Weakly Supervised Geodesic Segmentation of Egyptian Mummy CT Scans
Avik Hati,
Matteo Bustreo,
Diego Sona,
Vittorio Murino,
Alessio Del Bue

Auto-TLDR; A Weakly Supervised and Efficient Interactive Segmentation of Ancient Egyptian Mummies CT Scans Using Geodesic Distance Measure and GrabCut
Similar papers
Deep Multi-Stage Model for Automated Landmarking of Craniomaxillofacial CT Scans
Simone Palazzo, Giovanni Bellitto, Luca Prezzavento, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Landmarking of Craniomaxillofacial CT Images Using Deep Multi-Stage Architecture
Segmentation of Axillary and Supraclavicular Tumoral Lymph Nodes in PET/CT: A Hybrid CNN/Component-Tree Approach
Diana Lucia Farfan Cabrera, Nicolas Gogin, David Morland, Benoît Naegel, Dimitri Papathanassiou, Nicolas Passat

Auto-TLDR; Coupling Convolutional Neural Networks and Component-Trees for Lymph node Segmentation from PET/CT Images
Robust Skeletonization for Plant Root Structure Reconstruction from MRI

Auto-TLDR; Structural reconstruction of plant roots from MRI using semantic root vs shoot segmentation and 3D skeletonization
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana

Auto-TLDR; Entropy Partitioning Decision Tree for Connected Components Labeling
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Deep Recurrent-Convolutional Model for AutomatedSegmentation of Craniomaxillofacial CT Scans
Francesca Murabito, Simone Palazzo, Federica Salanitri Proietto, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Segmentation of Anatomical Structures in Craniomaxillofacial CT Scans using Fully Convolutional Deep Networks
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
A Multi-Task Contextual Atrous Residual Network for Brain Tumor Detection & Segmentation
Ngan Le, Kashu Yamazaki, Quach Kha Gia, Thanh-Dat Truong, Marios Savvides

Auto-TLDR; Contextual Brain Tumor Segmentation Using 3D atrous Residual Networks and Cascaded Structures
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Motion-Supervised Co-Part Segmentation
Aliaksandr Siarohin, Subhankar Roy, Stéphane Lathuiliere, Sergey Tulyakov, Elisa Ricci, Nicu Sebe

Auto-TLDR; Self-supervised Co-Part Segmentation Using Motion Information from Videos
BiLuNet: A Multi-Path Network for Semantic Segmentation on X-Ray Images
Van Luan Tran, Huei-Yung Lin, Rachel Liu, Chun-Han Tseng, Chun-Han Tseng

Auto-TLDR; BiLuNet: Multi-path Convolutional Neural Network for Semantic Segmentation of Lumbar vertebrae, sacrum,
One-Stage Multi-Task Detector for 3D Cardiac MR Imaging
Weizeng Lu, Xi Jia, Wei Chen, Nicolò Savioli, Antonio De Marvao, Linlin Shen, Declan O'Regan, Jinming Duan

Auto-TLDR; Multi-task Learning for Real-Time, simultaneous landmark location and bounding box detection in 3D space
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
MTGAN: Mask and Texture-Driven Generative Adversarial Network for Lung Nodule Segmentation
Wei Chen, Qiuli Wang, Kun Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; Mask and Texture-driven Generative Adversarial Network for Lung Nodule Segmentation
Abstract Slides Poster Similar
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar
A Hierarchical Framework for Leaf Instance Segmentation: Application to Plant Phenotyping
Swati Bhugra, Kanish Garg, Santanu Chaudhury, Brejesh Lall

Auto-TLDR; Under-segmentation of plant image using a graph based formulation to extract leaf shape knowledge for the task of leaf instance segmentation
Abstract Slides Poster Similar
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
Learning Object Deformation and Motion Adaption for Semi-Supervised Video Object Segmentation
Xiaoyang Zheng, Xin Tan, Jianming Guo, Lizhuang Ma

Auto-TLDR; Semi-supervised Video Object Segmentation with Mask-propagation-based Model
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
SynDHN: Multi-Object Fish Tracker Trained on Synthetic Underwater Videos
Mygel Andrei Martija, Prospero Naval

Auto-TLDR; Underwater Multi-Object Tracking in the Wild with Deep Hungarian Network
Abstract Slides Poster Similar
A Lumen Segmentation Method in Ureteroscopy Images Based on a Deep Residual U-Net Architecture
Jorge Lazo, Marzullo Aldo, Sara Moccia, Michele Catellani, Benoit Rosa, Elena De Momi, Michel De Mathelin, Francesco Calimeri

Auto-TLDR; A Deep Neural Network for Ureteroscopy with Residual Units
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Vesselness Filters: A Survey with Benchmarks Applied to Liver Imaging
Jonas Lamy, Odyssée Merveille, Bertrand Kerautret, Nicolas Passat, Antoine Vacavant

Auto-TLDR; Comparison of Vessel Enhancement Filters for Liver Vascular Network Segmentation
Abstract Slides Poster Similar
Unconstrained Vision Guided UAV Based Safe Helicopter Landing
Arindam Sikdar, Abhimanyu Sahu, Debajit Sen, Rohit Mahajan, Ananda Chowdhury

Auto-TLDR; Autonomous Helicopter Landing in Hazardous Environments from Unmanned Aerial Images Using Constrained Graph Clustering
Abstract Slides Poster Similar
Few Shot Learning Framework to Reduce Inter-Observer Variability in Medical Images

Auto-TLDR; Few-Shot Learning for Quality Image Annotation
Abstract Slides Poster Similar
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
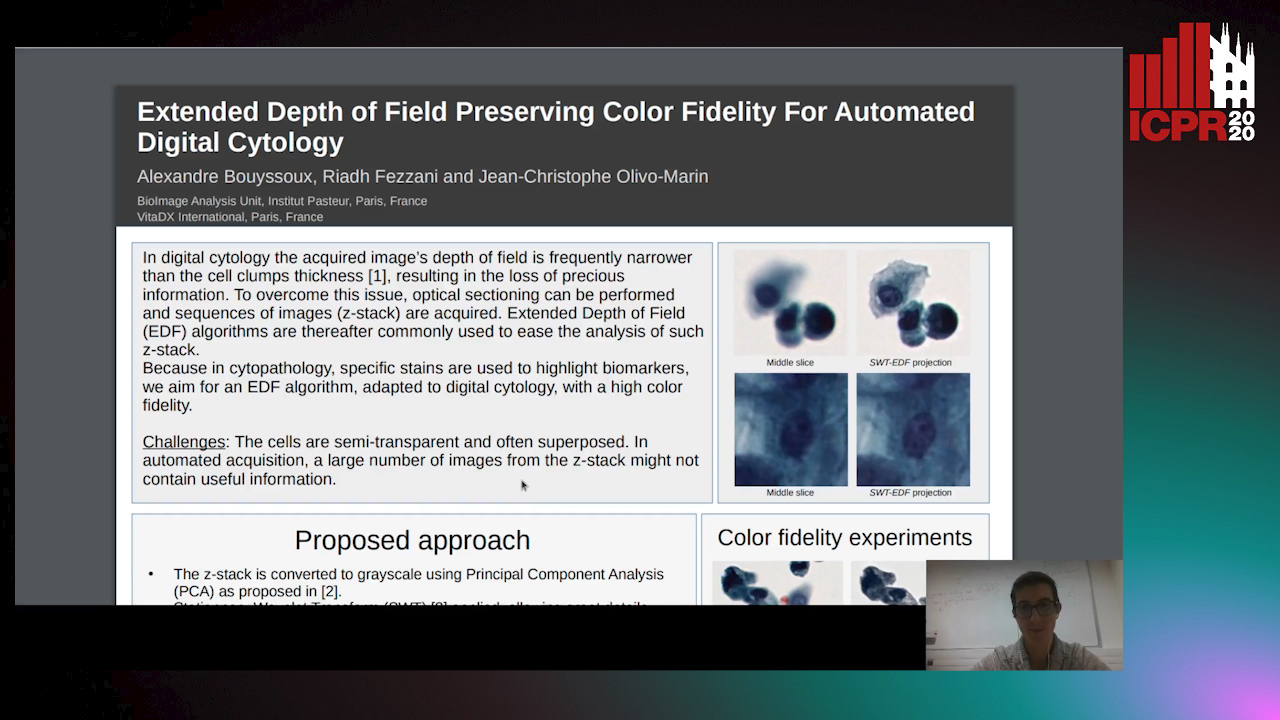
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
Learning to Implicitly Represent 3D Human Body from Multi-Scale Features and Multi-View Images
Zhongguo Li, Magnus Oskarsson, Anders Heyden

Auto-TLDR; Reconstruction of 3D human bodies from multi-view images using multi-stage end-to-end neural networks
Abstract Slides Poster Similar
3D Semantic Labeling of Photogrammetry Meshes Based on Active Learning
Mengqi Rong, Shuhan Shen, Zhanyi Hu

Auto-TLDR; 3D Semantic Expression of Urban Scenes Based on Active Learning
Abstract Slides Poster Similar
Neural Machine Registration for Motion Correction in Breast DCE-MRI
Federica Aprea, Stefano Marrone, Carlo Sansone

Auto-TLDR; A Neural Registration Network for Dynamic Contrast Enhanced-Magnetic Resonance Imaging
Abstract Slides Poster Similar
MedZip: 3D Medical Images Lossless Compressor Using Recurrent Neural Network (LSTM)
Omniah Nagoor, Joss Whittle, Jingjing Deng, Benjamin Mora, Mark W. Jones

Auto-TLDR; Recurrent Neural Network for Lossless Medical Image Compression using Long Short-Term Memory
BG-Net: Boundary-Guided Network for Lung Segmentation on Clinical CT Images
Rui Xu, Yi Wang, Tiantian Liu, Xinchen Ye, Lin Lin, Yen-Wei Chen, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; Boundary-Guided Network for Lung Segmentation on CT Images
Abstract Slides Poster Similar
A Transformer-Based Network for Anisotropic 3D Medical Image Segmentation
Guo Danfeng, Demetri Terzopoulos

Auto-TLDR; A transformer-based model to tackle the anisotropy problem in 3D medical image analysis
Abstract Slides Poster Similar
Enhancing Deep Semantic Segmentation of RGB-D Data with Entangled Forests
Matteo Terreran, Elia Bonetto, Stefano Ghidoni

Auto-TLDR; FuseNet: A Lighter Deep Learning Model for Semantic Segmentation
Abstract Slides Poster Similar
DARN: Deep Attentive Refinement Network for Liver Tumor Segmentation from 3D CT Volume
Yao Zhang, Jiang Tian, Cheng Zhong, Yang Zhang, Zhongchao Shi, Zhiqiang He

Auto-TLDR; Deep Attentive Refinement Network for Liver Tumor Segmentation from 3D Computed Tomography Using Multi-Level Features
Abstract Slides Poster Similar
From Certain to Uncertain: Toward Optimal Solution for Offline Multiple Object Tracking
Kaikai Zhao, Takashi Imaseki, Hiroshi Mouri, Einoshin Suzuki, Tetsu Matsukawa

Auto-TLDR; Agglomerative Hierarchical Clustering with Ensemble of Tracking Experts for Object Tracking
Abstract Slides Poster Similar
Superpixel-Based Refinement for Object Proposal Generation
Christian Wilms, Simone Frintrop

Auto-TLDR; Superpixel-based Refinement of AttentionMask for Object Segmentation
Abstract Slides Poster Similar
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
Do Not Treat Boundaries and Regions Differently: An Example on Heart Left Atrial Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; Attention Full Convolutional Network for Atrial Segmentation using ResNet-101 Architecture