Masaaki Ikehara
Papers from this author
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
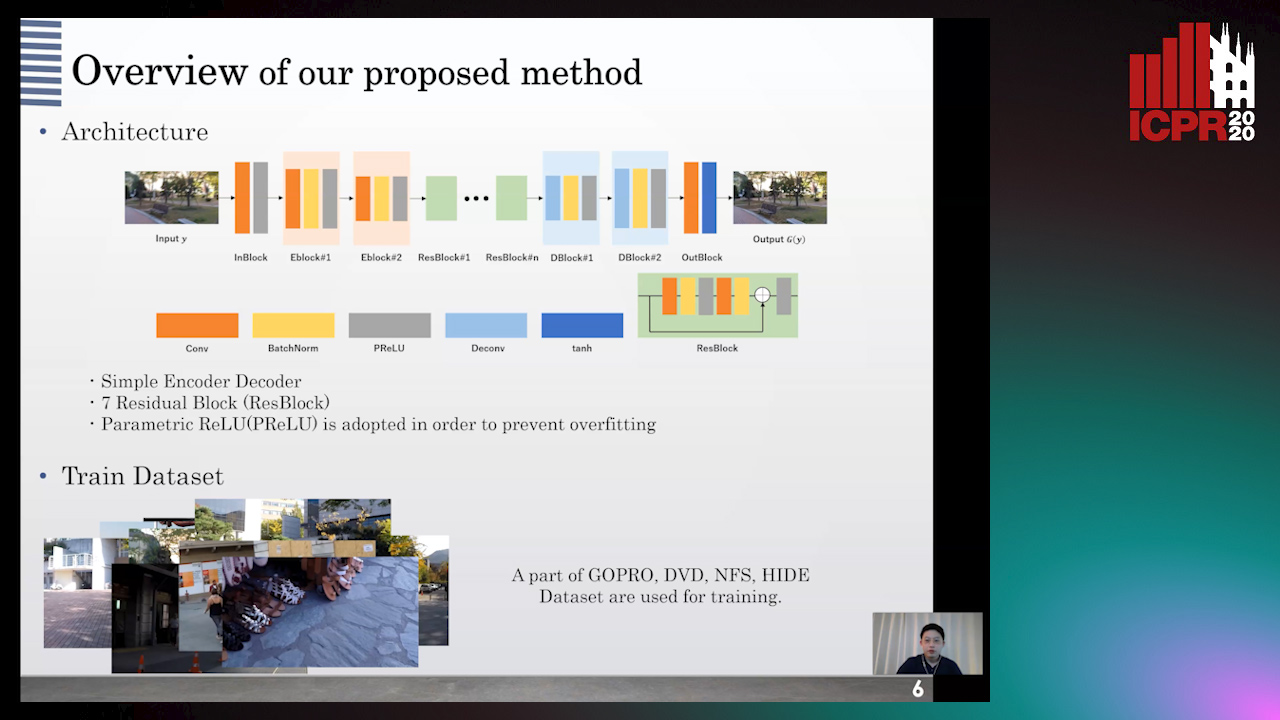
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar