An Adaptive Model for Face Distortion Correction

Auto-TLDR; Adaptive Polynomial Model for Face Distortion Correction in Selfie Photos
Similar papers
Position-Aware and Symmetry Enhanced GAN for Radial Distortion Correction
Yongjie Shi, Xin Tong, Jingsi Wen, He Zhao, Xianghua Ying, Jinshi Hongbin Zha

Auto-TLDR; Generative Adversarial Network for Radial Distorted Image Correction
Abstract Slides Poster Similar
Camera Calibration Using Parallel Line Segments

Auto-TLDR; Closed-Form Calibration of Surveillance Cameras using Parallel 3D Line Segment Projections
Abstract Slides Poster Similar
Calibration and Absolute Pose Estimation of Trinocular Linear Camera Array for Smart City Applications
Martin Ahrnbom, Mikael Nilsson, Håkan Ardö, Kalle Åström, Oksana Yastremska-Kravchenko, Aliaksei Laureshyn

Auto-TLDR; Trinocular Linear Camera Array Calibration for Traffic Surveillance Applications
Abstract Slides Poster Similar
ID Documents Matching and Localization with Multi-Hypothesis Constraints
Guillaume Chiron, Nabil Ghanmi, Ahmad Montaser Awal

Auto-TLDR; Identity Document Localization in the Wild Using Multi-hypothesis Exploration
Abstract Slides Poster Similar
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Ryota Akai, Yuzuko Utsumi, Yuka Miwa, Masakazu Iwamura, Koichi Kise

Auto-TLDR; Object Counting for Omnidirectional Images Using Stereographic Projection
Generic Document Image Dewarping by Probabilistic Discretization of Vanishing Points
Gilles Simon, Salvatore Tabbone

Auto-TLDR; Robust Document Dewarping using vanishing points
Abstract Slides Poster Similar
Generalized Shortest Path-Based Superpixels for Accurate Segmentation of Spherical Images
Rémi Giraud, Rodrigo Borba Pinheiro, Yannick Berthoumieu

Auto-TLDR; SPS: Spherical Shortest Path-based Superpixels
Abstract Slides Poster Similar
Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li, Xiaopeng Zheng, Bir Bhanu, Shun Long, Qingfeng Zhang, Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Abstract Slides Poster Similar
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
A Gated and Bifurcated Stacked U-Net Module for Document Image Dewarping
Hmrishav Bandyopadhyay, Tanmoy Dasgupta, Nibaran Das, Mita Nasipuri

Auto-TLDR; Gated and Bifurcated Stacked U-Net for Dewarping Document Images
Abstract Slides Poster Similar
Inner Eye Canthus Localization for Human Body Temperature Screening
Claudio Ferrari, Lorenzo Berlincioni, Marco Bertini, Alberto Del Bimbo

Auto-TLDR; Automatic Localization of the Inner Eye Canthus in Thermal Face Images using 3D Morphable Face Model
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
3D Semantic Labeling of Photogrammetry Meshes Based on Active Learning
Mengqi Rong, Shuhan Shen, Zhanyi Hu

Auto-TLDR; 3D Semantic Expression of Urban Scenes Based on Active Learning
Abstract Slides Poster Similar
Unsupervised Contrastive Photo-To-Caricature Translation Based on Auto-Distortion
Yuhe Ding, Xin Ma, Mandi Luo, Aihua Zheng, Ran He

Auto-TLDR; Unsupervised contrastive photo-to-caricature translation with style loss
Abstract Slides Poster Similar
Deep Homography-Based Video Stabilization
Maria Silvia Ito, Ebroul Izquierdo

Auto-TLDR; Video Stabilization using Deep Learning and Spatial Transformer Networks
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Total Estimation from RGB Video: On-Line Camera Self-Calibration, Non-Rigid Shape and Motion

Auto-TLDR; Joint Auto-Calibration, Pose and 3D Reconstruction of a Non-rigid Object from an uncalibrated RGB Image Sequence
Abstract Slides Poster Similar
Estimating Gaze Points from Facial Landmarks by a Remote Spherical Camera

Auto-TLDR; Gaze Point Estimation from a Spherical Image from Facial Landmarks
Abstract Slides Poster Similar
Adaptive Feature Fusion Network for Gaze Tracking in Mobile Tablets
Yiwei Bao, Yihua Cheng, Yunfei Liu, Feng Lu

Auto-TLDR; Adaptive Feature Fusion Network for Multi-stream Gaze Estimation in Mobile Tablets
Abstract Slides Poster Similar
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
AdvHat: Real-World Adversarial Attack on ArcFace Face ID System
Stepan Komkov, Aleksandr Petiushko

Auto-TLDR; Adversarial Sticker Attack on ArcFace in Shooting Conditions
Abstract Slides Poster Similar
Object Features and Face Detection Performance: Analyses with 3D-Rendered Synthetic Data
Jian Han, Sezer Karaoglu, Hoang-An Le, Theo Gevers

Auto-TLDR; Synthetic Data for Face Detection Using 3DU Face Dataset
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
Minimal Solvers for Indoor UAV Positioning
Marcus Valtonen Örnhag, Patrik Persson, Mårten Wadenbäck, Kalle Åström, Anders Heyden

Auto-TLDR; Relative Pose Solvers for Visual Indoor UAV Navigation
Abstract Slides Poster Similar
2D License Plate Recognition based on Automatic Perspective Rectification
Hui Xu, Zhao-Hong Guo, Da-Han Wang, Xiang-Dong Zhou, Yu Shi

Auto-TLDR; Perspective Rectification Network for License Plate Recognition
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
How Important Are Faces for Person Re-Identification?
Julia Dietlmeier, Joseph Antony, Kevin Mcguinness, Noel E O'Connor

Auto-TLDR; Anonymization of Person Re-identification Datasets with Face Detection and Blurring
Abstract Slides Poster Similar
Pixel-based Facial Expression Synthesis

Auto-TLDR; pixel-based facial expression synthesis using GANs
Abstract Slides Poster Similar
Multi-Camera Sports Players 3D Localization with Identification Reasoning
Yukun Yang, Ruiheng Zhang, Wanneng Wu, Yu Peng, Xu Min

Auto-TLDR; Probabilistic and Identified Occupancy Map for Sports Players 3D Localization
Abstract Slides Poster Similar
SAILenv: Learning in Virtual Visual Environments Made Simple
Enrico Meloni, Luca Pasqualini, Matteo Tiezzi, Marco Gori, Stefano Melacci

Auto-TLDR; SAILenv: A Simple and Customized Platform for Visual Recognition in Virtual 3D Environment
Abstract Slides Poster Similar
An Intelligent Photographing Guidance System Based on Compositional Deep Features and Intepretable Machine Learning Model
Chin-Shyurng Fahn, Meng-Luen Wu, Sheng-Kuei Tsau

Auto-TLDR; Photography Guidance Using Interpretable Machine Learning
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
CARRADA Dataset: Camera and Automotive Radar with Range-Angle-Doppler Annotations
Arthur Ouaknine, Alasdair Newson, Julien Rebut, Florence Tupin, Patrick Pérez

Auto-TLDR; CARRADA: A dataset of synchronized camera and radar recordings with range-angle-Doppler annotations for autonomous driving
Abstract Slides Poster Similar
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
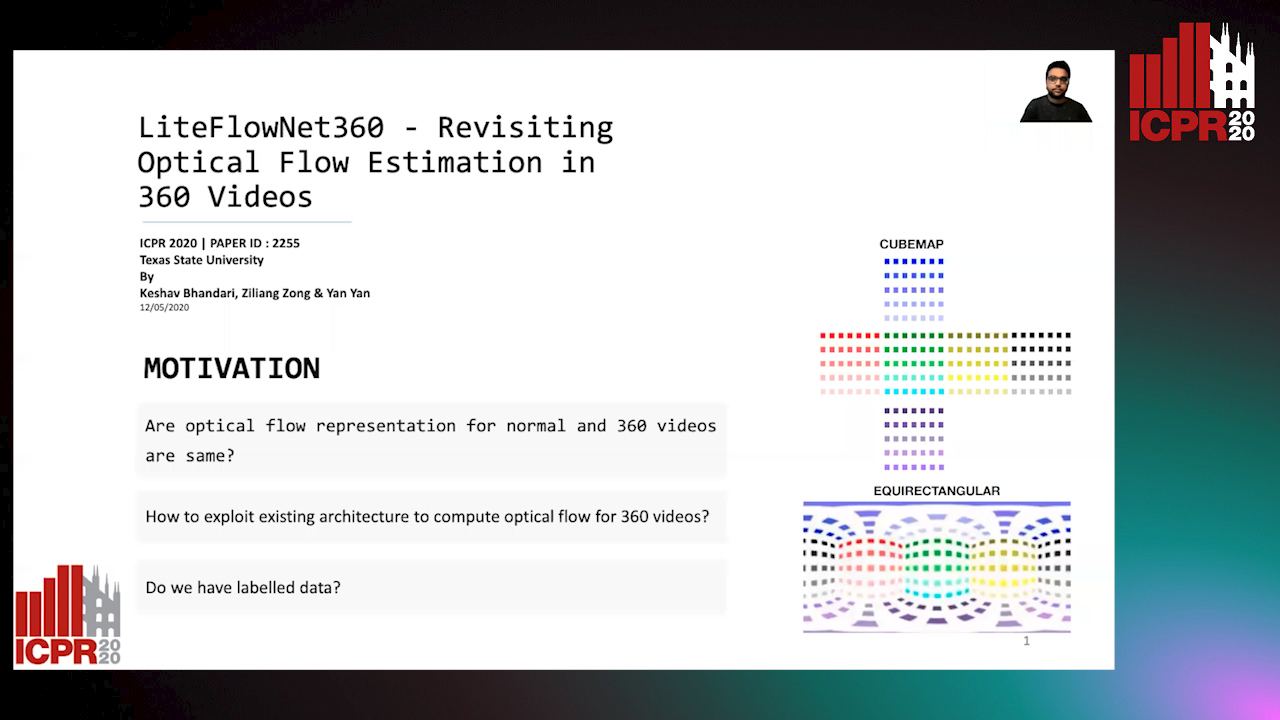
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar