Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li,
Xiaopeng Zheng,
Bir Bhanu,
Shun Long,
Qingfeng Zhang,
Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Similar papers
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
Visibility Restoration in Infra-Red Images
Olivier Fourt, Jean-Philippe Tarel

Auto-TLDR; Single Image Defogging for Long-Wavelength Infra-Red (LWIR)
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
Improving Low-Resolution Image Classification by Super-Resolution with Enhancing High-Frequency Content
Liguo Zhou, Guang Chen, Mingyue Feng, Alois Knoll

Auto-TLDR; Super-resolution for Low-Resolution Image Classification
Abstract Slides Poster Similar
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Polarimetric Image Augmentation
Marc Blanchon, Fabrice Meriaudeau, Olivier Morel, Ralph Seulin, Desire Sidibe

Auto-TLDR; Polarimetric Augmentation for Deep Learning in Robotics Applications
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar
Enhancing Depth Quality of Stereo Vision Using Deep Learning-Based Prior Information of the Driving Environment
Weifu Li, Vijay John, Seiichi Mita

Auto-TLDR; A Novel Post-processing Mathematical Framework for Stereo Vision
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Multi-focus Image Fusion for Confocal Microscopy Using U-Net Regression Map
Md Maruf Hossain Shuvo, Yasmin M. Kassim, Filiz Bunyak, Olga V. Glinskii, Leike Xie, Vladislav V Glinsky, Virginia H. Huxley, Kannappan Palaniappan

Auto-TLDR; Independent Single Channel U-Net Fusion for Multi-focus Microscopy Images
Abstract Slides Poster Similar
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
Face Super-Resolution Network with Incremental Enhancement of Facial Parsing Information
Shuang Liu, Chengyi Xiong, Zhirong Gao

Auto-TLDR; Learning-based Face Super-Resolution with Incremental Boosting Facial Parsing Information
Abstract Slides Poster Similar
Coarse-To-Fine Foreground Segmentation Based on Co-Occurrence Pixel-Block and Spatio-Temporal Attention Model

Auto-TLDR; Foreground Segmentation from coarse to Fine Using Co-occurrence Pixel-Block Model for Dynamic Scene
Abstract Slides Poster Similar
A Multi-Focus Image Fusion Method Based on Fractal Dimension and Guided Filtering
Nikoo Dehghani, Ehsanollah Kabir

Auto-TLDR; Fractal Dimension-based Multi-focus Image Fusion with Guide Filtering
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Semi-Supervised Deep Learning Techniques for Spectrum Reconstruction
Adriano Simonetto, Vincent Parret, Alexander Gatto, Piergiorgio Sartor, Pietro Zanuttigh

Auto-TLDR; hyperspectral data estimation from RGB data using semi-supervised learning
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu, Meifang Yang, Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
Selective Kernel and Motion-Emphasized Loss Based Attention-Guided Network for HDR Imaging of Dynamic Scenes
Yipeng Deng, Qin Liu, Takeshi Ikenaga

Auto-TLDR; SK-AHDRNet: A Deep Network with attention module and motion-emphasized loss function to produce ghost-free HDR images
Abstract Slides Poster Similar
Color, Edge, and Pixel-Wise Explanation of Predictions Based onInterpretable Neural Network Model

Auto-TLDR; Explainable Deep Neural Network with Edge Detecting Filters
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
Breast Anatomy Enriched Tumor Saliency Estimation
Fei Xu, Yingtao Zhang, Heng-Da Cheng, Jianrui Ding, Boyu Zhang, Chunping Ning, Ying Wang

Auto-TLDR; Tumor Saliency Estimation for Breast Ultrasound using enriched breast anatomy knowledge
Abstract Slides Poster Similar
A Scalable Deep Neural Network to Detect Low Quality Images without a Reference
Auto-TLDR; A Deep Neural Network-based Algorithm for Non-reference Non-Reference Non-Referential Image Quality Metrics for Streaming Services
Abstract Slides Poster Similar
RONELD: Robust Neural Network Output Enhancement for Active Lane Detection
Zhe Ming Chng, Joseph Mun Hung Lew, Jimmy Addison Lee

Auto-TLDR; Real-Time Robust Neural Network Output Enhancement for Active Lane Detection
Abstract Slides Poster Similar
An Adaptive Model for Face Distortion Correction

Auto-TLDR; Adaptive Polynomial Model for Face Distortion Correction in Selfie Photos
Fast Multi-Level Foreground Estimation
Thomas Germer, Tobias Uelwer, Stefan Conrad, Stefan Harmeling

Auto-TLDR; Fur foreground estimation given the alpha matte
Abstract Slides Poster Similar
TSDM: Tracking by SiamRPN++ with a Depth-Refiner and a Mask-Generator
Pengyao Zhao, Quanli Liu, Wei Wang, Qiang Guo

Auto-TLDR; TSDM: A Depth-D Tracker for 3D Object Tracking
Abstract Slides Poster Similar
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
Fused 3-Stage Image Segmentation for Pleural Effusion Cell Clusters
Sike Ma, Meng Zhao, Hao Wang, Fan Shi, Xuguo Sun, Shengyong Chen, Hong-Ning Dai

Auto-TLDR; Coarse Segmentation of Stained and Stained Unstained Cell Clusters in pleural effusion using 3-stage segmentation method
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
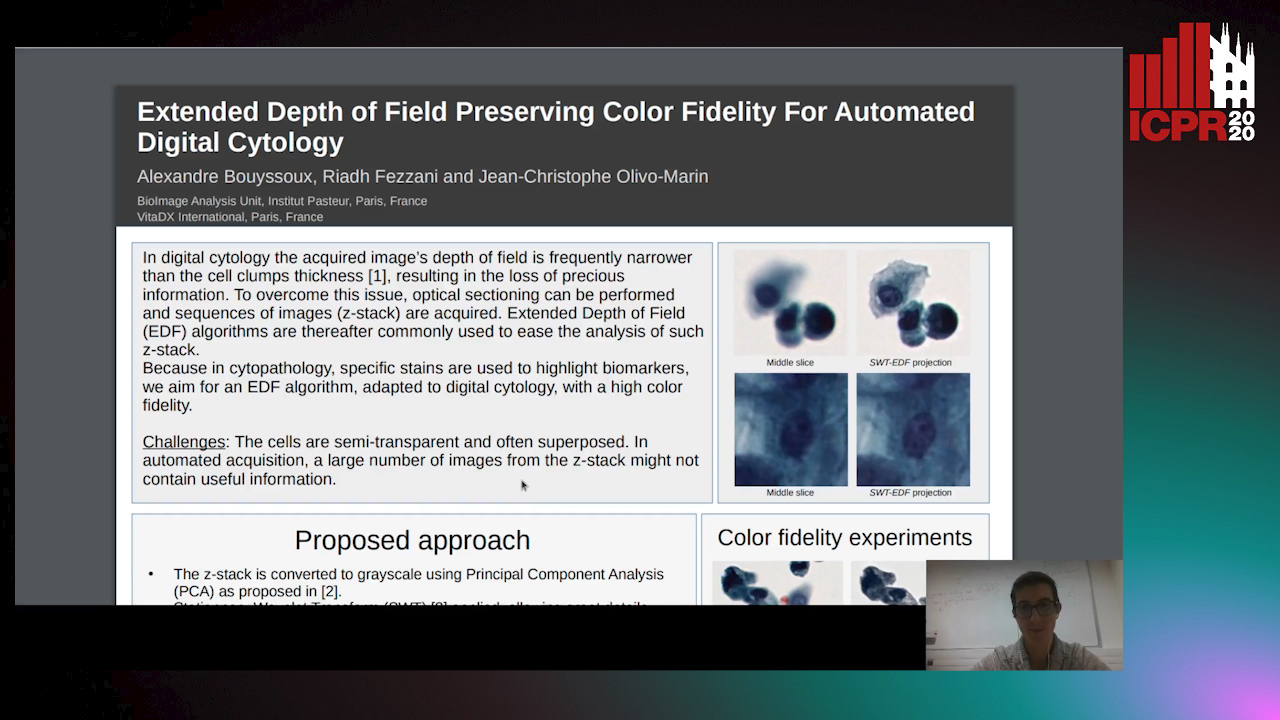
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform