Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga,
Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Similar papers
Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das, K.C. Santosh, Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Abstract Slides Poster Similar
Unsupervised Detection of Pulmonary Opacities for Computer-Aided Diagnosis of COVID-19 on CT Images
Rui Xu, Xiao Cao, Yufeng Wang, Yen-Wei Chen, Xinchen Ye, Lin Lin, Wenchao Zhu, Chao Chen, Fangyi Xu, Yong Zhou, Hongjie Hu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A computer-aided diagnosis of COVID-19 from CT images using unsupervised pulmonary opacity detection
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
Dealing with Scarce Labelled Data: Semi-Supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-Ray Images
Saúl Calderón Ramirez, Raghvendra Giri, Shengxiang Yang, Armaghan Moemeni, Mario Umaña, David Elizondo, Jordina Torrents-Barrena, Miguel A. Molina-Cabello

Auto-TLDR; Semi-supervised Deep Learning for Covid-19 Detection using Chest X-rays
Abstract Slides Poster Similar
A Novel Computer-Aided Diagnostic System for Early Assessment of Hepatocellular Carcinoma
Ahmed Alksas, Mohamed Shehata, Gehad Saleh, Ahmed Shaffie, Ahmed Soliman, Mohammed Ghazal, Hadil Abukhalifeh, Abdel Razek Ahmed, Ayman El-Baz

Auto-TLDR; Classification of Liver Tumor Lesions from CE-MRI Using Structured Structural Features and Functional Features
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
Attack-Agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
Matthew Watson, Noura Al Moubayed

Auto-TLDR; Explainability-based Detection of Adversarial Samples on EHR and Chest X-Ray Data
Abstract Slides Poster Similar
Classify Breast Histopathology Images with Ductal Instance-Oriented Pipeline
Beibin Li, Ezgi Mercan, Sachin Mehta, Stevan Knezevich, Corey Arnold, Donald Weaver, Joann Elmore, Linda Shapiro

Auto-TLDR; DIOP: Ductal Instance-Oriented Pipeline for Diagnostic Classification
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
Fine-Tuning Convolutional Neural Networks: A Comprehensive Guide and Benchmark Analysis for Glaucoma Screening
Amed Mvoulana, Rostom Kachouri, Mohamed Akil

Auto-TLDR; Fine-tuning Convolutional Neural Networks for Glaucoma Screening
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Magnifying Spontaneous Facial Micro Expressions for Improved Recognition
Pratikshya Sharma, Sonya Coleman, Pratheepan Yogarajah, Laurence Taggart, Pradeepa Samarasinghe

Auto-TLDR; Eulerian Video Magnification for Micro Expression Recognition
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Detecting Anomalies from Video-Sequences: A Novel Descriptor
Giulia Orrù, Davide Ghiani, Maura Pintor, Gian Luca Marcialis, Fabio Roli

Auto-TLDR; Trit-based Measurement of Group Dynamics for Crowd Behavior Analysis and Anomaly Detection
Abstract Slides Poster Similar
Prediction of Obstructive Coronary Artery Disease from Myocardial Perfusion Scintigraphy using Deep Neural Networks
Ida Arvidsson, Niels Christian Overgaard, Miguel Ochoa Figueroa, Jeronimo Rose, Anette Davidsson, Kalle Åström, Anders Heyden

Auto-TLDR; A Deep Learning Algorithm for Multi-label Classification of Myocardial Perfusion Scintigraphy for Stable Ischemic Heart Disease
Abstract Slides Poster Similar
Deep Learning in the Ultrasound Evaluation of Neonatal Respiratory Status
Michela Gravina, Diego Gragnaniello, Giovanni Poggi, Luisa Verdoliva, Carlo Sansone, Iuri Corsini, Carlo Dani, Fabio Meneghin, Gianluca Lista, Salvatore Aversa, Migliaro Migliaro, Raimondi Francesco

Auto-TLDR; Lung Ultrasound Imaging with Deep Learning Networks and Training Strategies: An Analysis and Adaptation
Abstract Slides Poster Similar
BG-Net: Boundary-Guided Network for Lung Segmentation on Clinical CT Images
Rui Xu, Yi Wang, Tiantian Liu, Xinchen Ye, Lin Lin, Yen-Wei Chen, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; Boundary-Guided Network for Lung Segmentation on CT Images
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Comparison of Deep Learning and Hand Crafted Features for Mining Simulation Data
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Nan Pu, Wei Chen, Michael Lew

