Multi-focus Image Fusion for Confocal Microscopy Using U-Net Regression Map
Md Maruf Hossain Shuvo,
Yasmin M. Kassim,
Filiz Bunyak,
Olga V. Glinskii,
Leike Xie,
Vladislav V Glinsky,
Virginia H. Huxley,
Kannappan Palaniappan

Auto-TLDR; Independent Single Channel U-Net Fusion for Multi-focus Microscopy Images
Similar papers
A Multi-Focus Image Fusion Method Based on Fractal Dimension and Guided Filtering
Nikoo Dehghani, Ehsanollah Kabir

Auto-TLDR; Fractal Dimension-based Multi-focus Image Fusion with Guide Filtering
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
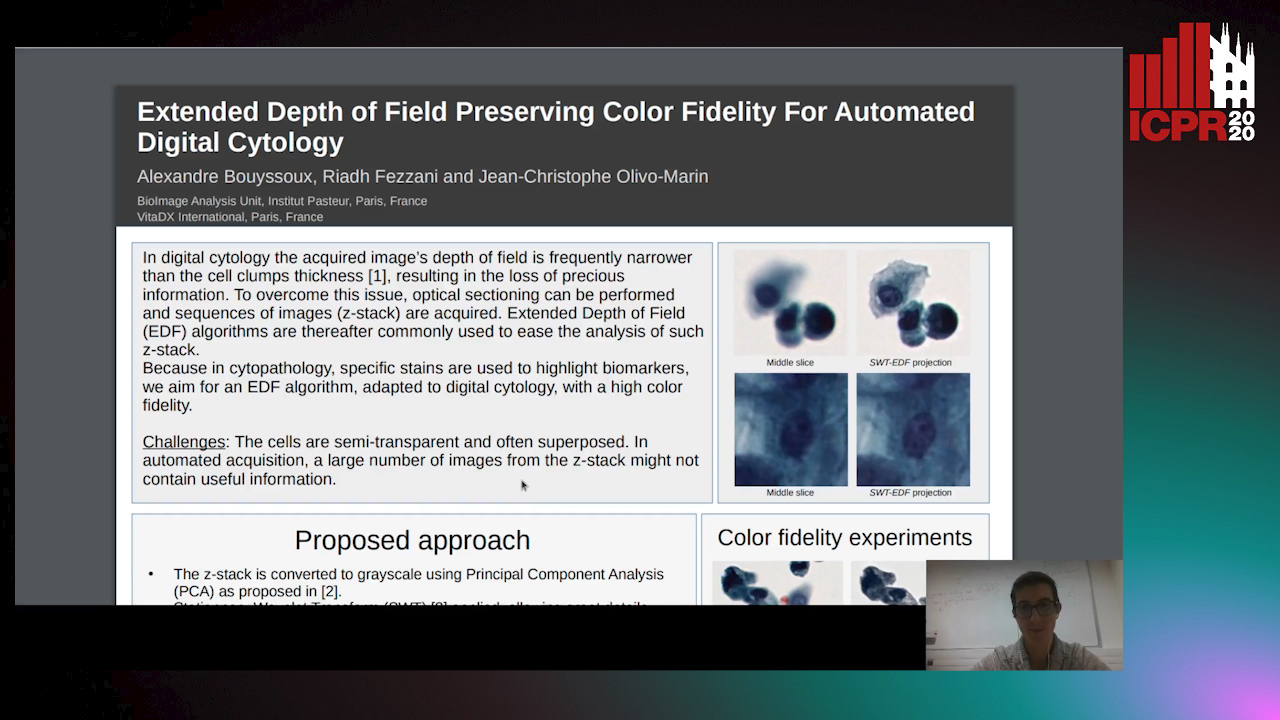
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
A Dual-Branch Network for Infrared and Visible Image Fusion

Auto-TLDR; Image Fusion Using Autoencoder for Deep Learning
Abstract Slides Poster Similar
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
CSpA-DN: Channel and Spatial Attention Dense Network for Fusing PET and MRI Images
Bicao Li, Zhoufeng Liu, Shan Gao, Jenq-Neng Hwang, Jun Sun, Zongmin Wang

Auto-TLDR; CSpA-DN: Unsupervised Fusion of PET and MR Images with Channel and Spatial Attention
Abstract Slides Poster Similar
Transfer Learning through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Abdullah Sarhan, Jon Rokne, Reda Alhajj, Andrew Crichton

Auto-TLDR; Deep Learning for Segmentation of Blood Vessels in Retinal Images
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Vesselness Filters: A Survey with Benchmarks Applied to Liver Imaging
Jonas Lamy, Odyssée Merveille, Bertrand Kerautret, Nicolas Passat, Antoine Vacavant

Auto-TLDR; Comparison of Vessel Enhancement Filters for Liver Vascular Network Segmentation
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Do Not Treat Boundaries and Regions Differently: An Example on Heart Left Atrial Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; Attention Full Convolutional Network for Atrial Segmentation using ResNet-101 Architecture
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
PCANet: Pyramid Context-Aware Network for Retinal Vessel Segmentation
Yi Zhang, Yixuan Chen, Kai Zhang

Auto-TLDR; PCANet: Adaptive Context-Aware Network for Automated Retinal Vessel Segmentation
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
DA-RefineNet: Dual-Inputs Attention RefineNet for Whole Slide Image Segmentation
Ziqiang Li, Rentuo Tao, Qianrun Wu, Bin Li

Auto-TLDR; DA-RefineNet: A dual-inputs attention network for whole slide image segmentation
Abstract Slides Poster Similar
DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu, Meifang Yang, Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
NephCNN: A Deep-Learning Framework for Vessel Segmentation in Nephrectomy Laparoscopic Videos
Alessandro Casella, Sara Moccia, Chiara Carlini, Emanuele Frontoni, Elena De Momi, Leonardo Mattos

Auto-TLDR; Adversarial Fully Convolutional Neural Networks for kidney vessel segmentation from nephrectomy laparoscopic videos
Abstract Slides Poster Similar
Multi-scale Processing of Noisy Images using Edge Preservation Losses

Auto-TLDR; Multi-scale U-net for Noisy Image Detection and Denoising
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
BCAU-Net: A Novel Architecture with Binary Channel Attention Module for MRI Brain Segmentation
Yongpei Zhu, Zicong Zhou, Guojun Liao, Kehong Yuan

Auto-TLDR; BCAU-Net: Binary Channel Attention U-Net for MRI brain segmentation
Abstract Slides Poster Similar
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
Few Shot Learning Framework to Reduce Inter-Observer Variability in Medical Images

Auto-TLDR; Few-Shot Learning for Quality Image Annotation
Abstract Slides Poster Similar
A Scalable Deep Neural Network to Detect Low Quality Images without a Reference
Auto-TLDR; A Deep Neural Network-based Algorithm for Non-reference Non-Reference Non-Referential Image Quality Metrics for Streaming Services
Abstract Slides Poster Similar
MTGAN: Mask and Texture-Driven Generative Adversarial Network for Lung Nodule Segmentation
Wei Chen, Qiuli Wang, Kun Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; Mask and Texture-driven Generative Adversarial Network for Lung Nodule Segmentation
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation
Changlu Guo, Marton Szemenyei, Yugen Yi, Wenle Wang, Buer Chen, Changqi Fan

Auto-TLDR; Spatial Attention U-Net for Segmentation of Retinal Blood Vessels
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
BiLuNet: A Multi-Path Network for Semantic Segmentation on X-Ray Images
Van Luan Tran, Huei-Yung Lin, Rachel Liu, Chun-Han Tseng, Chun-Han Tseng

Auto-TLDR; BiLuNet: Multi-path Convolutional Neural Network for Semantic Segmentation of Lumbar vertebrae, sacrum,
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
Deep Recurrent-Convolutional Model for AutomatedSegmentation of Craniomaxillofacial CT Scans
Francesca Murabito, Simone Palazzo, Federica Salanitri Proietto, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Segmentation of Anatomical Structures in Craniomaxillofacial CT Scans using Fully Convolutional Deep Networks
Abstract Slides Poster Similar
BG-Net: Boundary-Guided Network for Lung Segmentation on Clinical CT Images
Rui Xu, Yi Wang, Tiantian Liu, Xinchen Ye, Lin Lin, Yen-Wei Chen, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; Boundary-Guided Network for Lung Segmentation on CT Images
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
D3Net: Joint Demosaicking, Deblurring and Deringing
Tomas Kerepecky, Filip Sroubek

Auto-TLDR; Joint demosaicking deblurring and deringing network with light-weight architecture inspired by the alternating direction method of multipliers
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
Neural Machine Registration for Motion Correction in Breast DCE-MRI
Federica Aprea, Stefano Marrone, Carlo Sansone

Auto-TLDR; A Neural Registration Network for Dynamic Contrast Enhanced-Magnetic Resonance Imaging
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
One-Stage Multi-Task Detector for 3D Cardiac MR Imaging
Weizeng Lu, Xi Jia, Wei Chen, Nicolò Savioli, Antonio De Marvao, Linlin Shen, Declan O'Regan, Jinming Duan

Auto-TLDR; Multi-task Learning for Real-Time, simultaneous landmark location and bounding box detection in 3D space
Abstract Slides Poster Similar
3D Semantic Labeling of Photogrammetry Meshes Based on Active Learning
Mengqi Rong, Shuhan Shen, Zhanyi Hu

Auto-TLDR; 3D Semantic Expression of Urban Scenes Based on Active Learning
Abstract Slides Poster Similar
Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li, Xiaopeng Zheng, Bir Bhanu, Shun Long, Qingfeng Zhang, Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Abstract Slides Poster Similar