Yan Yan
Papers from this author
Cascade Attention Guided Residue Learning GAN for Cross-Modal Translation
Bin Duan, Wei Wang, Hao Tang, Hugo Latapie, Yan Yan

Auto-TLDR; Cascade Attention-Guided Residue GAN for Cross-modal Audio-Visual Learning
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
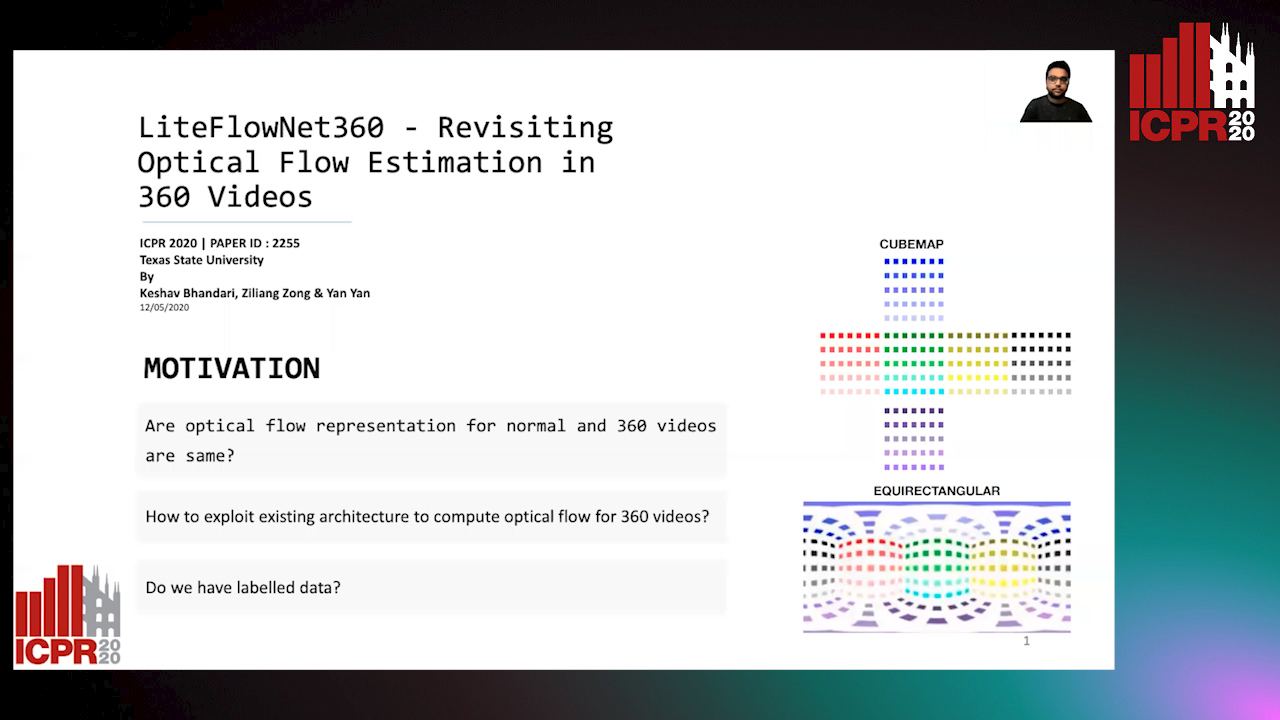
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation