Generalized Shortest Path-Based Superpixels for Accurate Segmentation of Spherical Images
Rémi Giraud,
Rodrigo Borba Pinheiro,
Yannick Berthoumieu

Auto-TLDR; SPS: Spherical Shortest Path-based Superpixels
Similar papers
Content-Sensitive Superpixels Based on Adaptive Regrowth

Auto-TLDR; Adaptive Regrowth for Content-Sensitive Superpixels
Abstract Slides Poster Similar
BP-Net: Deep Learning-Based Superpixel Segmentation for RGB-D Image
Bin Zhang, Xuejing Kang, Anlong Ming

Auto-TLDR; A Deep Learning-based Superpixel Segmentation Algorithm for RGB-D Image
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
PointSpherical: Deep Shape Context for Point Cloud Learning in Spherical Coordinates
Hua Lin, Bin Fan, Yongcheng Liu, Yirong Yang, Zheng Pan, Jianbo Shi, Chunhong Pan, Huiwen Xie

Auto-TLDR; Spherical Hierarchical Modeling of 3D Point Cloud
Abstract Slides Poster Similar
Deep Superpixel Cut for Unsupervised Image Segmentation

Auto-TLDR; Deep Superpixel Cut for Deep Unsupervised Image Segmentation
Abstract Slides Poster Similar
A Plane-Based Approach for Indoor Point Clouds Registration
Ketty Favre, Muriel Pressigout, Luce Morin, Eric Marchand

Auto-TLDR; A plane-based registration approach for indoor environments based on LiDAR data
Abstract Slides Poster Similar
Superpixel-Based Refinement for Object Proposal Generation
Christian Wilms, Simone Frintrop

Auto-TLDR; Superpixel-based Refinement of AttentionMask for Object Segmentation
Abstract Slides Poster Similar
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
3D Semantic Labeling of Photogrammetry Meshes Based on Active Learning
Mengqi Rong, Shuhan Shen, Zhanyi Hu

Auto-TLDR; 3D Semantic Expression of Urban Scenes Based on Active Learning
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Coarse to Fine: Progressive and Multi-Task Learning for Salient Object Detection
Dong-Goo Kang, Sangwoo Park, Joonki Paik

Auto-TLDR; Progressive and mutl-task learning scheme for salient object detection
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Graph Signal Active Contours

Auto-TLDR; Adaptation of Active Contour Without Edges for Graph Signal Processing
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
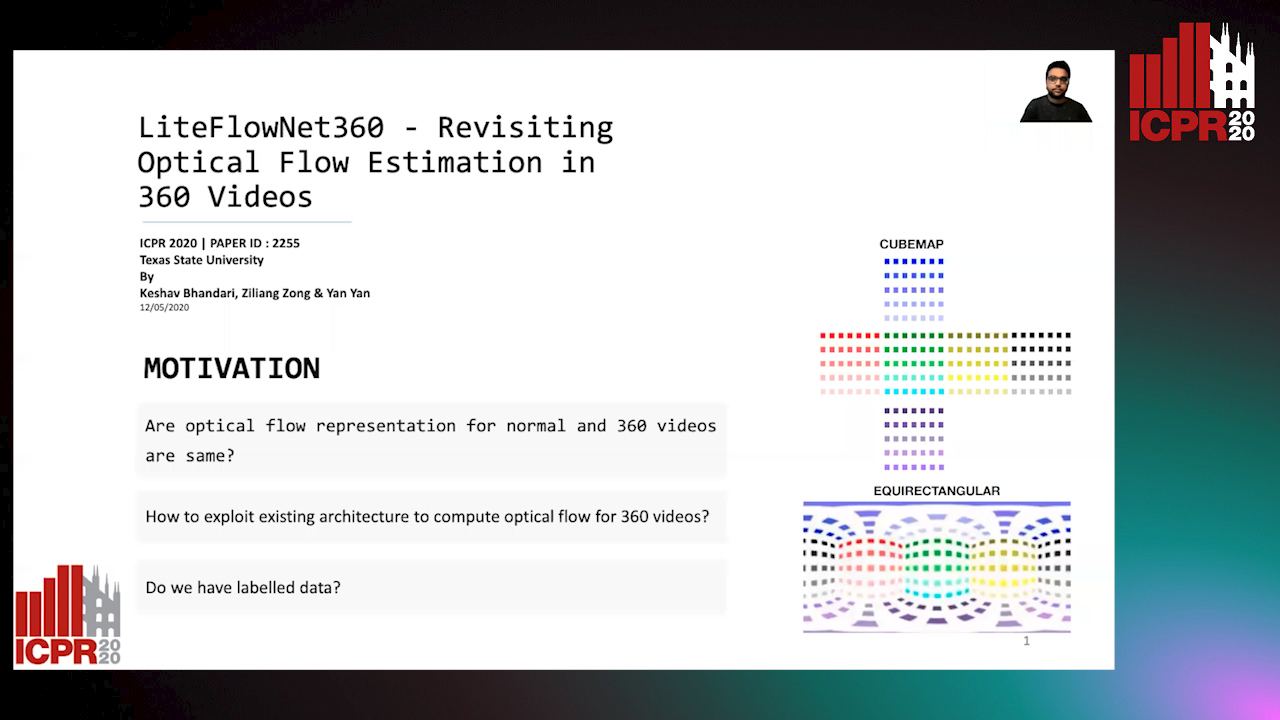
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Fused 3-Stage Image Segmentation for Pleural Effusion Cell Clusters
Sike Ma, Meng Zhao, Hao Wang, Fan Shi, Xuguo Sun, Shengyong Chen, Hong-Ning Dai

Auto-TLDR; Coarse Segmentation of Stained and Stained Unstained Cell Clusters in pleural effusion using 3-stage segmentation method
Abstract Slides Poster Similar
Walk the Lines: Object Contour Tracing CNN for Contour Completion of Ships

Auto-TLDR; Walk the Lines: A Convolutional Neural Network trained to follow object contours
Abstract Slides Poster Similar
3D Point Cloud Registration Based on Cascaded Mutual Information Attention Network

Auto-TLDR; Cascaded Mutual Information Attention Network for 3D Point Cloud Registration
Abstract Slides Poster Similar
Self-Supervised Detection and Pose Estimation of Logistical Objects in 3D Sensor Data
Nikolas Müller, Jonas Stenzel, Jian-Jia Chen

Auto-TLDR; A self-supervised and fully automated deep learning approach for object pose estimation using simulated 3D data
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Camera Calibration Using Parallel Line Segments

Auto-TLDR; Closed-Form Calibration of Surveillance Cameras using Parallel 3D Line Segment Projections
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
Force Banner for the Recognition of Spatial Relations
Robin Deléarde, Camille Kurtz, Laurent Wendling, Philippe Dejean

Auto-TLDR; Spatial Relation Recognition using Force Banners
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
An Adaptive Model for Face Distortion Correction

Auto-TLDR; Adaptive Polynomial Model for Face Distortion Correction in Selfie Photos
Weakly Supervised Geodesic Segmentation of Egyptian Mummy CT Scans
Avik Hati, Matteo Bustreo, Diego Sona, Vittorio Murino, Alessio Del Bue

Auto-TLDR; A Weakly Supervised and Efficient Interactive Segmentation of Ancient Egyptian Mummies CT Scans Using Geodesic Distance Measure and GrabCut
Abstract Slides Poster Similar
Enhancing Deep Semantic Segmentation of RGB-D Data with Entangled Forests
Matteo Terreran, Elia Bonetto, Stefano Ghidoni

Auto-TLDR; FuseNet: A Lighter Deep Learning Model for Semantic Segmentation
Abstract Slides Poster Similar
Generic Document Image Dewarping by Probabilistic Discretization of Vanishing Points
Gilles Simon, Salvatore Tabbone

Auto-TLDR; Robust Document Dewarping using vanishing points
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
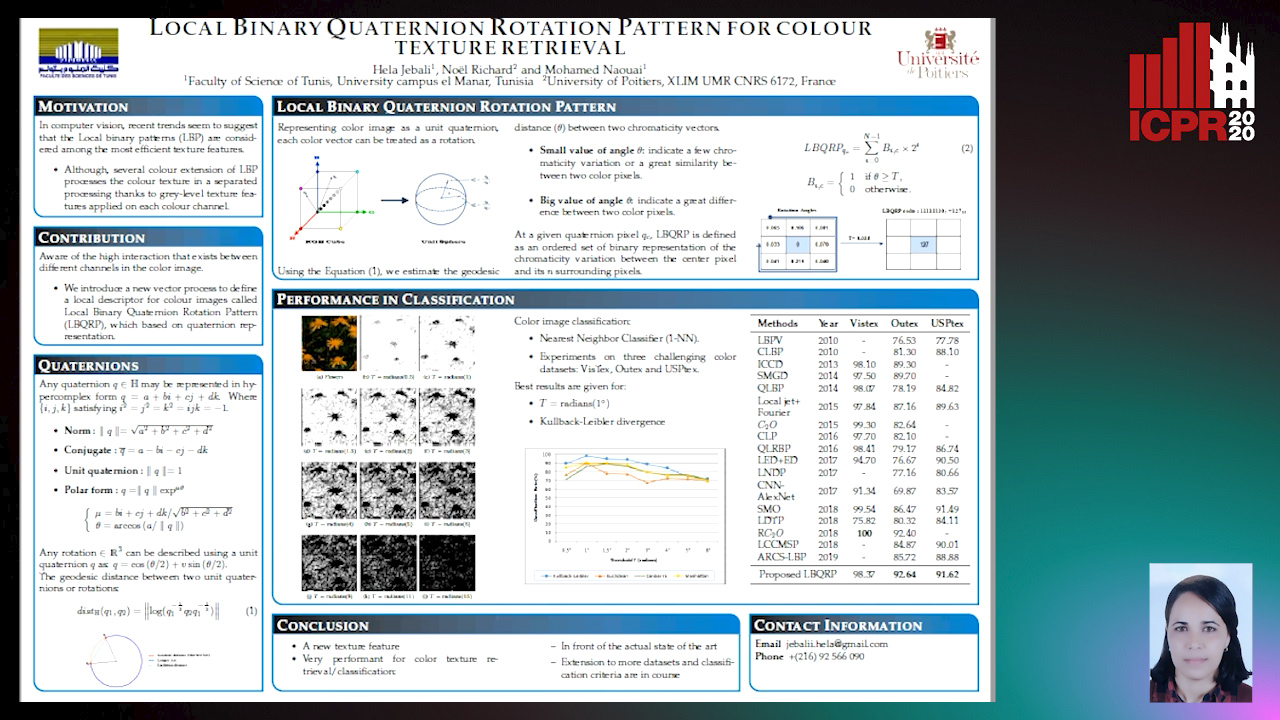
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
Machine-Learned Regularization and Polygonization of Building Segmentation Masks
Stefano Zorzi, Ksenia Bittner, Friedrich Fraundorfer

Auto-TLDR; Automatic Regularization and Polygonization of Building Segmentation masks using Generative Adversarial Network
Abstract Slides Poster Similar
Multi-Camera Sports Players 3D Localization with Identification Reasoning
Yukun Yang, Ruiheng Zhang, Wanneng Wu, Yu Peng, Xu Min

Auto-TLDR; Probabilistic and Identified Occupancy Map for Sports Players 3D Localization
Abstract Slides Poster Similar
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
Vesselness Filters: A Survey with Benchmarks Applied to Liver Imaging
Jonas Lamy, Odyssée Merveille, Bertrand Kerautret, Nicolas Passat, Antoine Vacavant

Auto-TLDR; Comparison of Vessel Enhancement Filters for Liver Vascular Network Segmentation
Abstract Slides Poster Similar
Siamese Graph Convolution Network for Face Sketch Recognition
Liang Fan, Xianfang Sun, Paul Rosin

Auto-TLDR; A novel Siamese graph convolution network for face sketch recognition
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
Fast Blending of Planar Shapes Based on Invariant Invertible and Stable Descriptors
Emna Ghorbel, Faouzi Ghorbel, Ines Sakly, Slim Mhiri

Auto-TLDR; Fined-Fourier-based Invariant Descriptor for Planar Shape Blending
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
A Hierarchical Framework for Leaf Instance Segmentation: Application to Plant Phenotyping
Swati Bhugra, Kanish Garg, Santanu Chaudhury, Brejesh Lall

Auto-TLDR; Under-segmentation of plant image using a graph based formulation to extract leaf shape knowledge for the task of leaf instance segmentation
Abstract Slides Poster Similar
Generalized Conics: Properties and Applications
Aysylu Gabdulkhakova, Walter Kropatsch

Auto-TLDR; A Generalized Conic Representation for Distance Fields
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
Multi-Attribute Regression Network for Face Reconstruction

Auto-TLDR; A Multi-Attribute Regression Network for Face Reconstruction
Abstract Slides Poster Similar