Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Similar papers
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
ACCLVOS: Atrous Convolution with Spatial-Temporal ConvLSTM for Video Object Segmentation
Muzhou Xu, Shan Zong, Chunping Liu, Shengrong Gong, Zhaohui Wang, Yu Xia

Auto-TLDR; Semi-supervised Video Object Segmentation using U-shape Convolution and ConvLSTM
Abstract Slides Poster Similar
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
Human Segmentation with Dynamic LiDAR Data
Tao Zhong, Wonjik Kim, Masayuki Tanaka, Masatoshi Okutomi

Auto-TLDR; Spatiotemporal Neural Network for Human Segmentation with Dynamic Point Clouds
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
Learning Object Deformation and Motion Adaption for Semi-Supervised Video Object Segmentation
Xiaoyang Zheng, Xin Tan, Jianming Guo, Lizhuang Ma

Auto-TLDR; Semi-supervised Video Object Segmentation with Mask-propagation-based Model
Abstract Slides Poster Similar
Let's Play Music: Audio-Driven Performance Video Generation
Hao Zhu, Yi Li, Feixia Zhu, Aihua Zheng, Ran He

Auto-TLDR; APVG: Audio-driven Performance Video Generation Using Structured Temporal UNet
Abstract Slides Poster Similar
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
The Role of Cycle Consistency for Generating Better Human Action Videos from a Single Frame

Auto-TLDR; Generating Videos with Human Action Semantics using Cycle Constraints
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
Learning to Take Directions One Step at a Time
Qiyang Hu, Adrian Wälchli, Tiziano Portenier, Matthias Zwicker, Paolo Favaro

Auto-TLDR; Generating a Sequence of Motion Strokes from a Single Image
Abstract Slides Poster Similar
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
PHNet: Parasite-Host Network for Video Crowd Counting
Shiqiao Meng, Jiajie Li, Weiwei Guo, Jinfeng Jiang, Lai Ye

Auto-TLDR; PHNet: A Parasite-Host Network for Video Crowd Counting
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
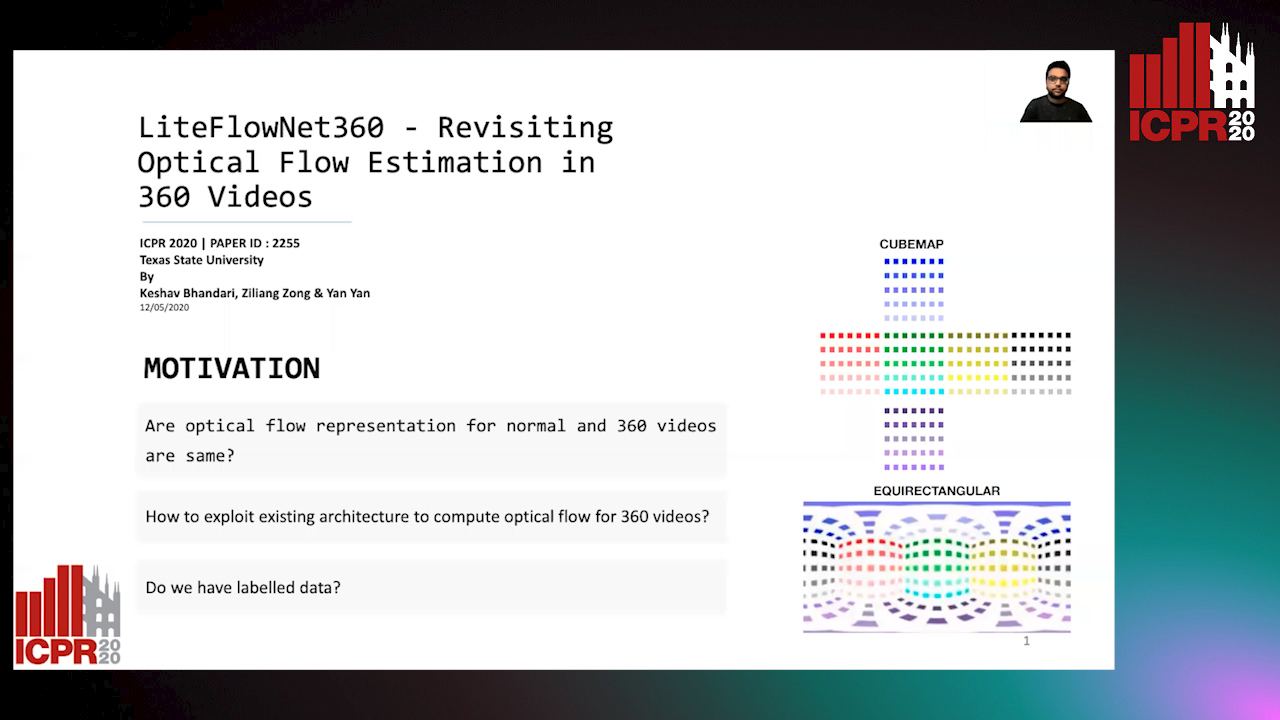
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
HMFlow: Hybrid Matching Optical Flow Network for Small and Fast-Moving Objects
Suihanjin Yu, Youmin Zhang, Chen Wang, Xiao Bai, Liang Zhang, Edwin Hancock

Auto-TLDR; Hybrid Matching Optical Flow Network with Global Matching Component
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-To-Video Synthesis
Fu-En Yang, Jing-Cheng Chang, Yuan-Hao Lee, Yu-Chiang Frank Wang

Auto-TLDR; Dual Motion Transfer GAN for Convolutional Neural Networks
Abstract Slides Poster Similar
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; Mutual Information Estimation from Variational Lower Bounds Using a Critic's Hypothesis Space
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; MIPAE: Mutual Information Predictive Auto-Encoder for Video Prediction
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Activity Recognition Using First-Person-View Cameras Based on Sparse Optical Flows
Peng-Yuan Kao, Yan-Jing Lei, Chia-Hao Chang, Chu-Song Chen, Ming-Sui Lee, Yi-Ping Hung

Auto-TLDR; 3D Convolutional Neural Network for Activity Recognition with FPV Videos
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
TSMSAN: A Three-Stream Multi-Scale Attentive Network for Video Saliency Detection
Jingwen Yang, Guanwen Zhang, Wei Zhou

Auto-TLDR; Three-stream Multi-scale attentive network for video saliency detection in dynamic scenes
Abstract Slides Poster Similar
Siamese Fully Convolutional Tracker with Motion Correction
Mathew Francis, Prithwijit Guha

Auto-TLDR; A Siamese Ensemble for Visual Tracking with Appearance and Motion Components
Abstract Slides Poster Similar
Detail Fusion GAN: High-Quality Translation for Unpaired Images with GAN-Based Data Augmentation
Ling Li, Yaochen Li, Chuan Wu, Hang Dong, Peilin Jiang, Fei Wang

Auto-TLDR; Data Augmentation with GAN-based Generative Adversarial Network
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
Talking Face Generation Via Learning Semantic and Temporal Synchronous Landmarks
Aihua Zheng, Feixia Zhu, Hao Zhu, Mandi Luo, Ran He

Auto-TLDR; A semantic and temporal synchronous landmark learning method for talking face generation
Abstract Slides Poster Similar
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
Video Object Detection Using Object's Motion Context and Spatio-Temporal Feature Aggregation
Jaekyum Kim, Junho Koh, Byeongwon Lee, Seungji Yang, Jun Won Choi

Auto-TLDR; Video Object Detection Using Spatio-Temporal Aggregated Features and Gated Attention Network
Abstract Slides Poster Similar
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar