A Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Ruchika Chavhan,
Biplab Banerjee,
Xiao Xiang Zhu,
Subhasis Chaudhuri

Auto-TLDR; Actor Dual-Critic Training for Remote Sensing Image Captioning Using Deep Reinforcement Learning
Similar papers
Explore and Explain: Self-Supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Exploring a Photorealistic Environment for Explanation and Navigation
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Context Visual Information-Based Deliberation Network for Video Captioning
Min Lu, Xueyong Li, Caihua Liu

Auto-TLDR; Context visual information-based deliberation network for video captioning
Abstract Slides Poster Similar
Enriching Video Captions with Contextual Text
Philipp Rimle, Pelin Dogan, Markus Gross

Auto-TLDR; Contextualized Video Captioning Using Contextual Text
Abstract Slides Poster Similar
Visual Oriented Encoder: Integrating Multimodal and Multi-Scale Contexts for Video Captioning

Auto-TLDR; Visual Oriented Encoder for Video Captioning
Abstract Slides Poster Similar
Text Synopsis Generation for Egocentric Videos
Aidean Sharghi, Niels Lobo, Mubarak Shah

Auto-TLDR; Egocentric Video Summarization Using Multi-task Learning for End-to-End Learning
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
AVD-Net: Attention Value Decomposition Network for Deep Multi-Agent Reinforcement Learning
Zhang Yuanxin, Huimin Ma, Yu Wang

Auto-TLDR; Attention Value Decomposition Network for Cooperative Multi-agent Reinforcement Learning
Abstract Slides Poster Similar
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Tackling Contradiction Detection in German Using Machine Translation and End-To-End Recurrent Neural Networks
Maren Pielka, Rafet Sifa, Lars Patrick Hillebrand, David Biesner, Rajkumar Ramamurthy, Anna Ladi, Christian Bauckhage

Auto-TLDR; Contradiction Detection in Natural Language Inference using Recurrent Neural Networks
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
Learning with Delayed Feedback
Pranavan Theivendiram, Terence Sim

Auto-TLDR; Unsupervised Machine Learning with Delayed Feedback
Abstract Slides Poster Similar
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
The Effect of Multi-Step Methods on Overestimation in Deep Reinforcement Learning
Lingheng Meng, Rob Gorbet, Dana Kulić

Auto-TLDR; Multi-Step DDPG for Deep Reinforcement Learning
Abstract Slides Poster Similar
Integrating Historical States and Co-Attention Mechanism for Visual Dialog
Tianling Jiang, Yi Ji, Chunping Liu

Auto-TLDR; Integrating Historical States and Co-attention for Visual Dialog
Abstract Slides Poster Similar
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Learning from Learners: Adapting Reinforcement Learning Agents to Be Competitive in a Card Game
Pablo Vinicius Alves De Barros, Ana Tanevska, Alessandra Sciutti

Auto-TLDR; Adaptive Reinforcement Learning for Competitive Card Games
Abstract Slides Poster Similar
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning without a Supercomputer
Edward Beeching, Jilles Steeve Dibangoye, Olivier Simonin, Christian Wolf

Auto-TLDR; Deep Reinforcement Learning in Mobile Robots Using 3D Environment Scenarios
Abstract Slides Poster Similar
Improving Visual Question Answering Using Active Perception on Static Images
Theodoros Bozinis, Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Fine-Grained Visual Question Answering with Reinforcement Learning-based Active Perception
Abstract Slides Poster Similar
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
Global Context-Based Network with Transformer for Image2latex
Nuo Pang, Chun Yang, Xiaobin Zhu, Jixuan Li, Xu-Cheng Yin

Auto-TLDR; Image2latex with Global Context block and Transformer
Abstract Slides Poster Similar
Trajectory Representation Learning for Multi-Task NMRDP Planning
Firas Jarboui, Vianney Perchet

Auto-TLDR; Exploring Non Markovian Reward Decision Processes for Reinforcement Learning
Abstract Slides Poster Similar
Trajectory-User Link with Attention Recurrent Networks
Tao Sun, Yongjun Xu, Fei Wang, Lin Wu, 塘文 钱, Zezhi Shao

Auto-TLDR; TULAR: Trajectory-User Link with Attention Recurrent Neural Networks
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Cross-Lingual Text Image Recognition Via Multi-Task Sequence to Sequence Learning
Zhuo Chen, Fei Yin, Xu-Yao Zhang, Qing Yang, Cheng-Lin Liu

Auto-TLDR; Cross-Lingual Text Image Recognition with Multi-task Learning
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
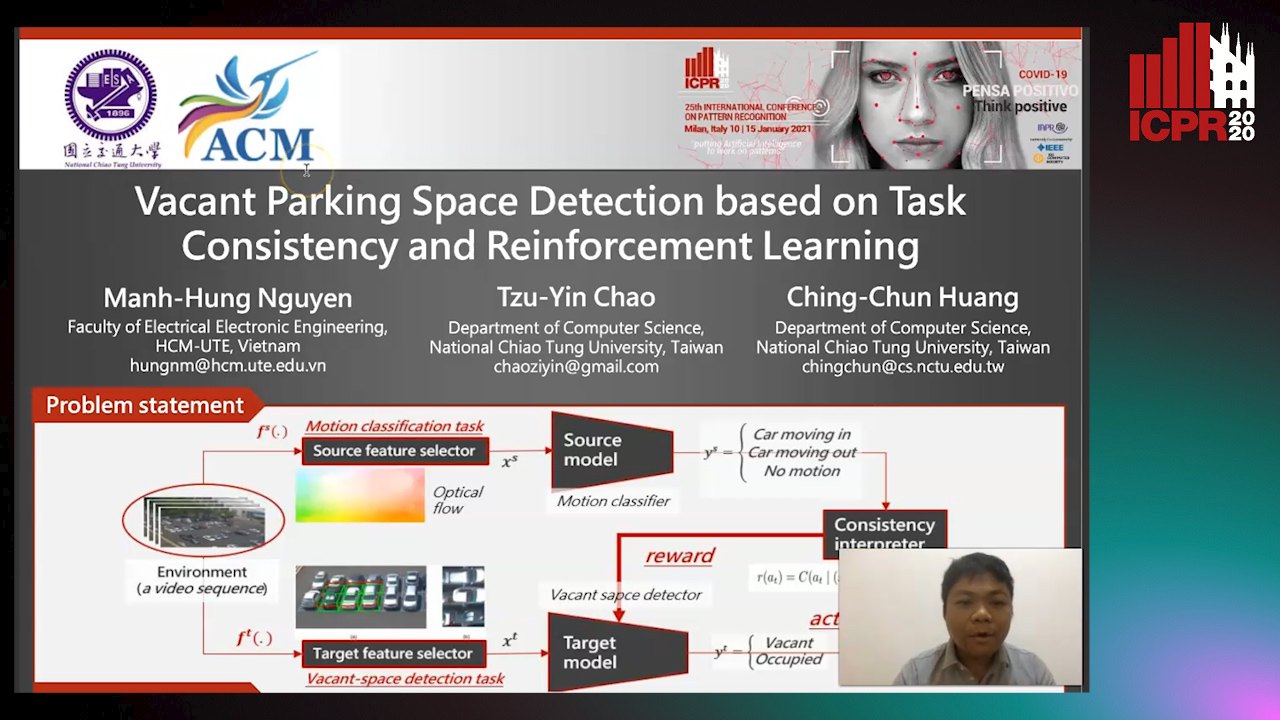
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
Multi-Stage Attention Based Visual Question Answering
Aakansha Mishra, Ashish Anand, Prithwijit Guha

Auto-TLDR; Alternative Bi-directional Attention for Visual Question Answering
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Li Ren, Kai Li, Liqiang Wang, Kien Hua

Auto-TLDR; Adversarial Discriminative Domain Regularization for Efficient Cross-Modal Matching
Abstract Slides Poster Similar
DAG-Net: Double Attentive Graph Neural Network for Trajectory Forecasting
Alessio Monti, Alessia Bertugli, Simone Calderara, Rita Cucchiara

Auto-TLDR; Recurrent Generative Model for Multi-modal Human Motion Behaviour in Urban Environments
Abstract Slides Poster Similar
Efficient Sentence Embedding Via Semantic Subspace Analysis
Bin Wang, Fenxiao Chen, Yun Cheng Wang, C.-C. Jay Kuo

Auto-TLDR; S3E: Semantic Subspace Sentence Embedding
Abstract Slides Poster Similar
The Color Out of Space: Learning Self-Supervised Representations for Earth Observation Imagery
Stefano Vincenzi, Angelo Porrello, Pietro Buzzega, Marco Cipriano, Pietro Fronte, Roberto Cuccu, Carla Ippoliti, Annamaria Conte, Simone Calderara

Auto-TLDR; Satellite Image Representation Learning for Remote Sensing
Abstract Slides Poster Similar
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Hyunjae Lee, Jaewoong Yun, Bongkyu Hwang, Seongho Joe, Seungjai Min, Youngjune Gwon

Auto-TLDR; KoreALBERT: A monolingual ALBERT model for Korean language understanding
Abstract Slides Poster Similar
Recurrent Deep Attention Network for Person Re-Identification
Changhao Wang, Jun Zhou, Xianfei Duan, Guanwen Zhang, Wei Zhou

Auto-TLDR; Recurrent Deep Attention Network for Person Re-identification
Abstract Slides Poster Similar
Information Graphic Summarization Using a Collection of Multimodal Deep Neural Networks
Edward Kim, Connor Onweller, Kathleen F. Mccoy

Auto-TLDR; A multimodal deep learning framework that can generate summarization text supporting the main idea of an information graphic for presentation to blind or visually impaired
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
The Role of Cycle Consistency for Generating Better Human Action Videos from a Single Frame

Auto-TLDR; Generating Videos with Human Action Semantics using Cycle Constraints
Abstract Slides Poster Similar
Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Abstract Slides Poster Similar
AOAM: Automatic Optimization of Adjacency Matrix for Graph Convolutional Network
Yuhang Zhang, Hongshuai Ren, Jiexia Ye, Xitong Gao, Yang Wang, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Adjacency Matrix for Graph Convolutional Network in Non-Euclidean Space
Abstract Slides Poster Similar
ConvMath : A Convolutional Sequence Network for Mathematical Expression Recognition
Zuoyu Yan, Xiaode Zhang, Liangcai Gao, Ke Yuan, Zhi Tang

Auto-TLDR; Convolutional Sequence Modeling for Mathematical Expressions Recognition
Abstract Slides Poster Similar