Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li,
Hui Zheng,
He Zhu,
Haojun Ai,
Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Similar papers
Text Recognition in Real Scenarios with a Few Labeled Samples
Jinghuang Lin, Cheng Zhanzhan, Fan Bai, Yi Niu, Shiliang Pu, Shuigeng Zhou

Auto-TLDR; Few-shot Adversarial Sequence Domain Adaptation for Scene Text Recognition
Abstract Slides Poster Similar
Online Trajectory Recovery from Offline Handwritten Japanese Kanji Characters of Multiple Strokes
Hung Tuan Nguyen, Tsubasa Nakamura, Cuong Tuan Nguyen, Masaki Nakagawa

Auto-TLDR; Recovering Dynamic Online Trajectories from Offline Japanese Kanji Character Images for Handwritten Character Recognition
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Air-Writing with Sparse Network of Radars Using Spatio-Temporal Learning
Muhammad Arsalan, Avik Santra, Kay Bierzynski, Vadim Issakov

Auto-TLDR; An Air-writing System for Sparse Radars using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Human or Machine? It Is Not What You Write, but How You Write It
Luis Leiva, Moises Diaz, M.A. Ferrer, Réjean Plamondon

Auto-TLDR; Behavioral Biometrics via Handwritten Symbols for Identification and Verification
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Transfer Learning with Graph Neural Networks for Short-Term Highway Traffic Forecasting
Tanwi Mallick, Prasanna Balaprakash, Eric Rask, Jane Macfarlane

Auto-TLDR; Transfer Learning for Highway Traffic Forecasting on Unseen Traffic Networks
Abstract Slides Poster Similar
Conditional-UNet: A Condition-Aware Deep Model for Coherent Human Activity Recognition from Wearables
Liming Zhang, Wenbin Zhang, Nathalie Japkowicz

Auto-TLDR; Coherent Human Activity Recognition from Multi-Channel Time Series Data
Abstract Slides Poster Similar
From Human Pose to On-Body Devices for Human-Activity Recognition
Fernando Moya Rueda, Gernot Fink
Auto-TLDR; Transfer Learning from Human Pose Estimation for Human Activity Recognition using Inertial Measurements from On-Body Devices
Abstract Slides Poster Similar
Unsupervised Multi-Task Domain Adaptation

Auto-TLDR; Unsupervised Domain Adaptation with Multi-task Learning for Image Recognition
Abstract Slides Poster Similar
A Unified Framework for Distance-Aware Domain Adaptation
Fei Wang, Youdong Ding, Huan Liang, Yuzhen Gao, Wenqi Che

Auto-TLDR; distance-aware domain adaptation
Abstract Slides Poster Similar
A Weak Coupling of Semi-Supervised Learning with Generative Adversarial Networks for Malware Classification
Shuwei Wang, Qiuyun Wang, Zhengwei Jiang, Xuren Wang, Rongqi Jing

Auto-TLDR; IMIR: An Improved Malware Image Rescaling Algorithm Using Semi-supervised Generative Adversarial Network
Abstract Slides Poster Similar
DAPC: Domain Adaptation People Counting Via Style-Level Transfer Learning and Scene-Aware Estimation
Na Jiang, Xingsen Wen, Zhiping Shi

Auto-TLDR; Domain Adaptation People counting via Style-Level Transfer Learning and Scene-Aware Estimation
Abstract Slides Poster Similar
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
Not All Domains Are Equally Complex: Adaptive Multi-Domain Learning
Ali Senhaji, Jenni Karoliina Raitoharju, Moncef Gabbouj, Alexandros Iosifidis

Auto-TLDR; Adaptive Parameterization for Multi-Domain Learning
Abstract Slides Poster Similar
Randomized Transferable Machine

Auto-TLDR; Randomized Transferable Machine for Suboptimal Feature-based Transfer Learning
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar
Enlarging Discriminative Power by Adding an Extra Class in Unsupervised Domain Adaptation
Hai Tran, Sumyeong Ahn, Taeyoung Lee, Yung Yi

Auto-TLDR; Unsupervised Domain Adaptation using Artificial Classes
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
2D License Plate Recognition based on Automatic Perspective Rectification
Hui Xu, Zhao-Hong Guo, Da-Han Wang, Xiang-Dong Zhou, Yu Shi

Auto-TLDR; Perspective Rectification Network for License Plate Recognition
Abstract Slides Poster Similar
Location Prediction in Real Homes of Older Adults based on K-Means in Low-Resolution Depth Videos
Simon Simonsson, Flávia Dias Casagrande, Evi Zouganeli

Auto-TLDR; Semi-supervised Learning for Location Recognition and Prediction in Smart Homes using Depth Video Cameras
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
The Application of Capsule Neural Network Based CNN for Speech Emotion Recognition

Auto-TLDR; CapCNN: A Capsule Neural Network for Speech Emotion Recognition
Abstract Slides Poster Similar
Open Set Domain Recognition Via Attention-Based GCN and Semantic Matching Optimization
Xinxing He, Yuan Yuan, Zhiyu Jiang

Auto-TLDR; Attention-based GCN and Semantic Matching Optimization for Open Set Domain Recognition
Abstract Slides Poster Similar
Building Computationally Efficient and Well-Generalizing Person Re-Identification Models with Metric Learning
Vladislav Sovrasov, Dmitry Sidnev

Auto-TLDR; Cross-Domain Generalization in Person Re-identification using Omni-Scale Network
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Cross-Lingual Text Image Recognition Via Multi-Task Sequence to Sequence Learning
Zhuo Chen, Fei Yin, Xu-Yao Zhang, Qing Yang, Cheng-Lin Liu

Auto-TLDR; Cross-Lingual Text Image Recognition with Multi-task Learning
Abstract Slides Poster Similar
Sequential Domain Adaptation through Elastic Weight Consolidation for Sentiment Analysis
Avinash Madasu, Anvesh Rao Vijjini

Auto-TLDR; Sequential Domain Adaptation using Elastic Weight Consolidation for Sentiment Analysis
Abstract Slides Poster Similar
A Simple Domain Shifting Network for Generating Low Quality Images
Guruprasad Hegde, Avinash Nittur Ramesh, Kanchana Vaishnavi Gandikota, Michael Möller, Roman Obermaisser

Auto-TLDR; Robotic Image Classification Using Quality degrading networks
Abstract Slides Poster Similar
Three-Dimensional Lip Motion Network for Text-Independent Speaker Recognition
Jianrong Wang, Tong Wu, Shanyu Wang, Mei Yu, Qiang Fang, Ju Zhang, Li Liu

Auto-TLDR; Lip Motion Network for Text-Independent and Text-Dependent Speaker Recognition
Abstract Slides Poster Similar
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Trajectory-User Link with Attention Recurrent Networks
Tao Sun, Yongjun Xu, Fei Wang, Lin Wu, 塘文 钱, Zezhi Shao

Auto-TLDR; TULAR: Trajectory-User Link with Attention Recurrent Neural Networks
Abstract Slides Poster Similar
A Few-Shot Learning Approach for Historical Ciphered Manuscript Recognition
Mohamed Ali Souibgui, Alicia Fornés, Yousri Kessentini, Crina Tudor

Auto-TLDR; Handwritten Ciphers Recognition Using Few-Shot Object Detection
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
GAP: Quantifying the Generative Adversarial Set and Class Feature Applicability of Deep Neural Networks
Edward Collier, Supratik Mukhopadhyay

Auto-TLDR; Approximating Adversarial Learning in Deep Neural Networks Using Set and Class Adversaries
Abstract Slides Poster Similar
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
Teacher-Student Competition for Unsupervised Domain Adaptation
Ruixin Xiao, Zhilei Liu, Baoyuan Wu

Auto-TLDR; Unsupervised Domain Adaption with Teacher-Student Competition
Abstract Slides Poster Similar
IBN-STR: A Robust Text Recognizer for Irregular Text in Natural Scenes
Xiaoqian Li, Jie Liu, Shuwu Zhang

Auto-TLDR; IBN-STR: A Robust Text Recognition System Based on Data and Feature Representation
Mobile Phone Surface Defect Detection Based on Improved Faster R-CNN
Tao Wang, Can Zhang, Runwei Ding, Ge Yang

Auto-TLDR; Faster R-CNN for Mobile Phone Surface Defect Detection
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
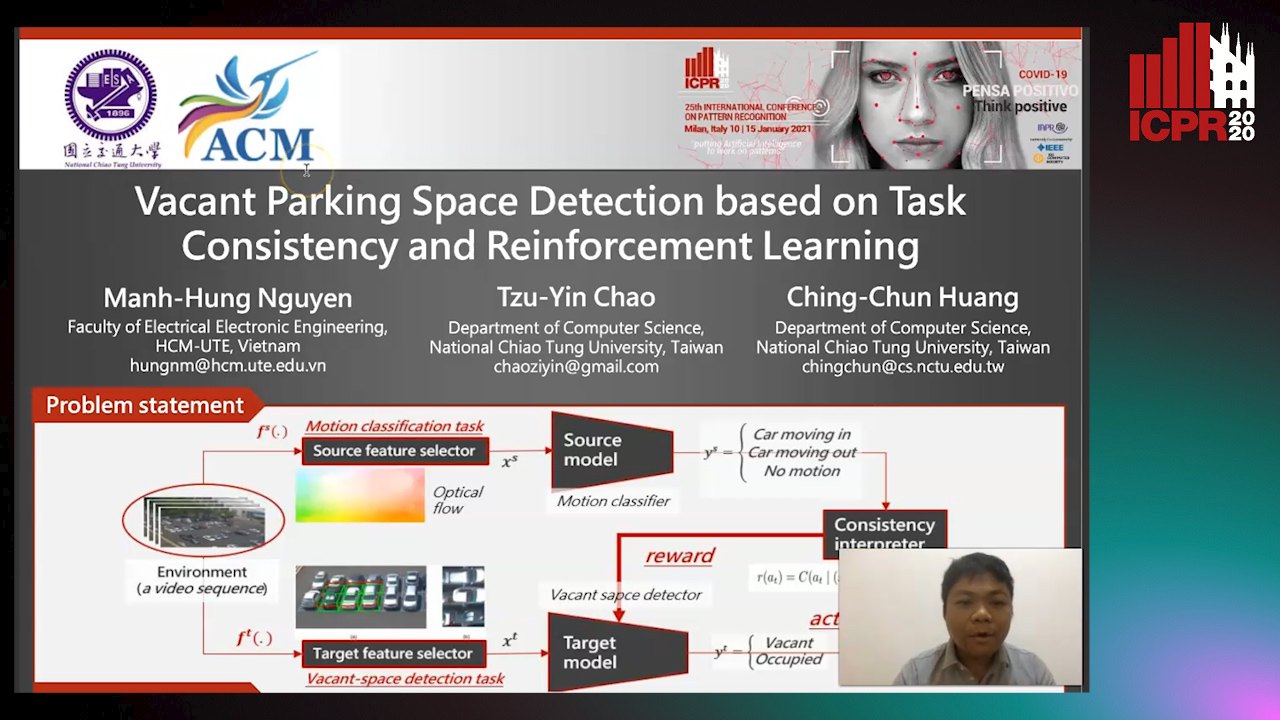
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Xingyu Yang, Mingyuan Meng, Shanlin Xiao, Zhiyi Yu

Auto-TLDR; Stochastic Probability Adjustment for Spiking Neural Networks
Abstract Slides Poster Similar