Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo,
Shusaku Asada,
Hirotaka Maruyama,
Masaru Koide,
Kohei Yamamoto,
Yoshihisa Suetsugu

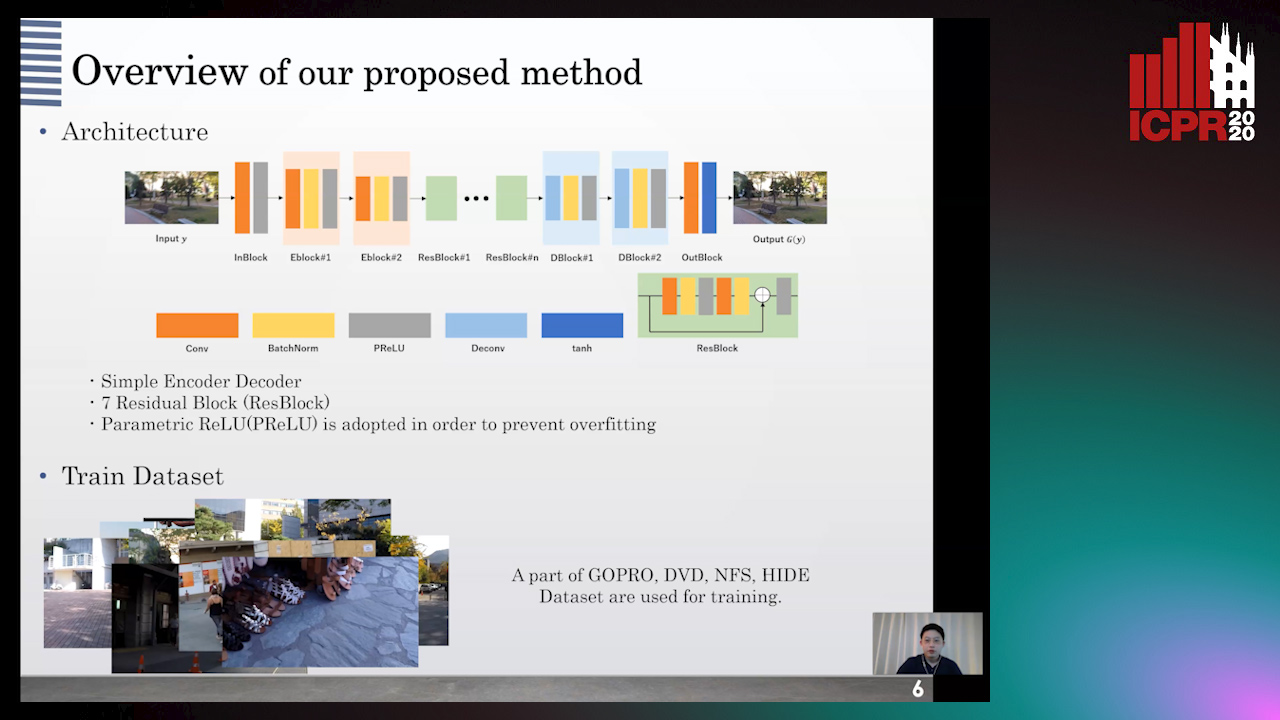
Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Similar papers
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Position-Aware and Symmetry Enhanced GAN for Radial Distortion Correction
Yongjie Shi, Xin Tong, Jingsi Wen, He Zhao, Xianghua Ying, Jinshi Hongbin Zha

Auto-TLDR; Generative Adversarial Network for Radial Distorted Image Correction
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
A Gated and Bifurcated Stacked U-Net Module for Document Image Dewarping
Hmrishav Bandyopadhyay, Tanmoy Dasgupta, Nibaran Das, Mita Nasipuri

Auto-TLDR; Gated and Bifurcated Stacked U-Net for Dewarping Document Images
Abstract Slides Poster Similar
Efficient Shadow Detection and Removal Using Synthetic Data with Domain Adaptation
Rui Guo, Babajide Ayinde, Hao Sun

Auto-TLDR; Shadow Detection and Removal with Domain Adaptation and Synthetic Image Database
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Deep Photo Relighting by Integrating Both 2D and 3D Lighting Information
Takashi Machida, Satoru Nakanishi

Auto-TLDR; DPR: Deep Photorelighting for Image Detection/Classification and Data Augmentation
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
Object Features and Face Detection Performance: Analyses with 3D-Rendered Synthetic Data
Jian Han, Sezer Karaoglu, Hoang-An Le, Theo Gevers

Auto-TLDR; Synthetic Data for Face Detection Using 3DU Face Dataset
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
Semi-Supervised Outdoor Image Generation Conditioned on Weather Signals
Sota Kawakami, Kei Okada, Naoko Nitta, Kazuaki Nakamura, Noboru Babaguchi

Auto-TLDR; Semi-supervised Generative Adversarial Network for Prediction of Weather Signals from Outdoor Images
Abstract Slides Poster Similar
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Ryota Akai, Yuzuko Utsumi, Yuka Miwa, Masakazu Iwamura, Koichi Kise

Auto-TLDR; Object Counting for Omnidirectional Images Using Stereographic Projection
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Continuous Learning of Face Attribute Synthesis
Ning Xin, Shaohui Xu, Fangzhe Nan, Xiaoli Dong, Weijun Li, Yuanzhou Yao

Auto-TLDR; Continuous Learning for Face Attribute Synthesis
Abstract Slides Poster Similar
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
Single Image Super-Resolution with Dynamic Residual Connection
Karam Park, Jae Woong Soh, Nam Ik Cho

Auto-TLDR; Dynamic Residual Attention Network for Lightweight Single Image Super-Residual Networks
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Boundary Guided Image Translation for Pose Estimation from Ultra-Low Resolution Thermal Sensor
Kohei Kurihara, Tianren Wang, Teng Zhang, Brian Carrington Lovell

Auto-TLDR; Pose Estimation on Low-Resolution Thermal Images Using Image-to-Image Translation Architecture
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Foreground-Focused Domain Adaption for Object Detection

Auto-TLDR; Unsupervised Domain Adaptation for Unsupervised Object Detection
Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li, Xiaopeng Zheng, Bir Bhanu, Shun Long, Qingfeng Zhang, Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Abstract Slides Poster Similar
Quantifying the Use of Domain Randomization
Mohammad Ani, Hector Basevi, Ales Leonardis

Auto-TLDR; Evaluating Domain Randomization for Synthetic Image Generation by directly measuring the difference between realistic and synthetic data distributions
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Novel View Synthesis from a 6-DoF Pose by Two-Stage Networks
Xiang Guo, Bo Li, Yuchao Dai, Tongxin Zhang, Hui Deng

Auto-TLDR; Novel View Synthesis from a 6-DoF Pose Using Generative Adversarial Network
Abstract Slides Poster Similar
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar