Can Reinforcement Learning Lead to Healthy Life?: Simulation Study Based on User Activity Logs
Masami Takahashi,
Masahiro Kohjima,
Takeshi Kurashima,
Hiroyuki Toda

Auto-TLDR; Reinforcement Learning for Healthy Daily Life
Similar papers
The Effect of Multi-Step Methods on Overestimation in Deep Reinforcement Learning
Lingheng Meng, Rob Gorbet, Dana Kulić

Auto-TLDR; Multi-Step DDPG for Deep Reinforcement Learning
Abstract Slides Poster Similar
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
Trajectory Representation Learning for Multi-Task NMRDP Planning
Firas Jarboui, Vianney Perchet

Auto-TLDR; Exploring Non Markovian Reward Decision Processes for Reinforcement Learning
Abstract Slides Poster Similar
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning without a Supercomputer
Edward Beeching, Jilles Steeve Dibangoye, Olivier Simonin, Christian Wolf

Auto-TLDR; Deep Reinforcement Learning in Mobile Robots Using 3D Environment Scenarios
Abstract Slides Poster Similar
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
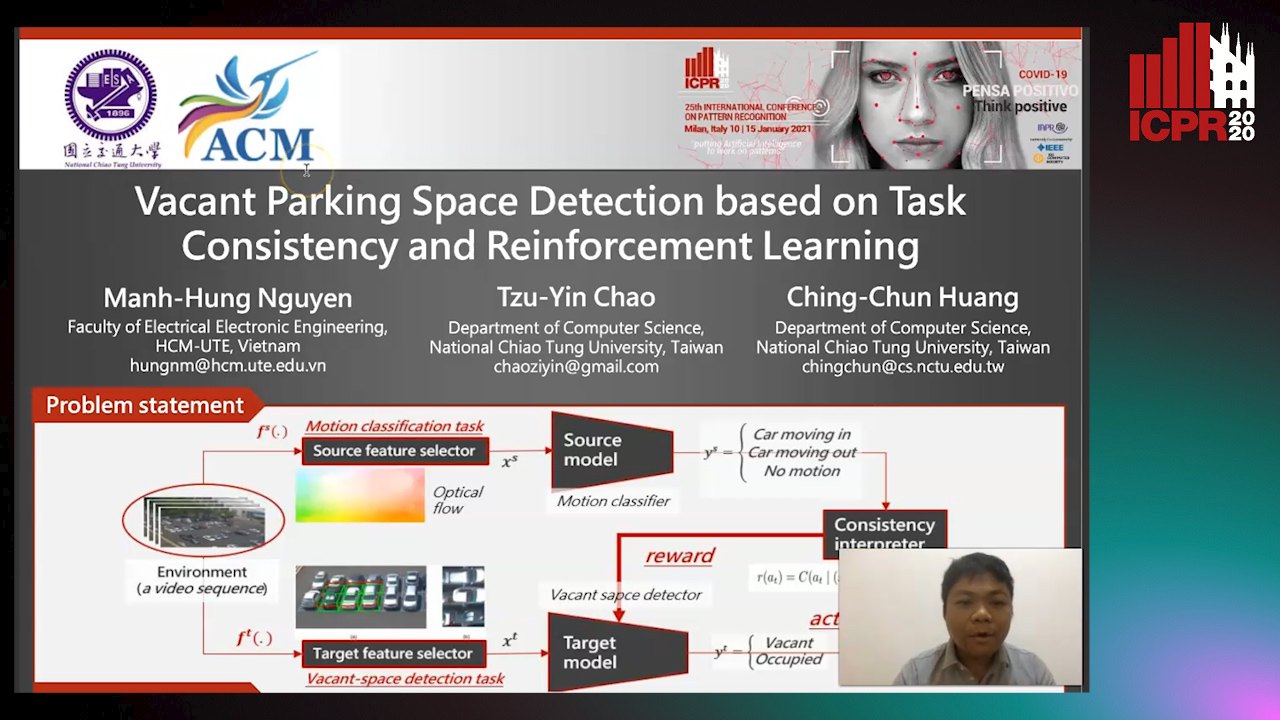
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
AOAM: Automatic Optimization of Adjacency Matrix for Graph Convolutional Network
Yuhang Zhang, Hongshuai Ren, Jiexia Ye, Xitong Gao, Yang Wang, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Adjacency Matrix for Graph Convolutional Network in Non-Euclidean Space
Abstract Slides Poster Similar
AVD-Net: Attention Value Decomposition Network for Deep Multi-Agent Reinforcement Learning
Zhang Yuanxin, Huimin Ma, Yu Wang

Auto-TLDR; Attention Value Decomposition Network for Cooperative Multi-agent Reinforcement Learning
Abstract Slides Poster Similar
Self-Play or Group Practice: Learning to Play Alternating Markov Game in Multi-Agent System
Chin-Wing Leung, Shuyue Hu, Ho-Fung Leung

Auto-TLDR; Group Practice for Deep Reinforcement Learning
Abstract Slides Poster Similar
Learning from Learners: Adapting Reinforcement Learning Agents to Be Competitive in a Card Game
Pablo Vinicius Alves De Barros, Ana Tanevska, Alessandra Sciutti

Auto-TLDR; Adaptive Reinforcement Learning for Competitive Card Games
Abstract Slides Poster Similar
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Nuo Xu, Chunlei Huo, Chunhong Pan

Auto-TLDR; Adaptive Image Attribute Learning for Active Object Detection
Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Hongli Zhou, Guanwen Zhang, Wei Zhou

Auto-TLDR; Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Abstract Slides Poster Similar
Location Prediction in Real Homes of Older Adults based on K-Means in Low-Resolution Depth Videos
Simon Simonsson, Flávia Dias Casagrande, Evi Zouganeli

Auto-TLDR; Semi-supervised Learning for Location Recognition and Prediction in Smart Homes using Depth Video Cameras
Abstract Slides Poster Similar
Explore and Explain: Self-Supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Exploring a Photorealistic Environment for Explanation and Navigation
A Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Ruchika Chavhan, Biplab Banerjee, Xiao Xiang Zhu, Subhasis Chaudhuri

Auto-TLDR; Actor Dual-Critic Training for Remote Sensing Image Captioning Using Deep Reinforcement Learning
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Anticipating Activity from Multimodal Signals
Tiziana Rotondo, Giovanni Maria Farinella, Davide Giacalone, Sebastiano Mauro Strano, Valeria Tomaselli, Sebastiano Battiato

Auto-TLDR; Exploiting Multimodal Signal Embedding Space for Multi-Action Prediction
Abstract Slides Poster Similar
Deep Next-Best-View Planner for Cross-Season Visual Route Classification

Auto-TLDR; Active Visual Place Recognition using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Switching Dynamical Systems with Deep Neural Networks
Cesar Ali Ojeda Marin, Kostadin Cvejoski, Bogdan Georgiev, Ramses J. Sanchez

Auto-TLDR; Variational RNN for Switching Dynamics
Abstract Slides Poster Similar
Active Sampling for Pairwise Comparisons via Approximate Message Passing and Information Gain Maximization
Aliaksei Mikhailiuk, Clifford Wilmot, Maria Perez-Ortiz, Dingcheng Yue, Rafal Mantiuk

Auto-TLDR; ASAP: An Active Sampling Algorithm for Pairwise Comparison Data
Seasonal Inhomogeneous Nonconsecutive Arrival Process Search and Evaluation
Kimberly Holmgren, Paul Gibby, Joseph Zipkin

Auto-TLDR; SINAPSE: Fitting a Sparse Time Series Model to Seasonal Data
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Improving Visual Question Answering Using Active Perception on Static Images
Theodoros Bozinis, Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Fine-Grained Visual Question Answering with Reinforcement Learning-based Active Perception
Abstract Slides Poster Similar
Conditional-UNet: A Condition-Aware Deep Model for Coherent Human Activity Recognition from Wearables
Liming Zhang, Wenbin Zhang, Nathalie Japkowicz

Auto-TLDR; Coherent Human Activity Recognition from Multi-Channel Time Series Data
Abstract Slides Poster Similar
Uncertainty-Sensitive Activity Recognition: A Reliability Benchmark and the CARING Models
Alina Roitberg, Monica Haurilet, Manuel Martinez, Rainer Stiefelhagen

Auto-TLDR; CARING: Calibrated Action Recognition with Input Guidance
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
Recurrent Deep Attention Network for Person Re-Identification
Changhao Wang, Jun Zhou, Xianfei Duan, Guanwen Zhang, Wei Zhou

Auto-TLDR; Recurrent Deep Attention Network for Person Re-identification
Abstract Slides Poster Similar
Video Analytics Gait Trend Measurement for Fall Prevention and Health Monitoring
Lawrence O'Gorman, Xinyi Liu, Md Imran Sarker, Mariofanna Milanova

Auto-TLDR; Towards Health Monitoring of Gait with Deep Learning
Abstract Slides Poster Similar
Extracting and Interpreting Unknown Factors with Classifier for Foot Strike Types in Running
Chanjin Seo, Masato Sabanai, Yuta Goto, Koji Tagami, Hiroyuki Ogata, Kazuyuki Kanosue, Jun Ohya

Auto-TLDR; Deep Learning for Foot Strike Classification using Accelerometer Data
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Assessing the Severity of Health States Based on Social Media Posts
Shweta Yadav, Joy Prakash Sain, Amit Sheth, Asif Ekbal, Sriparna Saha, Pushpak Bhattacharyya

Auto-TLDR; A Multiview Learning Framework for Assessment of Health State in Online Health Communities
Abstract Slides Poster Similar
Conditional Multi-Task Learning for Plant Disease Identification
Sue Han Lee, Herve Goëau, Pierre Bonnet, Alexis Joly

Auto-TLDR; A conditional multi-task learning approach for plant disease identification
Abstract Slides Poster Similar
End-To-End Multi-Task Learning of Missing Value Imputation and Forecasting in Time-Series Data
Jinhee Kim, Taesung Kim, Jang-Ho Choi, Jaegul Choo

Auto-TLDR; Time-Series Prediction with Denoising and Imputation of Missing Data
Abstract Slides Poster Similar
Probabilistic Latent Factor Model for Collaborative Filtering with Bayesian Inference
Jiansheng Fang, Xiaoqing Zhang, Yan Hu, Yanwu Xu, Ming Yang, Jiang Liu

Auto-TLDR; Bayesian Latent Factor Model for Collaborative Filtering
E-DNAS: Differentiable Neural Architecture Search for Embedded Systems
Javier García López, Antonio Agudo, Francesc Moreno-Noguer

Auto-TLDR; E-DNAS: Differentiable Architecture Search for Light-Weight Networks for Image Classification
Abstract Slides Poster Similar
Learning Parameter Distributions to Detect Concept Drift in Data Streams
Johannes Haug, Gjergji Kasneci

Auto-TLDR; A novel framework for the detection of concept drift in streaming environments
Abstract Slides Poster Similar
XGBoost to Interpret the Opioid Patients’ StateBased on Cognitive and Physiological Measures
Arash Shokouhmand, Omid Dehzangi, Jad Ramadan, Victor Finomore, Nasser M. Nasarabadi, Ali Rezai
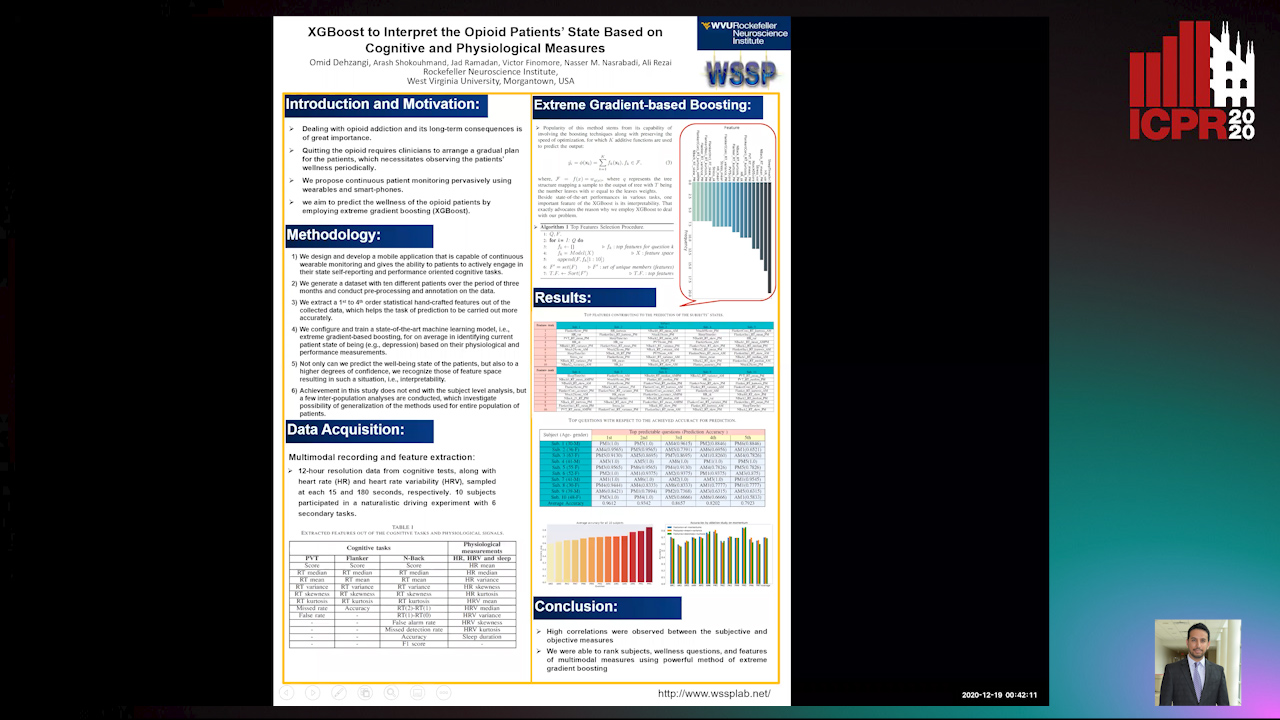
Auto-TLDR; Predicting the Wellness of Opioid Addictions Using Multi-modal Sensor Data
Using Machine Learning to Refer Patients with Chronic Kidney Disease to Secondary Care
Lee Au-Yeung, Xianghua Xie, Timothy Marcus Scale, James Anthony Chess

Auto-TLDR; A Machine Learning Approach for Chronic Kidney Disease Prediction using Blood Test Data
Abstract Slides Poster Similar
Trajectory-User Link with Attention Recurrent Networks
Tao Sun, Yongjun Xu, Fei Wang, Lin Wu, 塘文 钱, Zezhi Shao

Auto-TLDR; TULAR: Trajectory-User Link with Attention Recurrent Neural Networks
Abstract Slides Poster Similar
VOWEL: A Local Online Learning Rule for Recurrent Networks of Probabilistic Spiking Winner-Take-All Circuits
Hyeryung Jang, Nicolas Skatchkovsky, Osvaldo Simeone

Auto-TLDR; VOWEL: A Variational Online Local Training Rule for Winner-Take-All Spiking Neural Networks
On Embodied Visual Navigation in Real Environments through Habitat
Marco Rosano, Antonino Furnari, Luigi Gulino, Giovanni Maria Farinella

Auto-TLDR; Learning Navigation Policies on Real World Observations using Real World Images and Sensor and Actuation Noise
Abstract Slides Poster Similar
DAG-Net: Double Attentive Graph Neural Network for Trajectory Forecasting
Alessio Monti, Alessia Bertugli, Simone Calderara, Rita Cucchiara

Auto-TLDR; Recurrent Generative Model for Multi-modal Human Motion Behaviour in Urban Environments
Abstract Slides Poster Similar