Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari,
Ziliang Zong,
Yan Yan
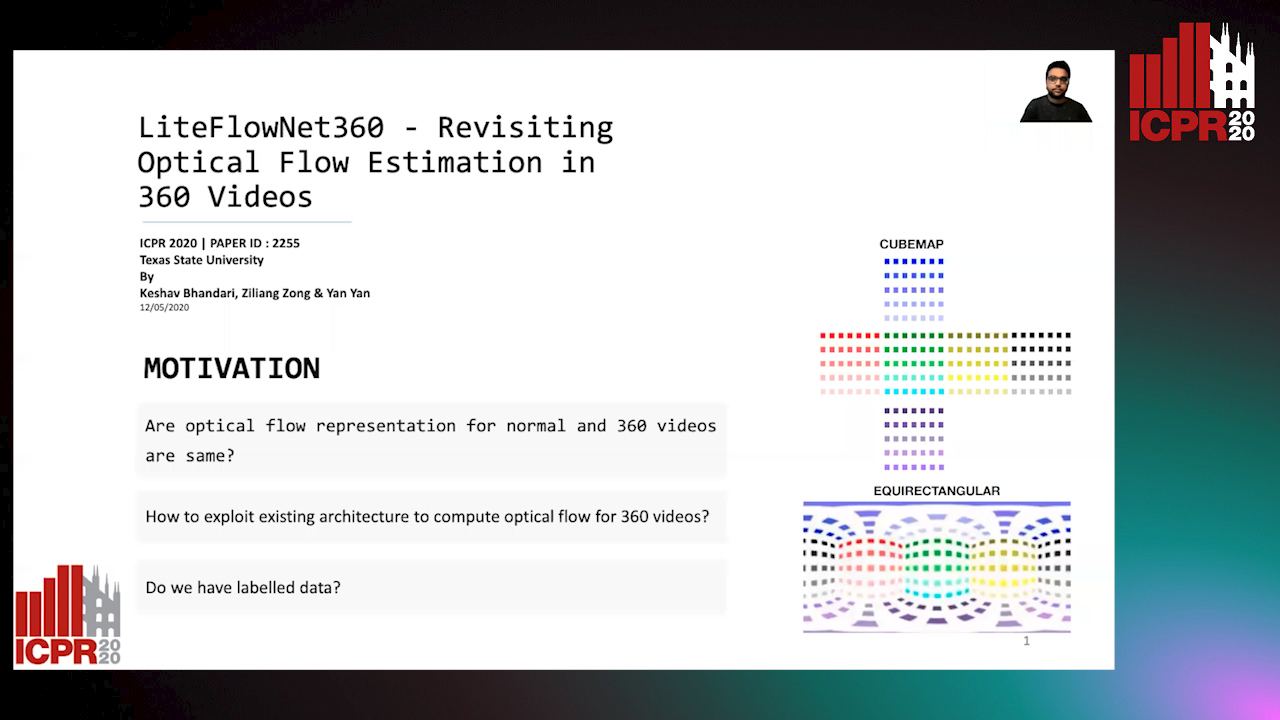
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Similar papers
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
PA-FlowNet: Pose-Auxiliary Optical Flow Network for Spacecraft Relative Pose Estimation
Zhi Yu Chen, Po-Heng Chen, Kuan-Wen Chen, Chen-Yu Chan

Auto-TLDR; PA-FlowNet: An End-to-End Pose-auxiliary Optical Flow Network for Space Travel and Landing
Abstract Slides Poster Similar
HMFlow: Hybrid Matching Optical Flow Network for Small and Fast-Moving Objects
Suihanjin Yu, Youmin Zhang, Chen Wang, Xiao Bai, Liang Zhang, Edwin Hancock

Auto-TLDR; Hybrid Matching Optical Flow Network with Global Matching Component
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
ResFPN: Residual Skip Connections in Multi-Resolution Feature Pyramid Networks for Accurate Dense Pixel Matching
Rishav ., René Schuster, Ramy Battrawy, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; Resolution Feature Pyramid Networks for Dense Pixel Matching
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Siamese Fully Convolutional Tracker with Motion Correction
Mathew Francis, Prithwijit Guha

Auto-TLDR; A Siamese Ensemble for Visual Tracking with Appearance and Motion Components
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Motion-Supervised Co-Part Segmentation
Aliaksandr Siarohin, Subhankar Roy, Stéphane Lathuiliere, Sergey Tulyakov, Elisa Ricci, Nicu Sebe

Auto-TLDR; Self-supervised Co-Part Segmentation Using Motion Information from Videos
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
FC-DCNN: A Densely Connected Neural Network for Stereo Estimation
Dominik Hirner, Friedrich Fraundorfer

Auto-TLDR; FC-DCNN: A Lightweight Network for Stereo Estimation
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Deep Homography-Based Video Stabilization
Maria Silvia Ito, Ebroul Izquierdo

Auto-TLDR; Video Stabilization using Deep Learning and Spatial Transformer Networks
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Siamese Dynamic Mask Estimation Network for Fast Video Object Segmentation
Dexiang Hong, Guorong Li, Kai Xu, Li Su, Qingming Huang

Auto-TLDR; Siamese Dynamic Mask Estimation for Video Object Segmentation
Abstract Slides Poster Similar
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
Suppressing Features That Contain Disparity Edge for Stereo Matching
Xindong Ai, Zuliu Yang, Weida Yang, Yong Zhao, Zhengzhong Yu, Fuchi Li

Auto-TLDR; SDE-Attention: A Novel Attention Mechanism for Stereo Matching
Abstract Slides Poster Similar
Estimating Gaze Points from Facial Landmarks by a Remote Spherical Camera

Auto-TLDR; Gaze Point Estimation from a Spherical Image from Facial Landmarks
Abstract Slides Poster Similar
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
ACCLVOS: Atrous Convolution with Spatial-Temporal ConvLSTM for Video Object Segmentation
Muzhou Xu, Shan Zong, Chunping Liu, Shengrong Gong, Zhaohui Wang, Yu Xia

Auto-TLDR; Semi-supervised Video Object Segmentation using U-shape Convolution and ConvLSTM
Abstract Slides Poster Similar
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
Learning Stereo Matchability in Disparity Regression Networks
Jingyang Zhang, Yao Yao, Zixin Luo, Shiwei Li, Tianwei Shen, Tian Fang, Long Quan

Auto-TLDR; Deep Stereo Matchability for Weakly Matchable Regions
Motion Complementary Network for Efficient Action Recognition
Ke Cheng, Yifan Zhang, Chenghua Li, Jian Cheng, Hanqing Lu

Auto-TLDR; Efficient Motion Complementary Network for Action Recognition
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
Learning Knowledge-Rich Sequential Model for Planar Homography Estimation in Aerial Video

Auto-TLDR; Sequential Estimation of Planar Homographic Transformations over Aerial Videos
Abstract Slides Poster Similar
Light3DPose: Real-Time Multi-Person 3D Pose Estimation from Multiple Views
Alessio Elmi, Davide Mazzini, Pietro Tortella

Auto-TLDR; 3D Pose Estimation of Multiple People from a Few calibrated Camera Views using Deep Learning
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Learning Object Deformation and Motion Adaption for Semi-Supervised Video Object Segmentation
Xiaoyang Zheng, Xin Tan, Jianming Guo, Lizhuang Ma

Auto-TLDR; Semi-supervised Video Object Segmentation with Mask-propagation-based Model
Abstract Slides Poster Similar
AttendAffectNet: Self-Attention Based Networks for Predicting Affective Responses from Movies
Thi Phuong Thao Ha, Bt Balamurali, Herremans Dorien, Roig Gemma

Auto-TLDR; AttendAffectNet: A Self-Attention Based Network for Emotion Prediction from Movies
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Semi-Supervised Deep Learning Techniques for Spectrum Reconstruction
Adriano Simonetto, Vincent Parret, Alexander Gatto, Piergiorgio Sartor, Pietro Zanuttigh

Auto-TLDR; hyperspectral data estimation from RGB data using semi-supervised learning
Abstract Slides Poster Similar
Joint Face Alignment and 3D Face Reconstruction with Efficient Convolution Neural Networks
Keqiang Li, Huaiyu Wu, Xiuqin Shang, Zhen Shen, Gang Xiong, Xisong Dong, Bin Hu, Fei-Yue Wang

Auto-TLDR; Mobile-FRNet: Efficient 3D Morphable Model Alignment and 3D Face Reconstruction from a Single 2D Facial Image
Abstract Slides Poster Similar
Human Segmentation with Dynamic LiDAR Data
Tao Zhong, Wonjik Kim, Masayuki Tanaka, Masatoshi Okutomi

Auto-TLDR; Spatiotemporal Neural Network for Human Segmentation with Dynamic Point Clouds
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
PointSpherical: Deep Shape Context for Point Cloud Learning in Spherical Coordinates
Hua Lin, Bin Fan, Yongcheng Liu, Yirong Yang, Zheng Pan, Jianbo Shi, Chunhong Pan, Huiwen Xie

Auto-TLDR; Spherical Hierarchical Modeling of 3D Point Cloud
Abstract Slides Poster Similar
Not All Domains Are Equally Complex: Adaptive Multi-Domain Learning
Ali Senhaji, Jenni Karoliina Raitoharju, Moncef Gabbouj, Alexandros Iosifidis

Auto-TLDR; Adaptive Parameterization for Multi-Domain Learning
Abstract Slides Poster Similar
Leveraging a Weakly Adversarial Paradigm for Joint Learning of Disparity and Confidence Estimation
Matteo Poggi, Fabio Tosi, Filippo Aleotti, Stefano Mattoccia

Auto-TLDR; Joint Training of Deep-Networks for Outlier Detection from Stereo Images
Abstract Slides Poster Similar
Visual Saliency Oriented Vehicle Scale Estimation
Qixin Chen, Tie Liu, Jiali Ding, Zejian Yuan, Yuanyuan Shang

Auto-TLDR; Regularized Intensity Matching for Vehicle Scale Estimation with salient object detection
Abstract Slides Poster Similar
Generalized Shortest Path-Based Superpixels for Accurate Segmentation of Spherical Images
Rémi Giraud, Rodrigo Borba Pinheiro, Yannick Berthoumieu

Auto-TLDR; SPS: Spherical Shortest Path-based Superpixels
Abstract Slides Poster Similar