Towards Artifacts-Free Image Defogging
Gabriele Graffieti,
Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
Similar papers
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Multi-Laplacian GAN with Edge Enhancement for Face Super Resolution

Auto-TLDR; Face Image Super-Resolution with Enhanced Edge Information
Abstract Slides Poster Similar
Galaxy Image Translation with Semi-Supervised Noise-Reconstructed Generative Adversarial Networks
Qiufan Lin, Dominique Fouchez, Jérôme Pasquet

Auto-TLDR; Semi-supervised Image Translation with Generative Adversarial Networks Using Paired and Unpaired Images
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
Detail Fusion GAN: High-Quality Translation for Unpaired Images with GAN-Based Data Augmentation
Ling Li, Yaochen Li, Chuan Wu, Hang Dong, Peilin Jiang, Fei Wang

Auto-TLDR; Data Augmentation with GAN-based Generative Adversarial Network
Abstract Slides Poster Similar
Cycle-Consistent Adversarial Networks and Fast Adaptive Bi-Dimensional Empirical Mode Decomposition for Style Transfer
Elissavet Batziou, Petros Alvanitopoulos, Konstantinos Ioannidis, Ioannis Patras, Stefanos Vrochidis, Ioannis Kompatsiaris

Auto-TLDR; FABEMD: Fast and Adaptive Bidimensional Empirical Mode Decomposition for Style Transfer on Images
Abstract Slides Poster Similar
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Efficient Shadow Detection and Removal Using Synthetic Data with Domain Adaptation
Rui Guo, Babajide Ayinde, Hao Sun

Auto-TLDR; Shadow Detection and Removal with Domain Adaptation and Synthetic Image Database
Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li, Xiaopeng Zheng, Bir Bhanu, Shun Long, Qingfeng Zhang, Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Abstract Slides Poster Similar
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
Boundary Guided Image Translation for Pose Estimation from Ultra-Low Resolution Thermal Sensor
Kohei Kurihara, Tianren Wang, Teng Zhang, Brian Carrington Lovell

Auto-TLDR; Pose Estimation on Low-Resolution Thermal Images Using Image-to-Image Translation Architecture
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Robust Pedestrian Detection in Thermal Imagery Using Synthesized Images
My Kieu, Lorenzo Berlincioni, Leonardo Galteri, Marco Bertini, Andrew Bagdanov, Alberto Del Bimbo

Auto-TLDR; Improving Pedestrian Detection in the thermal domain using Generative Adversarial Network
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
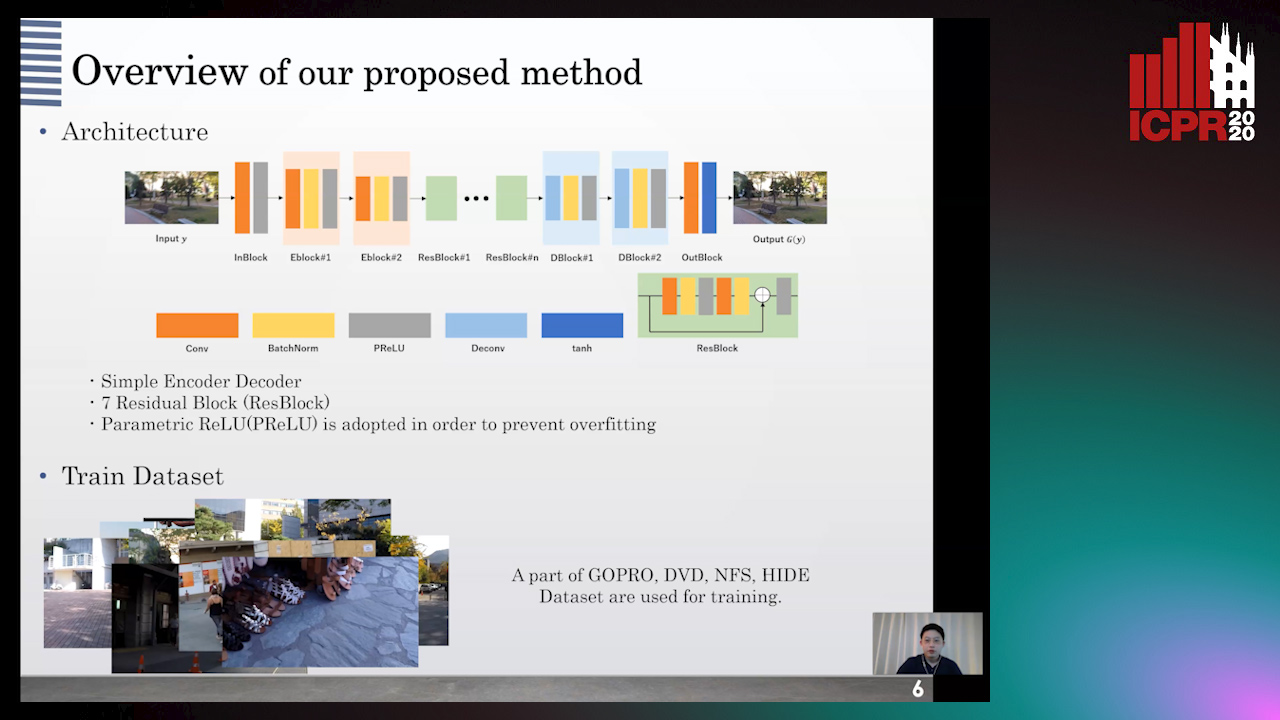
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Stylized-Colorization for Line Arts
Tzu-Ting Fang, Minh Duc Vo, Akihiro Sugimoto, Shang-Hong Lai

Auto-TLDR; Stylized-colorization using GAN-based End-to-End Model for Anime
Abstract Slides Poster Similar
High Resolution Face Age Editing
Xu Yao, Gilles Puy, Alasdair Newson, Yann Gousseau, Pierre Hellier

Auto-TLDR; An Encoder-Decoder Architecture for Face Age editing on High Resolution Images
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
The Role of Cycle Consistency for Generating Better Human Action Videos from a Single Frame

Auto-TLDR; Generating Videos with Human Action Semantics using Cycle Constraints
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Super-Resolution Guided Pore Detection for Fingerprint Recognition
Syeda Nyma Ferdous, Ali Dabouei, Jeremy Dawson, Nasser M. Nasarabadi

Auto-TLDR; Super-Resolution Generative Adversarial Network for Fingerprint Recognition Using Pore Features
Abstract Slides Poster Similar
Small Object Detection Leveraging on Simultaneous Super-Resolution
Hong Ji, Zhi Gao, Xiaodong Liu, Tiancan Mei

Auto-TLDR; Super-Resolution via Generative Adversarial Network for Small Object Detection
Tarsier: Evolving Noise Injection inSuper-Resolution GANs
Baptiste Roziere, Nathanaël Carraz Rakotonirina, Vlad Hosu, Rasoanaivo Andry, Hanhe Lin, Camille Couprie, Olivier Teytaud

Auto-TLDR; Evolutionary Super-Resolution using Diagonal CMA
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Multi-Domain Image-To-Image Translation with Adaptive Inference Graph
The Phuc Nguyen, Stéphane Lathuiliere, Elisa Ricci

Auto-TLDR; Adaptive Graph Structure for Multi-Domain Image-to-Image Translation
Abstract Slides Poster Similar
Improving Low-Resolution Image Classification by Super-Resolution with Enhancing High-Frequency Content
Liguo Zhou, Guang Chen, Mingyue Feng, Alois Knoll

Auto-TLDR; Super-resolution for Low-Resolution Image Classification
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Continuous Learning of Face Attribute Synthesis
Ning Xin, Shaohui Xu, Fangzhe Nan, Xiaoli Dong, Weijun Li, Yuanzhou Yao

Auto-TLDR; Continuous Learning for Face Attribute Synthesis
Abstract Slides Poster Similar
Makeup Style Transfer on Low-Quality Images with Weighted Multi-Scale Attention
Daniel Organisciak, Edmond S. L. Ho, Shum Hubert P. H.

Auto-TLDR; Facial Makeup Style Transfer for Low-Resolution Images Using Multi-Scale Spatial Attention
Abstract Slides Poster Similar
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
The Surprising Effectiveness of Linear Unsupervised Image-to-Image Translation

Auto-TLDR; linear encoder-decoder architectures for unsupervised image-to-image translation
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Pierfrancesco Ardino, Yahui Liu, Elisa Ricci, Bruno Lepri, Marco De Nadai

Auto-TLDR; Semantic-Guided Inpainting of Complex Urban Scene Using Semantic Segmentation and Generation
Abstract Slides Poster Similar
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Learning Disentangled Representations for Identity Preserving Surveillance Face Camouflage
Jingzhi Li, Lutong Han, Hua Zhang, Xiaoguang Han, Jingguo Ge, Xiaochu Cao

Auto-TLDR; Individual Face Privacy under Surveillance Scenario with Multi-task Loss Function
Global Image Sentiment Transfer
Jie An, Tianlang Chen, Songyang Zhang, Jiebo Luo

Auto-TLDR; Image Sentiment Transfer Using DenseNet121 Architecture
Semi-Supervised Outdoor Image Generation Conditioned on Weather Signals
Sota Kawakami, Kei Okada, Naoko Nitta, Kazuaki Nakamura, Noboru Babaguchi

Auto-TLDR; Semi-supervised Generative Adversarial Network for Prediction of Weather Signals from Outdoor Images
Abstract Slides Poster Similar
Multi-scale Processing of Noisy Images using Edge Preservation Losses

Auto-TLDR; Multi-scale U-net for Noisy Image Detection and Denoising
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Semantic Object Segmentation in Cultural Sites Using Real and Synthetic Data
Francesco Ragusa, Daniele Di Mauro, Alfio Palermo, Antonino Furnari, Giovanni Maria Farinella

Auto-TLDR; Exploiting Synthetic Data for Object Segmentation in Cultural Sites
Abstract Slides Poster Similar