Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi,
Hajer Fradi,
Anis Sahbani,
Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Similar papers
Robust Pedestrian Detection in Thermal Imagery Using Synthesized Images
My Kieu, Lorenzo Berlincioni, Leonardo Galteri, Marco Bertini, Andrew Bagdanov, Alberto Del Bimbo

Auto-TLDR; Improving Pedestrian Detection in the thermal domain using Generative Adversarial Network
Abstract Slides Poster Similar
Boundary Guided Image Translation for Pose Estimation from Ultra-Low Resolution Thermal Sensor
Kohei Kurihara, Tianren Wang, Teng Zhang, Brian Carrington Lovell

Auto-TLDR; Pose Estimation on Low-Resolution Thermal Images Using Image-to-Image Translation Architecture
Abstract Slides Poster Similar
Super-Resolution Guided Pore Detection for Fingerprint Recognition
Syeda Nyma Ferdous, Ali Dabouei, Jeremy Dawson, Nasser M. Nasarabadi

Auto-TLDR; Super-Resolution Generative Adversarial Network for Fingerprint Recognition Using Pore Features
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
Small Object Detection by Generative and Discriminative Learning
Yi Gu, Jie Li, Chentao Wu, Weijia Jia, Jianping Chen

Auto-TLDR; Generative and Discriminative Learning for Small Object Detection
Abstract Slides Poster Similar
Small Object Detection Leveraging on Simultaneous Super-Resolution
Hong Ji, Zhi Gao, Xiaodong Liu, Tiancan Mei

Auto-TLDR; Super-Resolution via Generative Adversarial Network for Small Object Detection
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
Multi-Laplacian GAN with Edge Enhancement for Face Super Resolution

Auto-TLDR; Face Image Super-Resolution with Enhanced Edge Information
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Tarsier: Evolving Noise Injection inSuper-Resolution GANs
Baptiste Roziere, Nathanaël Carraz Rakotonirina, Vlad Hosu, Rasoanaivo Andry, Hanhe Lin, Camille Couprie, Olivier Teytaud

Auto-TLDR; Evolutionary Super-Resolution using Diagonal CMA
Abstract Slides Poster Similar
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Detail Fusion GAN: High-Quality Translation for Unpaired Images with GAN-Based Data Augmentation
Ling Li, Yaochen Li, Chuan Wu, Hang Dong, Peilin Jiang, Fei Wang

Auto-TLDR; Data Augmentation with GAN-based Generative Adversarial Network
Abstract Slides Poster Similar
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Galaxy Image Translation with Semi-Supervised Noise-Reconstructed Generative Adversarial Networks
Qiufan Lin, Dominique Fouchez, Jérôme Pasquet

Auto-TLDR; Semi-supervised Image Translation with Generative Adversarial Networks Using Paired and Unpaired Images
Abstract Slides Poster Similar
OCT Image Segmentation Using NeuralArchitecture Search and SRGAN
Saba Heidari, Omid Dehzangi, Nasser M. Nasarabadi, Ali Rezai

Auto-TLDR; Automatic Segmentation of Retinal Layers in Optical Coherence Tomography using Neural Architecture Search
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
MagnifierNet: Learning Efficient Small-Scale Pedestrian Detector towards Multiple Dense Regions
Qi Cheng, Mingqin Chen, Yingjie Wu, Fei Chen, Shiping Lin

Auto-TLDR; MagnifierNet: A Simple but Effective Small-Scale Pedestrian Detection Towards Multiple Dense Regions
Abstract Slides Poster Similar
Cycle-Consistent Adversarial Networks and Fast Adaptive Bi-Dimensional Empirical Mode Decomposition for Style Transfer
Elissavet Batziou, Petros Alvanitopoulos, Konstantinos Ioannidis, Ioannis Patras, Stefanos Vrochidis, Ioannis Kompatsiaris

Auto-TLDR; FABEMD: Fast and Adaptive Bidimensional Empirical Mode Decomposition for Style Transfer on Images
Abstract Slides Poster Similar
Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection
Mengyuan Ding, Shanshan Zhang, Jian Yang

Auto-TLDR; Learningable Dynamic HRNet for Pedestrian Detection
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
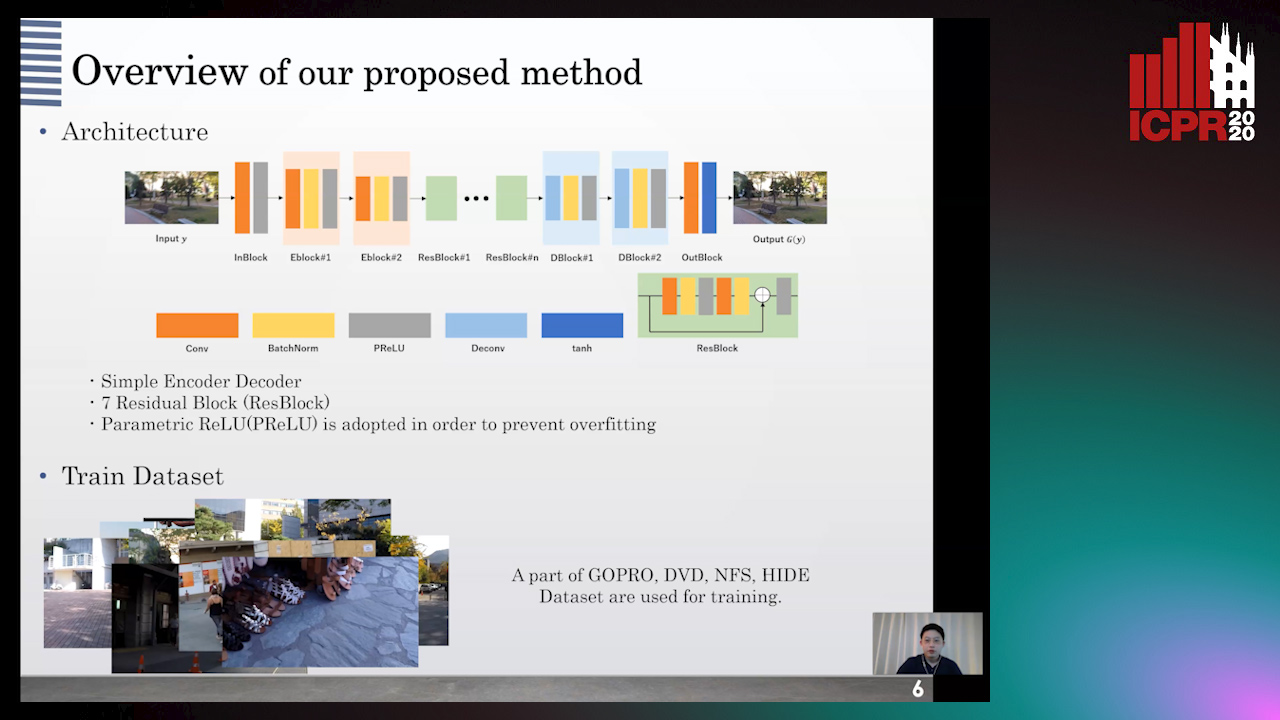
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Pierfrancesco Ardino, Yahui Liu, Elisa Ricci, Bruno Lepri, Marco De Nadai

Auto-TLDR; Semantic-Guided Inpainting of Complex Urban Scene Using Semantic Segmentation and Generation
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Debapriya Roy, Diganta Mukherjee, Bhabatosh Chanda

Auto-TLDR; Unsupervised Skin Tone Change Using Augmented Reality Based Models
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Multi-scale Processing of Noisy Images using Edge Preservation Losses

Auto-TLDR; Multi-scale U-net for Noisy Image Detection and Denoising
Abstract Slides Poster Similar
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
Stylized-Colorization for Line Arts
Tzu-Ting Fang, Minh Duc Vo, Akihiro Sugimoto, Shang-Hong Lai

Auto-TLDR; Stylized-colorization using GAN-based End-to-End Model for Anime
Abstract Slides Poster Similar
UCCTGAN: Unsupervised Clothing Color Transformation Generative Adversarial Network
Shuming Sun, Xiaoqiang Li, Jide Li

Auto-TLDR; An Unsupervised Clothing Color Transformation Generative Adversarial Network
Abstract Slides Poster Similar
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
Improving Low-Resolution Image Classification by Super-Resolution with Enhancing High-Frequency Content
Liguo Zhou, Guang Chen, Mingyue Feng, Alois Knoll

Auto-TLDR; Super-resolution for Low-Resolution Image Classification
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar