Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Nuo Xu,
Chunlei Huo,
Chunhong Pan

Auto-TLDR; Adaptive Image Attribute Learning for Active Object Detection
Similar papers
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Forground-Guided Vehicle Perception Framework
Kun Tian, Tong Zhou, Shiming Xiang, Chunhong Pan

Auto-TLDR; A foreground segmentation branch for vehicle detection
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
EDD-Net: An Efficient Defect Detection Network
Tianyu Guo, Linlin Zhang, Runwei Ding, Ge Yang

Auto-TLDR; EfficientNet: Efficient Network for Mobile Phone Surface defect Detection
Abstract Slides Poster Similar
Tiny Object Detection in Aerial Images
Jinwang Wang, Wen Yang, Haowen Guo, Ruixiang Zhang, Gui-Song Xia

Auto-TLDR; Tiny Object Detection in Aerial Images Using Multiple Center Points Based Learning Network
Mobile Phone Surface Defect Detection Based on Improved Faster R-CNN
Tao Wang, Can Zhang, Runwei Ding, Ge Yang

Auto-TLDR; Faster R-CNN for Mobile Phone Surface Defect Detection
Abstract Slides Poster Similar
Small Object Detection by Generative and Discriminative Learning
Yi Gu, Jie Li, Chentao Wu, Weijia Jia, Jianping Chen

Auto-TLDR; Generative and Discriminative Learning for Small Object Detection
Abstract Slides Poster Similar
Bidirectional Matrix Feature Pyramid Network for Object Detection

Auto-TLDR; BMFPN: Bidirectional Matrix Feature Pyramid Network for Object Detection
Abstract Slides Poster Similar
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
NAS-EOD: An End-To-End Neural Architecture Search Method for Efficient Object Detection
Huigang Zhang, Liuan Wang, Jun Sun, Li Sun, Hiromichi Kobashi, Nobutaka Imamura

Auto-TLDR; NAS-EOD: Neural Architecture Search for Object Detection on Edge Devices
P2 Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Luanxuan Hou, Jie Cao, Yuan Zhao, Haifeng Shen, Jian Tang, Ran He

Auto-TLDR; Parallel-Pyramid Net with Partial Attention for Human Pose Estimation
Abstract Slides Poster Similar
EAGLE: Large-Scale Vehicle Detection Dataset in Real-World Scenarios Using Aerial Imagery
Seyed Majid Azimi, Reza Bahmanyar, Corentin Henry, Kurz Franz

Auto-TLDR; EAGLE: A Large-Scale Dataset for Multi-class Vehicle Detection with Object Orientation Information in Airborne Imagery
MagnifierNet: Learning Efficient Small-Scale Pedestrian Detector towards Multiple Dense Regions
Qi Cheng, Mingqin Chen, Yingjie Wu, Fei Chen, Shiping Lin

Auto-TLDR; MagnifierNet: A Simple but Effective Small-Scale Pedestrian Detection Towards Multiple Dense Regions
Abstract Slides Poster Similar
Hybrid Cascade Point Search Network for High Precision Bar Chart Component Detection
Junyu Luo, Jinpeng Wang, Chin-Yew Lin

Auto-TLDR; Object Detection of Chart Components in Chart Images Using Point-based and Region-Based Object Detection Framework
Abstract Slides Poster Similar
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
AOAM: Automatic Optimization of Adjacency Matrix for Graph Convolutional Network
Yuhang Zhang, Hongshuai Ren, Jiexia Ye, Xitong Gao, Yang Wang, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Adjacency Matrix for Graph Convolutional Network in Non-Euclidean Space
Abstract Slides Poster Similar
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
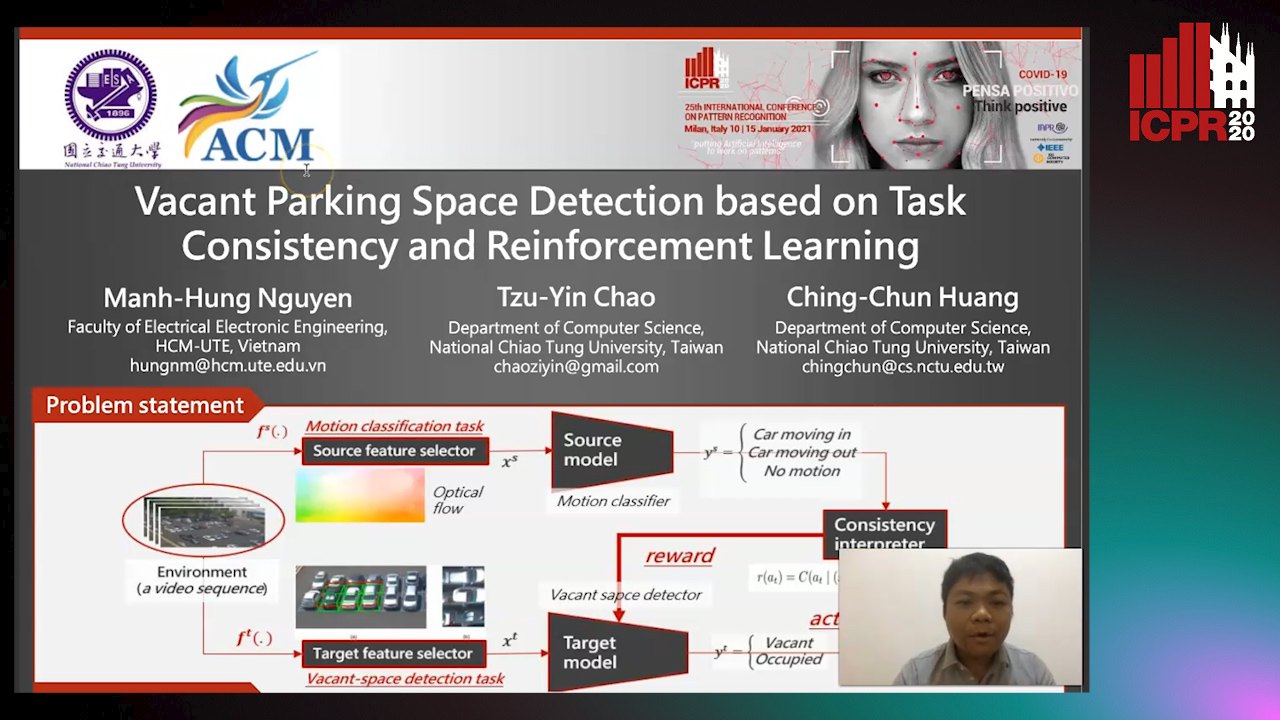
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
ScarfNet: Multi-Scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Jin Hyeok Yoo, Dongsuk Kum, Jun Won Choi

Auto-TLDR; Semantic Fusion of Multi-scale Feature Maps for Object Detection
Abstract Slides Poster Similar
Learning from Learners: Adapting Reinforcement Learning Agents to Be Competitive in a Card Game
Pablo Vinicius Alves De Barros, Ana Tanevska, Alessandra Sciutti

Auto-TLDR; Adaptive Reinforcement Learning for Competitive Card Games
Abstract Slides Poster Similar
Multiple-Step Sampling for Dense Object Detection and Counting

Auto-TLDR; Multiple-Step Sampling for Dense Objects Detection
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
AVD-Net: Attention Value Decomposition Network for Deep Multi-Agent Reinforcement Learning
Zhang Yuanxin, Huimin Ma, Yu Wang

Auto-TLDR; Attention Value Decomposition Network for Cooperative Multi-agent Reinforcement Learning
Abstract Slides Poster Similar
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
SyNet: An Ensemble Network for Object Detection in UAV Images

Auto-TLDR; SyNet: Combining Multi-Stage and Single-Stage Object Detection for Aerial Images
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning without a Supercomputer
Edward Beeching, Jilles Steeve Dibangoye, Olivier Simonin, Christian Wolf

Auto-TLDR; Deep Reinforcement Learning in Mobile Robots Using 3D Environment Scenarios
Abstract Slides Poster Similar
Object Detection in the DCT Domain: Is Luminance the Solution?
Benjamin Deguerre, Clement Chatelain, Gilles Gasso

Auto-TLDR; Jpeg Deep: Object Detection Using Compressed JPEG Images
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
CenterRepp: Predict Central Representative Point Set's Distribution for Detection
Yulin He, Limeng Zhang, Wei Chen, Xin Luo, Chen Li, Xiaogang Jia

Auto-TLDR; CRPDet: CenterRepp Detector for Object Detection
Abstract Slides Poster Similar
Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Dayang Yu, Rong Zhang, Shan Qin

Auto-TLDR; Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Abstract Slides Poster Similar
Which Airline Is This? Airline Logo Detection in Real-World Weather Conditions
Christian Wilms, Rafael Heid, Mohammad Araf Sadeghi, Andreas Ribbrock, Simone Frintrop

Auto-TLDR; Airlines logo detection on airplane tails using data augmentation
Abstract Slides Poster Similar
Object Detection Using Dual Graph Network
Shengjia Chen, Zhixin Li, Feicheng Huang, Canlong Zhang, Huifang Ma

Auto-TLDR; A Graph Convolutional Network for Object Detection with Key Relation Information
Cross-View Relation Networks for Mammogram Mass Detection
Ma Jiechao, Xiang Li, Hongwei Li, Ruixuan Wang, Bjoern Menze, Wei-Shi Zheng

Auto-TLDR; Multi-view Modeling for Mass Detection in Mammogram
Abstract Slides Poster Similar
Small Object Detection Leveraging on Simultaneous Super-Resolution
Hong Ji, Zhi Gao, Xiaodong Liu, Tiancan Mei

Auto-TLDR; Super-Resolution via Generative Adversarial Network for Small Object Detection
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Object Features and Face Detection Performance: Analyses with 3D-Rendered Synthetic Data
Jian Han, Sezer Karaoglu, Hoang-An Le, Theo Gevers

Auto-TLDR; Synthetic Data for Face Detection Using 3DU Face Dataset
Abstract Slides Poster Similar
PRF-Ped: Multi-Scale Pedestrian Detector with Prior-Based Receptive Field
Yuzhi Tan, Hongxun Yao, Haoran Li, Xiusheng Lu, Haozhe Xie

Auto-TLDR; Bidirectional Feature Enhancement Module for Multi-Scale Pedestrian Detection
Abstract Slides Poster Similar