Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur,
Abdullah Alsalemi,
Faycal Bensaali,
Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Similar papers
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Feature Extraction by Joint Robust Discriminant Analysis and Inter-Class Sparsity

Auto-TLDR; Robust Discriminant Analysis with Feature Selection and Inter-class Sparsity (RDA_FSIS)
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
Feature Extraction and Selection Via Robust Discriminant Analysis and Class Sparsity

Auto-TLDR; Hybrid Linear Discriminant Embedding for supervised multi-class classification
Abstract Slides Poster Similar
Magnifying Spontaneous Facial Micro Expressions for Improved Recognition
Pratikshya Sharma, Sonya Coleman, Pratheepan Yogarajah, Laurence Taggart, Pradeepa Samarasinghe

Auto-TLDR; Eulerian Video Magnification for Micro Expression Recognition
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
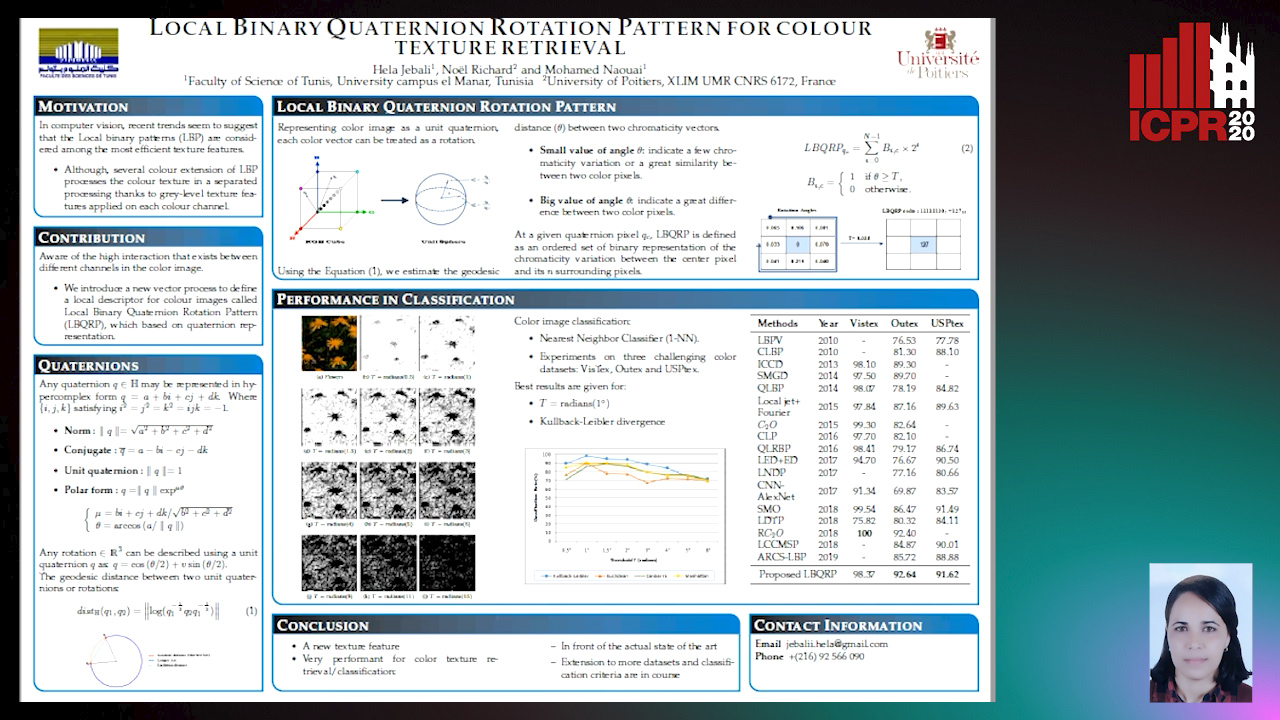
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Face Anti-Spoofing Based on Dynamic Color Texture Analysis Using Local Directional Number Pattern
Junwei Zhou, Ke Shu, Peng Liu, Jianwen Xiang, Shengwu Xiong

Auto-TLDR; LDN-TOP Representation followed by ProCRC Classification for Face Anti-Spoofing
Abstract Slides Poster Similar
Color Texture Description Based on Holistic and Hierarchical Order-Encoding Patterns
Tiecheng Song, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; Holistic and Hierarchical Order-Encoding Patterns for Color Texture Classification
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Local Grouped Invariant Order Pattern for Grayscale-Inversion and Rotation Invariant Texture Classification
Yankai Huang, Tiecheng Song, Shuang Li, Yuanjing Han

Auto-TLDR; Local grouped invariant order pattern for grayscale-inversion and rotation invariant texture classification
Abstract Slides Poster Similar
A Distinct Discriminant Canonical Correlation Analysis Network Based Deep Information Quality Representation for Image Classification
Lei Gao, Zheng Guo, Ling Guan Ling Guan

Auto-TLDR; DDCCANet: Deep Information Quality Representation for Image Classification
Abstract Slides Poster Similar
Audio-Based Near-Duplicate Video Retrieval with Audio Similarity Learning
Pavlos Avgoustinakis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Andreas L. Symeonidis, Ioannis Kompatsiaris

Auto-TLDR; AuSiL: Audio Similarity Learning for Near-duplicate Video Retrieval
Abstract Slides Poster Similar
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
First and Second-Order Sorted Local Binary Pattern Features for Grayscale-Inversion and Rotation Invariant Texture Classification
Tiecheng Song, Yuanjing Han, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; First- and Secondorder Sorted Local Binary Pattern for texture classification under inverse grayscale changes and image rotation
Abstract Slides Poster Similar
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
Force Banner for the Recognition of Spatial Relations
Robin Deléarde, Camille Kurtz, Laurent Wendling, Philippe Dejean

Auto-TLDR; Spatial Relation Recognition using Force Banners
Detecting Anomalies from Video-Sequences: A Novel Descriptor
Giulia Orrù, Davide Ghiani, Maura Pintor, Gian Luca Marcialis, Fabio Roli

Auto-TLDR; Trit-based Measurement of Group Dynamics for Crowd Behavior Analysis and Anomaly Detection
Abstract Slides Poster Similar
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Translation Resilient Opportunistic WiFi Sensing
Mohammud Junaid Bocus, Wenda Li, Jonas Paulavičius, Ryan Mcconville, Raul Santos-Rodriguez, Kevin Chetty, Robert Piechocki

Auto-TLDR; Activity Recognition using Fine-Grained WiFi Channel State Information using WiFi CSI
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Exploiting Local Indexing and Deep Feature Confidence Scores for Fast Image-To-Video Search
Savas Ozkan, Gözde Bozdağı Akar

Auto-TLDR; Fast and Robust Image-to-Video Retrieval Using Local and Global Descriptors
Abstract Slides Poster Similar
Quality-Based Representation for Unconstrained Face Recognition
Nelson Méndez-Llanes, Katy Castillo-Rosado, Heydi Mendez-Vazquez, Massimo Tistarelli

Auto-TLDR; activation map for face recognition in unconstrained environments
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana

Auto-TLDR; Entropy Partitioning Decision Tree for Connected Components Labeling
Abstract Slides Poster Similar
Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar, Mourad Oussalah, Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Abstract Slides Poster Similar
Automatic Annotation of Corpora for Emotion Recognition through Facial Expressions Analysis
Alex Mircoli, Claudia Diamantini, Domenico Potena, Emanuele Storti

Auto-TLDR; Automatic annotation of video subtitles on the basis of facial expressions using machine learning algorithms
Abstract Slides Poster Similar
Epileptic Seizure Prediction: A Semi-Dilated Convolutional Neural Network Architecture
Ramy Hussein, Rabab K. Ward, Soojin Lee, Martin Mckeown

Auto-TLDR; Semi-Dilated Convolutional Network for Seizure Prediction using EEG Scalograms
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
A Novel Adaptive Minority Oversampling Technique for Improved Classification in Data Imbalanced Scenarios
Ayush Tripathi, Rupayan Chakraborty, Sunil Kumar Kopparapu

Auto-TLDR; Synthetic Minority OverSampling Technique for Imbalanced Data
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
Dynamic Resource-Aware Corner Detection for Bio-Inspired Vision Sensors
Sherif Abdelmonem Sayed Mohamed, Jawad Yasin, Mohammad-Hashem Haghbayan, Antonio Miele, Jukka Veikko Heikkonen, Hannu Tenhunen, Juha Plosila

Auto-TLDR; Three Layer Filtering-Harris Algorithm for Event-based Cameras in Real-Time
Conditional-UNet: A Condition-Aware Deep Model for Coherent Human Activity Recognition from Wearables
Liming Zhang, Wenbin Zhang, Nathalie Japkowicz

Auto-TLDR; Coherent Human Activity Recognition from Multi-Channel Time Series Data
Abstract Slides Poster Similar
Detection of Makeup Presentation Attacks Based on Deep Face Representations
Christian Rathgeb, Pawel Drozdowski, Christoph Busch

Auto-TLDR; An Attack Detection Scheme for Face Recognition Using Makeup Presentation Attacks
Abstract Slides Poster Similar
Algorithm Recommendation for Data Streams
Jáder Martins Camboim De Sá, Andre Luis Debiaso Rossi, Gustavo Enrique De Almeida Prado Alves Batista, Luís Paulo Faina Garcia

Auto-TLDR; Meta-Learning for Algorithm Selection in Time-Changing Data Streams
Abstract Slides Poster Similar
Memetic Evolution of Training Sets with Adaptive Radial Basis Kernels for Support Vector Machines
Jakub Nalepa, Wojciech Dudzik, Michal Kawulok

Auto-TLDR; Memetic Algorithm for Evolving Support Vector Machines with Adaptive Kernels
Abstract Slides Poster Similar
Supervised Feature Embedding for Classification by Learning Rank-Based Neighborhoods
Ghazaal Sheikhi, Hakan Altincay

Auto-TLDR; Supervised Feature Embedding with Representation Learning of Rank-based Neighborhoods
A Novel Computer-Aided Diagnostic System for Early Assessment of Hepatocellular Carcinoma
Ahmed Alksas, Mohamed Shehata, Gehad Saleh, Ahmed Shaffie, Ahmed Soliman, Mohammed Ghazal, Hadil Abukhalifeh, Abdel Razek Ahmed, Ayman El-Baz

Auto-TLDR; Classification of Liver Tumor Lesions from CE-MRI Using Structured Structural Features and Functional Features
Abstract Slides Poster Similar
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
Signal Generation Using 1d Deep Convolutional Generative Adversarial Networks for Fault Diagnosis of Electrical Machines
Russell Sabir, Daniele Rosato, Sven Hartmann, Clemens Gühmann

Auto-TLDR; Large Dataset Generation from Faulty AC Machines using Deep Convolutional GAN
Abstract Slides Poster Similar
Detection of Calls from Smart Speaker Devices
Vinay Maddali, David Looney, Kailash Patil

Auto-TLDR; Distinguishing Between Smart Speaker and Cell Devices Using Only the Audio Using a Feature Set
Abstract Slides Poster Similar
Digit Recognition Applied to Reconstructed Audio Signals Using Deep Learning
Anastasia-Sotiria Toufa, Constantine Kotropoulos

Auto-TLDR; Compressed Sensing for Digit Recognition in Audio Reconstruction
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
BAT Optimized CNN Model Identifies Water Stress in Chickpea Plant Shoot Images
Shiva Azimi, Taranjit Kaur, Tapan Gandhi

Auto-TLDR; BAT Optimized ResNet-18 for Stress Classification of chickpea shoot images under water deficiency
Abstract Slides Poster Similar
A Systematic Investigation on End-To-End Deep Recognition of Grocery Products in the Wild
Marco Leo, Pierluigi Carcagni, Cosimo Distante

Auto-TLDR; Automatic Recognition of Products on grocery shelf images using Convolutional Neural Networks
Abstract Slides Poster Similar