Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen,
Tzu-Yin Chao,
Ching-Chun Huang
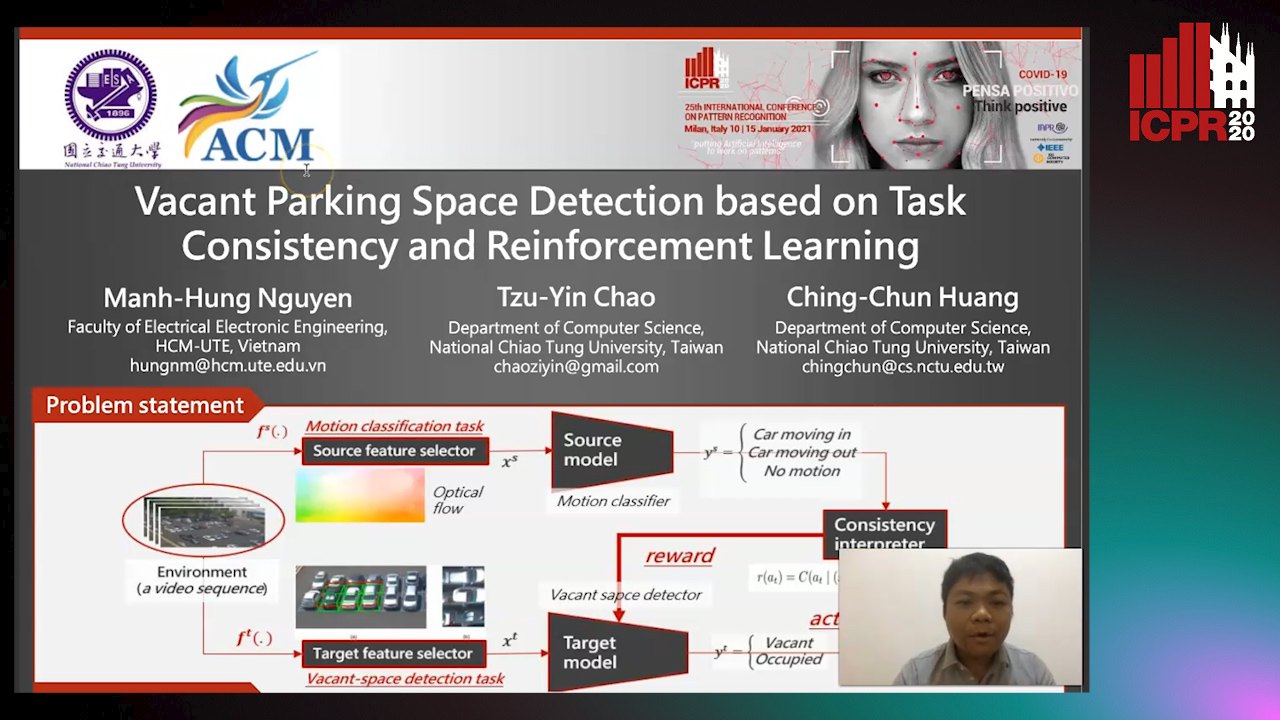
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Similar papers
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Hongli Zhou, Guanwen Zhang, Wei Zhou

Auto-TLDR; Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Abstract Slides Poster Similar
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Can Reinforcement Learning Lead to Healthy Life?: Simulation Study Based on User Activity Logs
Masami Takahashi, Masahiro Kohjima, Takeshi Kurashima, Hiroyuki Toda

Auto-TLDR; Reinforcement Learning for Healthy Daily Life
Abstract Slides Poster Similar
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
The Effect of Multi-Step Methods on Overestimation in Deep Reinforcement Learning
Lingheng Meng, Rob Gorbet, Dana Kulić

Auto-TLDR; Multi-Step DDPG for Deep Reinforcement Learning
Abstract Slides Poster Similar
Trajectory Representation Learning for Multi-Task NMRDP Planning
Firas Jarboui, Vianney Perchet

Auto-TLDR; Exploring Non Markovian Reward Decision Processes for Reinforcement Learning
Abstract Slides Poster Similar
Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Abstract Slides Poster Similar
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning without a Supercomputer
Edward Beeching, Jilles Steeve Dibangoye, Olivier Simonin, Christian Wolf

Auto-TLDR; Deep Reinforcement Learning in Mobile Robots Using 3D Environment Scenarios
Abstract Slides Poster Similar
Learning from Learners: Adapting Reinforcement Learning Agents to Be Competitive in a Card Game
Pablo Vinicius Alves De Barros, Ana Tanevska, Alessandra Sciutti

Auto-TLDR; Adaptive Reinforcement Learning for Competitive Card Games
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Nuo Xu, Chunlei Huo, Chunhong Pan

Auto-TLDR; Adaptive Image Attribute Learning for Active Object Detection
Explore and Explain: Self-Supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Exploring a Photorealistic Environment for Explanation and Navigation
AOAM: Automatic Optimization of Adjacency Matrix for Graph Convolutional Network
Yuhang Zhang, Hongshuai Ren, Jiexia Ye, Xitong Gao, Yang Wang, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Adjacency Matrix for Graph Convolutional Network in Non-Euclidean Space
Abstract Slides Poster Similar
Motion-Supervised Co-Part Segmentation
Aliaksandr Siarohin, Subhankar Roy, Stéphane Lathuiliere, Sergey Tulyakov, Elisa Ricci, Nicu Sebe

Auto-TLDR; Self-supervised Co-Part Segmentation Using Motion Information from Videos
Self-Play or Group Practice: Learning to Play Alternating Markov Game in Multi-Agent System
Chin-Wing Leung, Shuyue Hu, Ho-Fung Leung

Auto-TLDR; Group Practice for Deep Reinforcement Learning
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Deep Next-Best-View Planner for Cross-Season Visual Route Classification

Auto-TLDR; Active Visual Place Recognition using Deep Convolutional Neural Network
Abstract Slides Poster Similar
A Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Ruchika Chavhan, Biplab Banerjee, Xiao Xiang Zhu, Subhasis Chaudhuri

Auto-TLDR; Actor Dual-Critic Training for Remote Sensing Image Captioning Using Deep Reinforcement Learning
Abstract Slides Poster Similar
Online Object Recognition Using CNN-Based Algorithm on High-Speed Camera Imaging
Shigeaki Namiki, Keiko Yokoyama, Shoji Yachida, Takashi Shibata, Hiroyoshi Miyano, Masatoshi Ishikawa

Auto-TLDR; Real-Time Object Recognition with High-Speed Camera Imaging with Population Data Clearing and Data Ensemble
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
SynDHN: Multi-Object Fish Tracker Trained on Synthetic Underwater Videos
Mygel Andrei Martija, Prospero Naval

Auto-TLDR; Underwater Multi-Object Tracking in the Wild with Deep Hungarian Network
Abstract Slides Poster Similar
Semantic Segmentation for Pedestrian Detection from Motion in Temporal Domain

Auto-TLDR; Motion Profile: Recognizing Pedestrians along with their Motion Directions in a Temporal Way
Abstract Slides Poster Similar
SiamMT: Real-Time Arbitrary Multi-Object Tracking
Lorenzo Vaquero, Manuel Mucientes, Victor Brea

Auto-TLDR; SiamMT: A Deep-Learning-based Arbitrary Multi-Object Tracking System for Video
Abstract Slides Poster Similar
AVD-Net: Attention Value Decomposition Network for Deep Multi-Agent Reinforcement Learning
Zhang Yuanxin, Huimin Ma, Yu Wang

Auto-TLDR; Attention Value Decomposition Network for Cooperative Multi-agent Reinforcement Learning
Abstract Slides Poster Similar
Improving Visual Question Answering Using Active Perception on Static Images
Theodoros Bozinis, Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Fine-Grained Visual Question Answering with Reinforcement Learning-based Active Perception
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
RSINet: Rotation-Scale Invariant Network for Online Visual Tracking
Yang Fang, Geunsik Jo, Chang-Hee Lee

Auto-TLDR; RSINet: Rotation-Scale Invariant Network for Adaptive Tracking
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Uncertainty-Aware Data Augmentation for Food Recognition
Eduardo Aguilar, Bhalaji Nagarajan, Rupali Khatun, Marc Bolaños, Petia Radeva

Auto-TLDR; Data Augmentation for Food Recognition Using Epistemic Uncertainty
Abstract Slides Poster Similar
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
Knowledge Distillation for Action Anticipation Via Label Smoothing
Guglielmo Camporese, Pasquale Coscia, Antonino Furnari, Giovanni Maria Farinella, Lamberto Ballan

Auto-TLDR; A Multi-Modal Framework for Action Anticipation using Long Short-Term Memory Networks
Abstract Slides Poster Similar
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
Recurrent Deep Attention Network for Person Re-Identification
Changhao Wang, Jun Zhou, Xianfei Duan, Guanwen Zhang, Wei Zhou

Auto-TLDR; Recurrent Deep Attention Network for Person Re-identification
Abstract Slides Poster Similar
SSDL: Self-Supervised Domain Learning for Improved Face Recognition
Samadhi Poornima Kumarasinghe Wickrama Arachchilage, Ebroul Izquierdo

Auto-TLDR; Self-supervised Domain Learning for Face Recognition in unconstrained environments
Abstract Slides Poster Similar
On Embodied Visual Navigation in Real Environments through Habitat
Marco Rosano, Antonino Furnari, Luigi Gulino, Giovanni Maria Farinella

Auto-TLDR; Learning Navigation Policies on Real World Observations using Real World Images and Sensor and Actuation Noise
Abstract Slides Poster Similar
Temporally Coherent Embeddings for Self-Supervised Video Representation Learning
Joshua Knights, Ben Harwood, Daniel Ward, Anthony Vanderkop, Olivia Mackenzie-Ross, Peyman Moghadam

Auto-TLDR; Temporally Coherent Embeddings for Self-supervised Video Representation Learning
Abstract Slides Poster Similar
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
P-DIFF: Learning Classifier with Noisy Labels Based on Probability Difference Distributions
Wei Hu, Qihao Zhao, Yangyu Huang, Fan Zhang

Auto-TLDR; P-DIFF: A Simple and Effective Training Paradigm for Deep Neural Network Classifier with Noisy Labels
Abstract Slides Poster Similar
Learning with Delayed Feedback
Pranavan Theivendiram, Terence Sim

Auto-TLDR; Unsupervised Machine Learning with Delayed Feedback
Abstract Slides Poster Similar
Dual-Mode Iterative Denoiser: Tackling the Weak Label for Anomaly Detection

Auto-TLDR; A Dual-Mode Iterative Denoiser for Crowd Anomaly Detection
Abstract Slides Poster Similar
3D Attention Mechanism for Fine-Grained Classification of Table Tennis Strokes Using a Twin Spatio-Temporal Convolutional Neural Networks
Pierre-Etienne Martin, Jenny Benois-Pineau, Renaud Péteri, Julien Morlier

Auto-TLDR; Attentional Blocks for Action Recognition in Table Tennis Strokes
Abstract Slides Poster Similar