra Makarova, Mikhail Kurbakov, Valentina Sulimova

Auto-TLDR; Improving Mean Decision Rule for Large-Scale Binary SVM Problems
Abstract Slides Poster Similar
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Renlong Jie, Junbin Gao, Andrey Vasnev, Minh-Ngoc Tran

Auto-TLDR; Flexible Activation in Deep Neural Networks using ReLU and ELUs
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
A Weak Coupling of Semi-Supervised Learning with Generative Adversarial Networks for Malware Classification
Shuwei Wang, Qiuyun Wang, Zhengwei Jiang, Xuren Wang, Rongqi Jing

Auto-TLDR; IMIR: An Improved Malware Image Rescaling Algorithm Using Semi-supervised Generative Adversarial Network
Abstract Slides Poster Similar
Feature Engineering and Stacked Echo State Networks for Musical Onset Detection
Peter Steiner, Azarakhsh Jalalvand, Simon Stone, Peter Birkholz

Auto-TLDR; Echo State Networks for Onset Detection in Music Analysis
Abstract Slides Poster Similar
The Application of Capsule Neural Network Based CNN for Speech Emotion Recognition

Auto-TLDR; CapCNN: A Capsule Neural Network for Speech Emotion Recognition
Abstract Slides Poster Similar
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Open Set Domain Recognition Via Attention-Based GCN and Semantic Matching Optimization
Xinxing He, Yuan Yuan, Zhiyu Jiang

Auto-TLDR; Attention-based GCN and Semantic Matching Optimization for Open Set Domain Recognition
Abstract Slides Poster Similar
HFP: Hardware-Aware Filter Pruning for Deep Convolutional Neural Networks Acceleration
Fang Yu, Chuanqi Han, Pengcheng Wang, Ruoran Huang, Xi Huang, Li Cui

Auto-TLDR; Hardware-Aware Filter Pruning for Convolutional Neural Networks
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
Dual-Memory Model for Incremental Learning: The Handwriting Recognition Use Case
Mélanie Piot, Bérangère Bourdoulous, Aurelia Deshayes, Lionel Prevost

Auto-TLDR; A dual memory model for handwriting recognition
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
Deep Learning-Based Type Identification of Volumetric MRI Sequences
Jean Pablo De Mello, Thiago Paixão, Rodrigo Berriel, Mauricio Reyes, Alberto F. De Souza, Claudine Badue, Thiago Oliveira-Santos

Auto-TLDR; Deep Learning for Brain MRI Sequences Identification Using Convolutional Neural Network
Abstract Slides Poster Similar
Probability Guided Maxout
Claudio Ferrari, Stefano Berretti, Alberto Del Bimbo

Auto-TLDR; Probability Guided Maxout for CNN Training
Abstract Slides Poster Similar
Complementing Representation Deficiency in Few-Shot Image Classification: A Meta-Learning Approach
Xian Zhong, Cheng Gu, Wenxin Huang, Lin Li, Shuqin Chen, Chia-Wen Lin

Auto-TLDR; Meta-learning with Complementary Representations Network for Few-Shot Learning
Abstract Slides Poster Similar