Improving Visual Question Answering Using Active Perception on Static Images
Theodoros Bozinis,
Nikolaos Passalis,
Anastasios Tefas

Auto-TLDR; Fine-Grained Visual Question Answering with Reinforcement Learning-based Active Perception
Similar papers
Question-Agnostic Attention for Visual Question Answering
Moshiur R Farazi, Salman Hameed Khan, Nick Barnes

Auto-TLDR; Question-Agnostic Attention for Visual Question Answering
Abstract Slides Poster Similar
Multi-Stage Attention Based Visual Question Answering
Aakansha Mishra, Ashish Anand, Prithwijit Guha

Auto-TLDR; Alternative Bi-directional Attention for Visual Question Answering
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
P ≈ NP, at Least in Visual Question Answering
Shailza Jolly, Sebastian Palacio, Joachim Folz, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Polar vs Non-Polar VQA: A Cross-over Analysis of Feature Spaces for Joint Training
Multi-Scale Relational Reasoning with Regional Attention for Visual Question Answering

Auto-TLDR; Question-Guided Relational Reasoning for Visual Question Answering
Abstract Slides Poster Similar
Multi-Modal Contextual Graph Neural Network for Text Visual Question Answering
Yaoyuan Liang, Xin Wang, Xuguang Duan, Wenwu Zhu

Auto-TLDR; Multi-modal Contextual Graph Neural Network for Text Visual Question Answering
Abstract Slides Poster Similar
Integrating Historical States and Co-Attention Mechanism for Visual Dialog
Tianling Jiang, Yi Ji, Chunping Liu

Auto-TLDR; Integrating Historical States and Co-attention for Visual Dialog
Abstract Slides Poster Similar
Graph Discovery for Visual Test Generation
Neil Hallonquist, Laurent Younes, Donald Geman

Auto-TLDR; Visual Question Answering over Graphs: A Probabilistic Framework for VQA
Abstract Slides Poster Similar
Explore and Explain: Self-Supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Exploring a Photorealistic Environment for Explanation and Navigation
Answer-Checking in Context: A Multi-Modal Fully Attention Network for Visual Question Answering
Hantao Huang, Tao Han, Wei Han, Deep Yap Deep Yap, Cheng-Ming Chiang

Auto-TLDR; Fully Attention Based Visual Question Answering
Abstract Slides Poster Similar
A Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Ruchika Chavhan, Biplab Banerjee, Xiao Xiang Zhu, Subhasis Chaudhuri

Auto-TLDR; Actor Dual-Critic Training for Remote Sensing Image Captioning Using Deep Reinforcement Learning
Abstract Slides Poster Similar
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
Visual Style Extraction from Chart Images for Chart Restyling
Danqing Huang, Jinpeng Wang, Guoxin Wang, Chin-Yew Lin

Auto-TLDR; Exploiting Visual Properties from Reference Chart Images for Chart Restyling
Abstract Slides Poster Similar
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning without a Supercomputer
Edward Beeching, Jilles Steeve Dibangoye, Olivier Simonin, Christian Wolf

Auto-TLDR; Deep Reinforcement Learning in Mobile Robots Using 3D Environment Scenarios
Abstract Slides Poster Similar
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
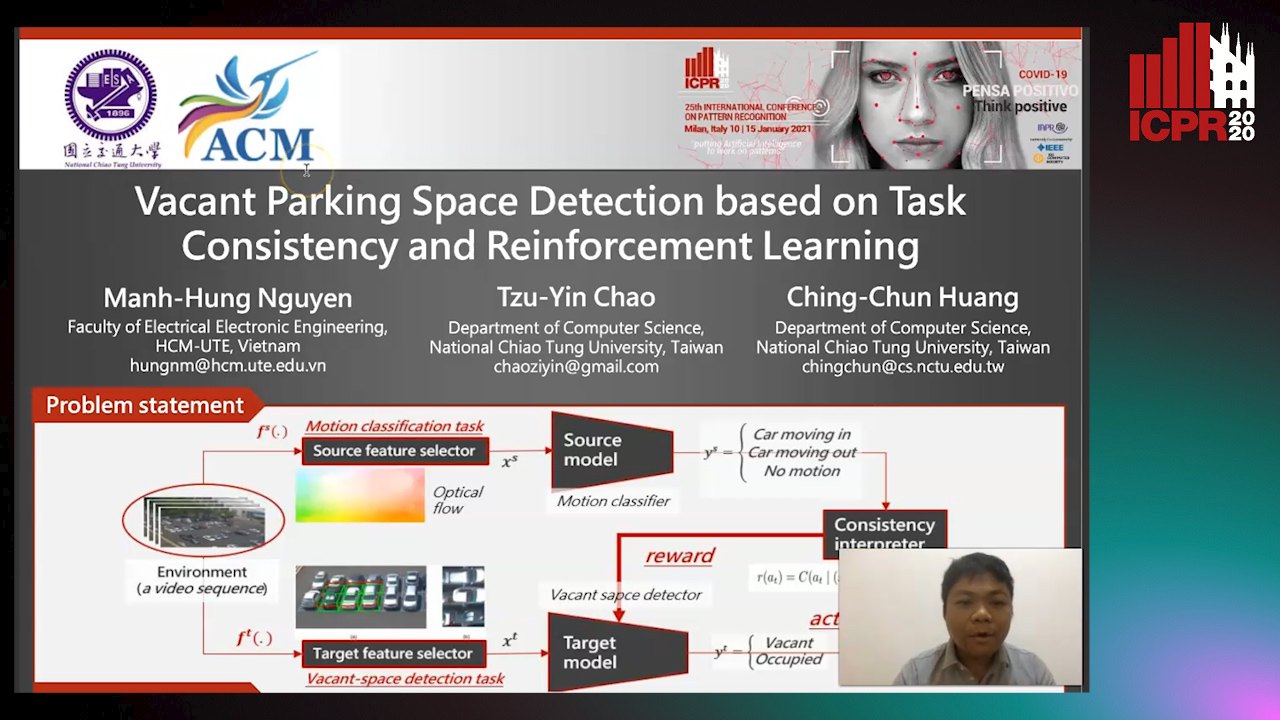
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Nuo Xu, Chunlei Huo, Chunhong Pan

Auto-TLDR; Adaptive Image Attribute Learning for Active Object Detection
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Learning from Learners: Adapting Reinforcement Learning Agents to Be Competitive in a Card Game
Pablo Vinicius Alves De Barros, Ana Tanevska, Alessandra Sciutti

Auto-TLDR; Adaptive Reinforcement Learning for Competitive Card Games
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
SAILenv: Learning in Virtual Visual Environments Made Simple
Enrico Meloni, Luca Pasqualini, Matteo Tiezzi, Marco Gori, Stefano Melacci

Auto-TLDR; SAILenv: A Simple and Customized Platform for Visual Recognition in Virtual 3D Environment
Abstract Slides Poster Similar
The Effect of Multi-Step Methods on Overestimation in Deep Reinforcement Learning
Lingheng Meng, Rob Gorbet, Dana Kulić

Auto-TLDR; Multi-Step DDPG for Deep Reinforcement Learning
Abstract Slides Poster Similar
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Information Graphic Summarization Using a Collection of Multimodal Deep Neural Networks
Edward Kim, Connor Onweller, Kathleen F. Mccoy

Auto-TLDR; A multimodal deep learning framework that can generate summarization text supporting the main idea of an information graphic for presentation to blind or visually impaired
Can Reinforcement Learning Lead to Healthy Life?: Simulation Study Based on User Activity Logs
Masami Takahashi, Masahiro Kohjima, Takeshi Kurashima, Hiroyuki Toda

Auto-TLDR; Reinforcement Learning for Healthy Daily Life
Abstract Slides Poster Similar
Leveraging Quadratic Spherical Mutual Information Hashing for Fast Image Retrieval
Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Quadratic Mutual Information for Large-Scale Hashing and Information Retrieval
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Hongli Zhou, Guanwen Zhang, Wei Zhou

Auto-TLDR; Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Abstract Slides Poster Similar
Learning with Delayed Feedback
Pranavan Theivendiram, Terence Sim

Auto-TLDR; Unsupervised Machine Learning with Delayed Feedback
Abstract Slides Poster Similar
Exploring and Exploiting the Hierarchical Structure of a Scene for Scene Graph Generation
Ikuto Kurosawa, Tetsunori Kobayashi, Yoshihiko Hayashi

Auto-TLDR; A Hierarchical Model for Scene Graph Generation
Abstract Slides Poster Similar
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Abstract Slides Poster Similar
AOAM: Automatic Optimization of Adjacency Matrix for Graph Convolutional Network
Yuhang Zhang, Hongshuai Ren, Jiexia Ye, Xitong Gao, Yang Wang, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Adjacency Matrix for Graph Convolutional Network in Non-Euclidean Space
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
On Embodied Visual Navigation in Real Environments through Habitat
Marco Rosano, Antonino Furnari, Luigi Gulino, Giovanni Maria Farinella

Auto-TLDR; Learning Navigation Policies on Real World Observations using Real World Images and Sensor and Actuation Noise
Abstract Slides Poster Similar
Enhanced User Interest and Expertise Modeling for Expert Recommendation
Tongze He, Caili Guo, Yunfei Chu

Auto-TLDR; A Unified Framework for Expert Recommendation in Community Question Answering
Abstract Slides Poster Similar
Improving Visual Relation Detection Using Depth Maps
Sahand Sharifzadeh, Sina Moayed Baharlou, Max Berrendorf, Rajat Koner, Volker Tresp

Auto-TLDR; Exploiting Depth Maps for Visual Relation Detection
Abstract Slides Poster Similar
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
Spatial Bias in Vision-Based Voice Activity Detection
Kalin Stefanov, Mohammad Adiban, Giampiero Salvi

Auto-TLDR; Spatial Bias in Vision-based Voice Activity Detection in Multiparty Human-Human Interactions
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
A Generalizable Saliency Map-Based Interpretation of Model Outcome
Shailja Thakur, Sebastian Fischmeister

Auto-TLDR; Interpretability of Deep Neural Networks Using Salient Input and Output
6D Pose Estimation with Correlation Fusion
Yi Cheng, Hongyuan Zhu, Ying Sun, Cihan Acar, Wei Jing, Yan Wu, Liyuan Li, Cheston Tan, Joo-Hwee Lim

Auto-TLDR; Intra- and Inter-modality Fusion for 6D Object Pose Estimation with Attention Mechanism
Abstract Slides Poster Similar