Auto-TLDR; Automated Data Analysis of Flow Fields in Computational Fluid Dynamics Simulations
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
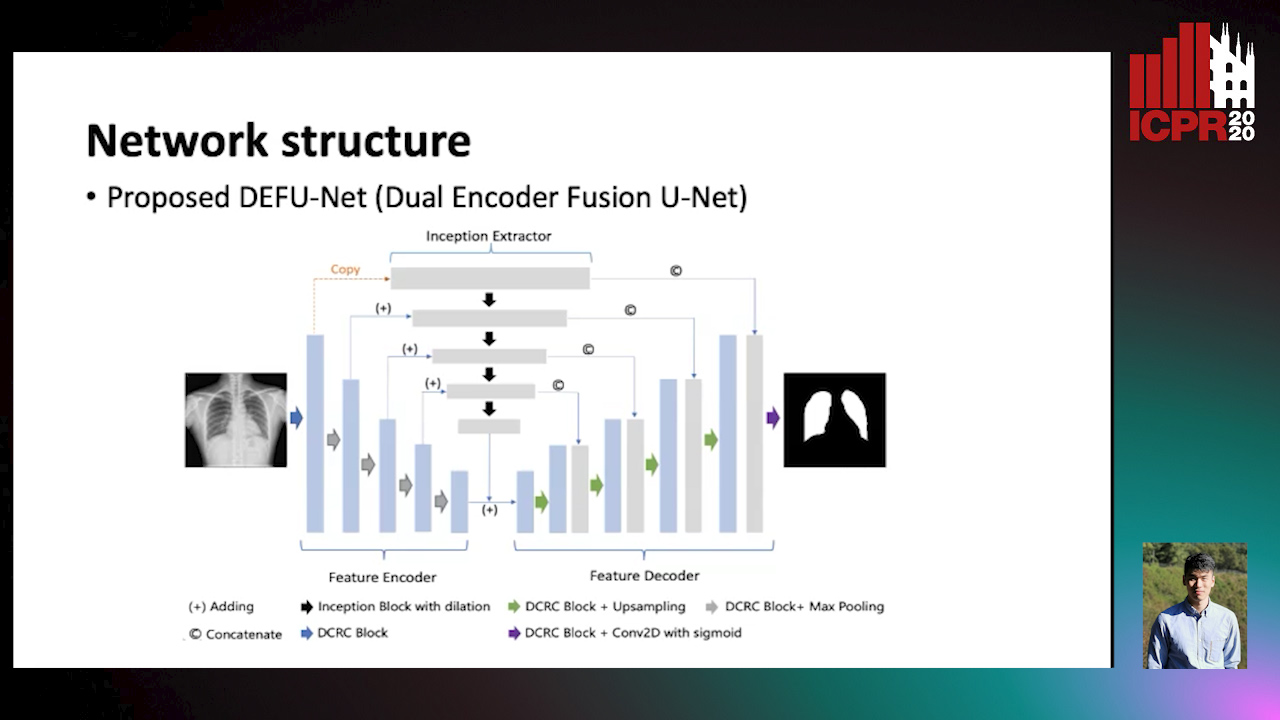
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
Epileptic Seizure Prediction: A Semi-Dilated Convolutional Neural Network Architecture
Ramy Hussein, Rabab K. Ward, Soojin Lee, Martin Mckeown

Auto-TLDR; Semi-Dilated Convolutional Network for Seizure Prediction using EEG Scalograms
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Deep Learning on Active Sonar Data Using Bayesian Optimization for Hyperparameter Tuning
Henrik Berg, Karl Thomas Hjelmervik

Auto-TLDR; Bayesian Optimization for Sonar Operations in Littoral Environments
Abstract Slides Poster Similar
AdaFilter: Adaptive Filter Design with Local Image Basis Decomposition for Optimizing Image Recognition Preprocessing
Aiga Suzuki, Keiichi Ito, Takahide Ibe, Nobuyuki Otsu

Auto-TLDR; Optimal Preprocessing Filtering for Pattern Recognition Using Higher-Order Local Auto-Correlation
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Fall Detection by Human Pose Estimation and Kinematic Theory
Vincenzo Dentamaro, Donato Impedovo, Giuseppe Pirlo

Auto-TLDR; A Decision Support System for Automatic Fall Detection on Le2i and URFD Datasets
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Mean Decision Rules Method with Smart Sampling for Fast Large-Scale Binary SVM Classification
Alexandra Makarova, Mikhail Kurbakov, Valentina Sulimova

Auto-TLDR; Improving Mean Decision Rule for Large-Scale Binary SVM Problems
Abstract Slides Poster Similar
Transfer Learning through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Abdullah Sarhan, Jon Rokne, Reda Alhajj, Andrew Crichton

Auto-TLDR; Deep Learning for Segmentation of Blood Vessels in Retinal Images
Abstract Slides Poster Similar
Fused 3-Stage Image Segmentation for Pleural Effusion Cell Clusters
Sike Ma, Meng Zhao, Hao Wang, Fan Shi, Xuguo Sun, Shengyong Chen, Hong-Ning Dai

Auto-TLDR; Coarse Segmentation of Stained and Stained Unstained Cell Clusters in pleural effusion using 3-stage segmentation method
Abstract Slides Poster Similar
Attribute-Based Quality Assessment for Demographic Estimation in Face Videos
Fabiola Becerra-Riera, Annette Morales-González, Heydi Mendez-Vazquez, Jean-Luc Dugelay

Auto-TLDR; Facial Demographic Estimation in Video Scenarios Using Quality Assessment
Multi-Scale and Attention Based ResNet for Heartbeat Classification
Haojie Zhang, Gongping Yang, Yuwen Huang, Feng Yuan, Yilong Yin

Auto-TLDR; A Multi-Scale and Attention based ResNet for ECG heartbeat classification in intra-patient and inter-patient paradigms
Abstract Slides Poster Similar
Using Machine Learning to Refer Patients with Chronic Kidney Disease to Secondary Care
Lee Au-Yeung, Xianghua Xie, Timothy Marcus Scale, James Anthony Chess

Auto-TLDR; A Machine Learning Approach for Chronic Kidney Disease Prediction using Blood Test Data
Abstract Slides Poster Similar
Deep Learning-Based Type Identification of Volumetric MRI Sequences
Jean Pablo De Mello, Thiago Paixão, Rodrigo Berriel, Mauricio Reyes, Alberto F. De Souza, Claudine Badue, Thiago Oliveira-Santos

Auto-TLDR; Deep Learning for Brain MRI Sequences Identification Using Convolutional Neural Network
Abstract Slides Poster Similar
A Novel Adaptive Minority Oversampling Technique for Improved Classification in Data Imbalanced Scenarios
Ayush Tripathi, Rupayan Chakraborty, Sunil Kumar Kopparapu

Auto-TLDR; Synthetic Minority OverSampling Technique for Imbalanced Data
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar