Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux,
Riadh Fezzani,
Jean-Christophe Olivo-Marin
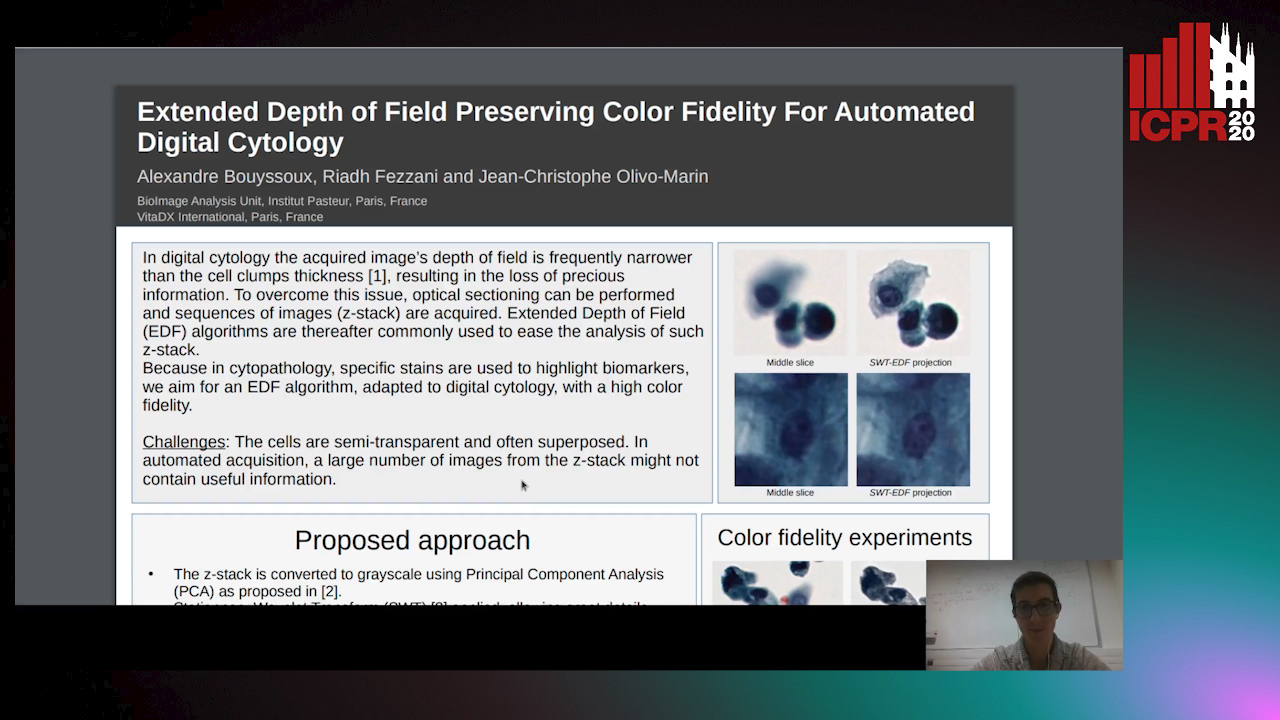
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
Similar papers
Multi-focus Image Fusion for Confocal Microscopy Using U-Net Regression Map
Md Maruf Hossain Shuvo, Yasmin M. Kassim, Filiz Bunyak, Olga V. Glinskii, Leike Xie, Vladislav V Glinsky, Virginia H. Huxley, Kannappan Palaniappan

Auto-TLDR; Independent Single Channel U-Net Fusion for Multi-focus Microscopy Images
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
MedZip: 3D Medical Images Lossless Compressor Using Recurrent Neural Network (LSTM)
Omniah Nagoor, Joss Whittle, Jingjing Deng, Benjamin Mora, Mark W. Jones

Auto-TLDR; Recurrent Neural Network for Lossless Medical Image Compression using Long Short-Term Memory
A Multi-Focus Image Fusion Method Based on Fractal Dimension and Guided Filtering
Nikoo Dehghani, Ehsanollah Kabir

Auto-TLDR; Fractal Dimension-based Multi-focus Image Fusion with Guide Filtering
Abstract Slides Poster Similar
Weakly Supervised Geodesic Segmentation of Egyptian Mummy CT Scans
Avik Hati, Matteo Bustreo, Diego Sona, Vittorio Murino, Alessio Del Bue

Auto-TLDR; A Weakly Supervised and Efficient Interactive Segmentation of Ancient Egyptian Mummies CT Scans Using Geodesic Distance Measure and GrabCut
Abstract Slides Poster Similar
A Dual-Branch Network for Infrared and Visible Image Fusion

Auto-TLDR; Image Fusion Using Autoencoder for Deep Learning
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise
Anne-Sophie Collin, Christophe De Vleeschouwer

Auto-TLDR; Autoencoder with Skip Connections for Anomaly Detection
Abstract Slides Poster Similar
Few Shot Learning Framework to Reduce Inter-Observer Variability in Medical Images

Auto-TLDR; Few-Shot Learning for Quality Image Annotation
Abstract Slides Poster Similar
Deep Learning-Based Type Identification of Volumetric MRI Sequences
Jean Pablo De Mello, Thiago Paixão, Rodrigo Berriel, Mauricio Reyes, Alberto F. De Souza, Claudine Badue, Thiago Oliveira-Santos

Auto-TLDR; Deep Learning for Brain MRI Sequences Identification Using Convolutional Neural Network
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
Polarimetric Image Augmentation
Marc Blanchon, Fabrice Meriaudeau, Olivier Morel, Ralph Seulin, Desire Sidibe

Auto-TLDR; Polarimetric Augmentation for Deep Learning in Robotics Applications
Semi-Supervised Deep Learning Techniques for Spectrum Reconstruction
Adriano Simonetto, Vincent Parret, Alexander Gatto, Piergiorgio Sartor, Pietro Zanuttigh

Auto-TLDR; hyperspectral data estimation from RGB data using semi-supervised learning
Abstract Slides Poster Similar
Vesselness Filters: A Survey with Benchmarks Applied to Liver Imaging
Jonas Lamy, Odyssée Merveille, Bertrand Kerautret, Nicolas Passat, Antoine Vacavant

Auto-TLDR; Comparison of Vessel Enhancement Filters for Liver Vascular Network Segmentation
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li, Xiaopeng Zheng, Bir Bhanu, Shun Long, Qingfeng Zhang, Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Abstract Slides Poster Similar
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar
Segmentation of Axillary and Supraclavicular Tumoral Lymph Nodes in PET/CT: A Hybrid CNN/Component-Tree Approach
Diana Lucia Farfan Cabrera, Nicolas Gogin, David Morland, Benoît Naegel, Dimitri Papathanassiou, Nicolas Passat

Auto-TLDR; Coupling Convolutional Neural Networks and Component-Trees for Lymph node Segmentation from PET/CT Images
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Fast and Efficient Neural Network for Light Field Disparity Estimation

Auto-TLDR; Improving Efficient Light Field Disparity Estimation Using Deep Neural Networks
Abstract Slides Poster Similar
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana

Auto-TLDR; Entropy Partitioning Decision Tree for Connected Components Labeling
Abstract Slides Poster Similar
2D Discrete Mirror Transform for Image Non-Linear Approximation
Alessandro Gnutti, Fabrizio Guerrini, Riccardo Leonardi

Auto-TLDR; Discrete Mirror Transform (DMT)
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
D3Net: Joint Demosaicking, Deblurring and Deringing
Tomas Kerepecky, Filip Sroubek

Auto-TLDR; Joint demosaicking deblurring and deringing network with light-weight architecture inspired by the alternating direction method of multipliers
EdgeNet: Semantic Scene Completion from a Single RGB-D Image
Aloisio Dourado, Teofilo De Campos, Adrian Hilton, Hansung Kim

Auto-TLDR; Semantic Scene Completion using 3D Depth and RGB Information
Abstract Slides Poster Similar
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
CSpA-DN: Channel and Spatial Attention Dense Network for Fusing PET and MRI Images
Bicao Li, Zhoufeng Liu, Shan Gao, Jenq-Neng Hwang, Jun Sun, Zongmin Wang

Auto-TLDR; CSpA-DN: Unsupervised Fusion of PET and MR Images with Channel and Spatial Attention
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
Phase Retrieval Using Conditional Generative Adversarial Networks
Tobias Uelwer, Alexander Oberstraß, Stefan Harmeling

Auto-TLDR; Conditional Generative Adversarial Networks for Phase Retrieval
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
GraphBGS: Background Subtraction Via Recovery of Graph Signals
Jhony Heriberto Giraldo Zuluaga, Thierry Bouwmans

Auto-TLDR; Graph BackGround Subtraction using Graph Signals
Abstract Slides Poster Similar
A Bayesian Deep CNN Framework for Reconstructing K-T-Undersampled Resting-fMRI
Karan Taneja, Prachi Kulkarni, Shabbir Merchant, Suyash Awate

Auto-TLDR; K-t undersampled R-fMRI Reconstruction using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Enhancing Deep Semantic Segmentation of RGB-D Data with Entangled Forests
Matteo Terreran, Elia Bonetto, Stefano Ghidoni

Auto-TLDR; FuseNet: A Lighter Deep Learning Model for Semantic Segmentation
Abstract Slides Poster Similar
A Lumen Segmentation Method in Ureteroscopy Images Based on a Deep Residual U-Net Architecture
Jorge Lazo, Marzullo Aldo, Sara Moccia, Michele Catellani, Benoit Rosa, Elena De Momi, Michel De Mathelin, Francesco Calimeri

Auto-TLDR; A Deep Neural Network for Ureteroscopy with Residual Units
Abstract Slides Poster Similar
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar