Few Shot Learning Framework to Reduce Inter-Observer Variability in Medical Images

Auto-TLDR; Few-Shot Learning for Quality Image Annotation
Similar papers
Transfer Learning through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Abdullah Sarhan, Jon Rokne, Reda Alhajj, Andrew Crichton

Auto-TLDR; Deep Learning for Segmentation of Blood Vessels in Retinal Images
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
NephCNN: A Deep-Learning Framework for Vessel Segmentation in Nephrectomy Laparoscopic Videos
Alessandro Casella, Sara Moccia, Chiara Carlini, Emanuele Frontoni, Elena De Momi, Leonardo Mattos

Auto-TLDR; Adversarial Fully Convolutional Neural Networks for kidney vessel segmentation from nephrectomy laparoscopic videos
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar
PCANet: Pyramid Context-Aware Network for Retinal Vessel Segmentation
Yi Zhang, Yixuan Chen, Kai Zhang

Auto-TLDR; PCANet: Adaptive Context-Aware Network for Automated Retinal Vessel Segmentation
Abstract Slides Poster Similar
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
BCAU-Net: A Novel Architecture with Binary Channel Attention Module for MRI Brain Segmentation
Yongpei Zhu, Zicong Zhou, Guojun Liao, Kehong Yuan

Auto-TLDR; BCAU-Net: Binary Channel Attention U-Net for MRI brain segmentation
Abstract Slides Poster Similar
MTGAN: Mask and Texture-Driven Generative Adversarial Network for Lung Nodule Segmentation
Wei Chen, Qiuli Wang, Kun Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; Mask and Texture-driven Generative Adversarial Network for Lung Nodule Segmentation
Abstract Slides Poster Similar
A Lumen Segmentation Method in Ureteroscopy Images Based on a Deep Residual U-Net Architecture
Jorge Lazo, Marzullo Aldo, Sara Moccia, Michele Catellani, Benoit Rosa, Elena De Momi, Michel De Mathelin, Francesco Calimeri

Auto-TLDR; A Deep Neural Network for Ureteroscopy with Residual Units
Abstract Slides Poster Similar
Deep Learning-Based Type Identification of Volumetric MRI Sequences
Jean Pablo De Mello, Thiago Paixão, Rodrigo Berriel, Mauricio Reyes, Alberto F. De Souza, Claudine Badue, Thiago Oliveira-Santos

Auto-TLDR; Deep Learning for Brain MRI Sequences Identification Using Convolutional Neural Network
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation
Changlu Guo, Marton Szemenyei, Yugen Yi, Wenle Wang, Buer Chen, Changqi Fan

Auto-TLDR; Spatial Attention U-Net for Segmentation of Retinal Blood Vessels
Abstract Slides Poster Similar
A Multi-Task Contextual Atrous Residual Network for Brain Tumor Detection & Segmentation
Ngan Le, Kashu Yamazaki, Quach Kha Gia, Thanh-Dat Truong, Marios Savvides

Auto-TLDR; Contextual Brain Tumor Segmentation Using 3D atrous Residual Networks and Cascaded Structures
Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das, K.C. Santosh, Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
SAGE: Sequential Attribute Generator for Analyzing Glioblastomas Using Limited Dataset
Padmaja Jonnalagedda, Brent Weinberg, Jason Allen, Taejin Min, Shiv Bhanu, Bir Bhanu

Auto-TLDR; SAGE: Generative Adversarial Networks for Imaging Biomarker Detection and Prediction
Abstract Slides Poster Similar
Vesselness Filters: A Survey with Benchmarks Applied to Liver Imaging
Jonas Lamy, Odyssée Merveille, Bertrand Kerautret, Nicolas Passat, Antoine Vacavant

Auto-TLDR; Comparison of Vessel Enhancement Filters for Liver Vascular Network Segmentation
Abstract Slides Poster Similar
EM-Net: Deep Learning for Electron Microscopy Image Segmentation
Afshin Khadangi, Thomas Boudier, Vijay Rajagopal

Auto-TLDR; EM-net: Deep Convolutional Neural Network for Electron Microscopy Image Segmentation
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Multi-focus Image Fusion for Confocal Microscopy Using U-Net Regression Map
Md Maruf Hossain Shuvo, Yasmin M. Kassim, Filiz Bunyak, Olga V. Glinskii, Leike Xie, Vladislav V Glinsky, Virginia H. Huxley, Kannappan Palaniappan

Auto-TLDR; Independent Single Channel U-Net Fusion for Multi-focus Microscopy Images
Abstract Slides Poster Similar
Aerial Road Segmentation in the Presence of Topological Label Noise
Corentin Henry, Friedrich Fraundorfer, Eleonora Vig

Auto-TLDR; Improving Road Segmentation with Noise-Aware U-Nets for Fine-Grained Topology delineation
Abstract Slides Poster Similar
Deep Recurrent-Convolutional Model for AutomatedSegmentation of Craniomaxillofacial CT Scans
Francesca Murabito, Simone Palazzo, Federica Salanitri Proietto, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Segmentation of Anatomical Structures in Craniomaxillofacial CT Scans using Fully Convolutional Deep Networks
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
Weakly Supervised Geodesic Segmentation of Egyptian Mummy CT Scans
Avik Hati, Matteo Bustreo, Diego Sona, Vittorio Murino, Alessio Del Bue

Auto-TLDR; A Weakly Supervised and Efficient Interactive Segmentation of Ancient Egyptian Mummies CT Scans Using Geodesic Distance Measure and GrabCut
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
Learn to Segment Retinal Lesions and Beyond
Qijie Wei, Xirong Li, Weihong Yu, Xiao Zhang, Yongpeng Zhang, Bojie Hu, Bin Mo, Di Gong, Ning Chen, Dayong Ding, Youxin Chen

Auto-TLDR; Multi-task Lesion Segmentation and Disease Classification for Diabetic Retinopathy Grading
An Evaluation of DNN Architectures for Page Segmentation of Historical Newspapers
Manuel Burghardt, Bernhard Liebl

Auto-TLDR; Evaluation of Backbone Architectures for Optical Character Segmentation of Historical Documents
Abstract Slides Poster Similar
End-To-End Training of a Two-Stage Neural Network for Defect Detection
Jakob Božič, Domen Tabernik, Danijel Skocaj

Auto-TLDR; End-to-End Training of Segmentation-based Neural Network for Surface Defect Detection
Abstract Slides Poster Similar
Street-Map Based Validation of Semantic Segmentation in Autonomous Driving
Laura Von Rueden, Tim Wirtz, Fabian Hueger, Jan David Schneider, Nico Piatkowski, Christian Bauckhage

Auto-TLDR; Semantic Segmentation Mask Validation Using A-priori Knowledge from Street Maps
Abstract Slides Poster Similar
Fine-Tuning Convolutional Neural Networks: A Comprehensive Guide and Benchmark Analysis for Glaucoma Screening
Amed Mvoulana, Rostom Kachouri, Mohamed Akil

Auto-TLDR; Fine-tuning Convolutional Neural Networks for Glaucoma Screening
Abstract Slides Poster Similar
BiLuNet: A Multi-Path Network for Semantic Segmentation on X-Ray Images
Van Luan Tran, Huei-Yung Lin, Rachel Liu, Chun-Han Tseng, Chun-Han Tseng

Auto-TLDR; BiLuNet: Multi-path Convolutional Neural Network for Semantic Segmentation of Lumbar vertebrae, sacrum,
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
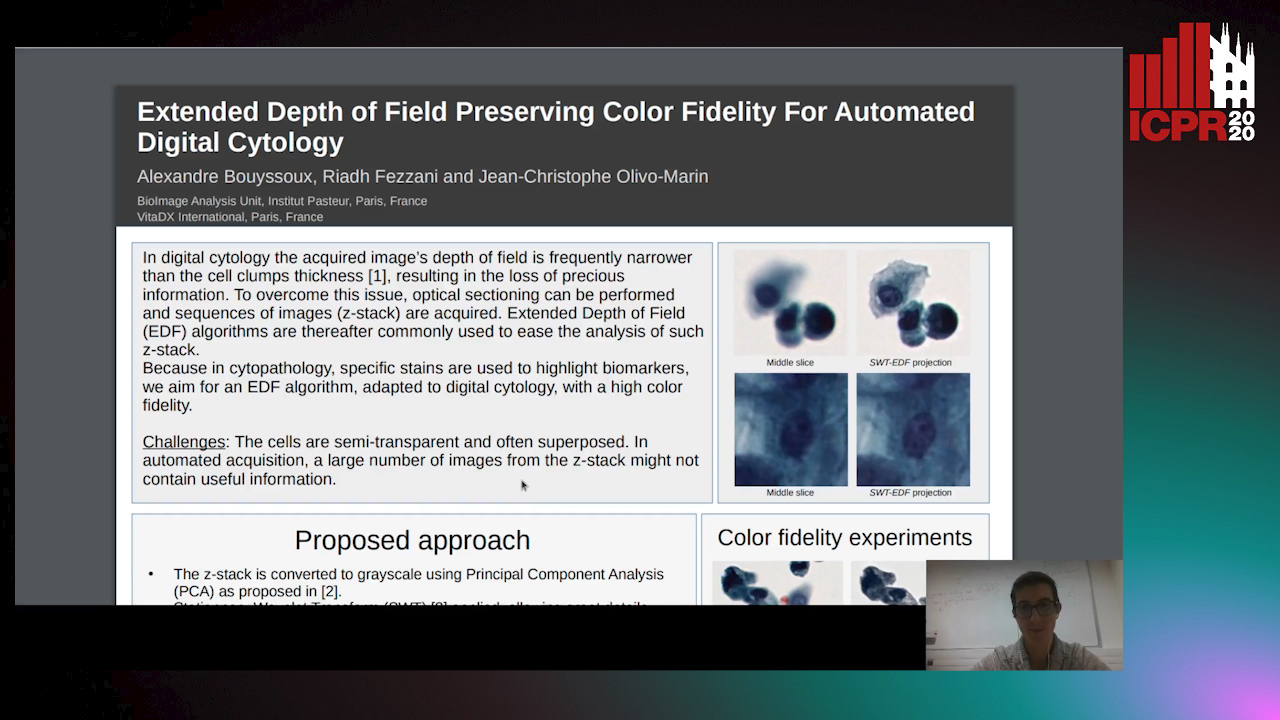
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
Robust Localization of Retinal Lesions Via Weakly-Supervised Learning

Auto-TLDR; Weakly Learning of Lesions in Fundus Images Using Multi-level Feature Maps and Classification Score
Abstract Slides Poster Similar
Motion and Region Aware Adversarial Learning for Fall Detection with Thermal Imaging
Vineet Mehta, Abhinav Dhall, Sujata Pal, Shehroz Khan

Auto-TLDR; Automatic Fall Detection with Adversarial Network using Thermal Imaging Camera
Abstract Slides Poster Similar
Dual Stream Network with Selective Optimization for Skin Disease Recognition in Consumer Grade Images
Krishnam Gupta, Jaiprasad Rampure, Monu Krishnan, Ajit Narayanan, Nikhil Narayan

Auto-TLDR; A Deep Network Architecture for Skin Disease Localisation and Classification on Consumer Grade Images
Abstract Slides Poster Similar
OCT Image Segmentation Using NeuralArchitecture Search and SRGAN
Saba Heidari, Omid Dehzangi, Nasser M. Nasarabadi, Ali Rezai

Auto-TLDR; Automatic Segmentation of Retinal Layers in Optical Coherence Tomography using Neural Architecture Search
Iterative Label Improvement: Robust Training by Confidence Based Filtering and Dataset Partitioning
Christian Haase-Schütz, Rainer Stal, Heinz Hertlein, Bernhard Sick

Auto-TLDR; Meta Training and Labelling for Unlabelled Data
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Segmenting Kidney on Multiple Phase CT Images Using ULBNet
Yanling Chi, Yuyu Xu, Gang Feng, Jiawei Mao, Sihua Wu, Guibin Xu, Weimin Huang
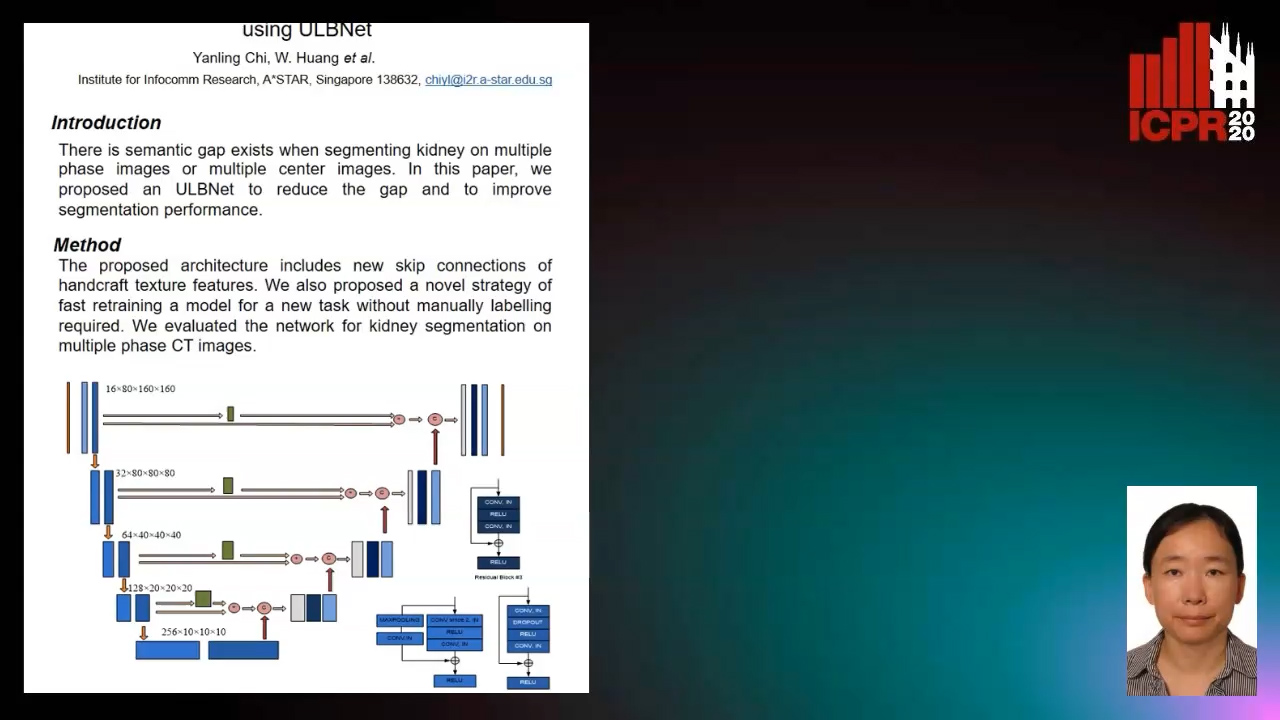
Auto-TLDR; A ULBNet network for kidney segmentation on multiple phase CT images
Detection and Correspondence Matching of Corneal Reflections for Eye Tracking Using Deep Learning
Soumil Chugh, Braiden Brousseau, Jonathan Rose, Moshe Eizenman

Auto-TLDR; A Fully Convolutional Neural Network for Corneal Reflection Detection and Matching in Extended Reality Eye Tracking Systems
Abstract Slides Poster Similar
Prediction of Obstructive Coronary Artery Disease from Myocardial Perfusion Scintigraphy using Deep Neural Networks
Ida Arvidsson, Niels Christian Overgaard, Miguel Ochoa Figueroa, Jeronimo Rose, Anette Davidsson, Kalle Åström, Anders Heyden

Auto-TLDR; A Deep Learning Algorithm for Multi-label Classification of Myocardial Perfusion Scintigraphy for Stable Ischemic Heart Disease
Abstract Slides Poster Similar
Automatically Gather Address Specific Dwelling Images Using Google Street View

Auto-TLDR; Automatic Address Specific Dwelling Image Collection Using Google Street View Data
Abstract Slides Poster Similar
Detecting Marine Species in Echograms Via Traditional, Hybrid, and Deep Learning Frameworks
Porto Marques Tunai, Alireza Rezvanifar, Melissa Cote, Alexandra Branzan Albu, Kaan Ersahin, Todd Mudge, Stephane Gauthier

Auto-TLDR; End-to-End Deep Learning for Echogram Interpretation of Marine Species in Echograms
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar