Epileptic Seizure Prediction: A Semi-Dilated Convolutional Neural Network Architecture
Ramy Hussein,
Rabab K. Ward,
Soojin Lee,
Martin Mckeown

Auto-TLDR; Semi-Dilated Convolutional Network for Seizure Prediction using EEG Scalograms
Similar papers
Multi-Scale and Attention Based ResNet for Heartbeat Classification
Haojie Zhang, Gongping Yang, Yuwen Huang, Feng Yuan, Yilong Yin

Auto-TLDR; A Multi-Scale and Attention based ResNet for ECG heartbeat classification in intra-patient and inter-patient paradigms
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Ballroom Dance Recognition from Audio Recordings
Tomas Pavlin, Jan Cech, Jiri Matas

Auto-TLDR; A CNN-based approach to classify ballroom dances given audio recordings
Abstract Slides Poster Similar
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
Hybrid Network for End-To-End Text-Independent Speaker Identification
Wajdi Ghezaiel, Luc Brun, Olivier Lezoray

Auto-TLDR; Text-Independent Speaker Identification with Scattering Wavelet Network and Convolutional Neural Networks
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar
Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das, K.C. Santosh, Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Abstract Slides Poster Similar
Classification of Spatially Enriched Pixel Time Series with Convolutional Neural Networks
Mohamed Chelali, Camille Kurtz, Anne Puissant, Nicole Vincent

Auto-TLDR; Spatio-Temporal Features Extraction from Satellite Image Time Series Using Random Walk
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Using Machine Learning to Refer Patients with Chronic Kidney Disease to Secondary Care
Lee Au-Yeung, Xianghua Xie, Timothy Marcus Scale, James Anthony Chess

Auto-TLDR; A Machine Learning Approach for Chronic Kidney Disease Prediction using Blood Test Data
Abstract Slides Poster Similar
Graph Convolutional Neural Networks for Power Line Outage Identification

Auto-TLDR; Graph Convolutional Networks for Power Line Outage Identification
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Malware Detection by Exploiting Deep Learning over Binary Programs
Panpan Qi, Zhaoqi Zhang, Wei Wang, Chang Yao

Auto-TLDR; End-to-End Malware Detection without Feature Engineering
Abstract Slides Poster Similar
The Application of Capsule Neural Network Based CNN for Speech Emotion Recognition

Auto-TLDR; CapCNN: A Capsule Neural Network for Speech Emotion Recognition
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
Vertex Feature Encoding and Hierarchical Temporal Modeling in a Spatio-Temporal Graph Convolutional Network for Action Recognition
Konstantinos Papadopoulos, Enjie Ghorbel, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Spatio-Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
Abstract Slides Poster Similar
Prediction of Obstructive Coronary Artery Disease from Myocardial Perfusion Scintigraphy using Deep Neural Networks
Ida Arvidsson, Niels Christian Overgaard, Miguel Ochoa Figueroa, Jeronimo Rose, Anette Davidsson, Kalle Åström, Anders Heyden

Auto-TLDR; A Deep Learning Algorithm for Multi-label Classification of Myocardial Perfusion Scintigraphy for Stable Ischemic Heart Disease
Abstract Slides Poster Similar
ESResNet: Environmental Sound Classification Based on Visual Domain Models
Andrey Guzhov, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Environmental Sound Classification with Short-Time Fourier Transform Spectrograms
Abstract Slides Poster Similar
PC-Net: A Deep Network for 3D Point Clouds Analysis
Zhuo Chen, Tao Guan, Yawei Luo, Yuesong Wang

Auto-TLDR; PC-Net: A Hierarchical Neural Network for 3D Point Clouds Analysis
Abstract Slides Poster Similar
Spatial-Related and Scale-Aware Network for Crowd Counting
Lei Li, Yuan Dong, Hongliang Bai

Auto-TLDR; Spatial Attention for Crowd Counting
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
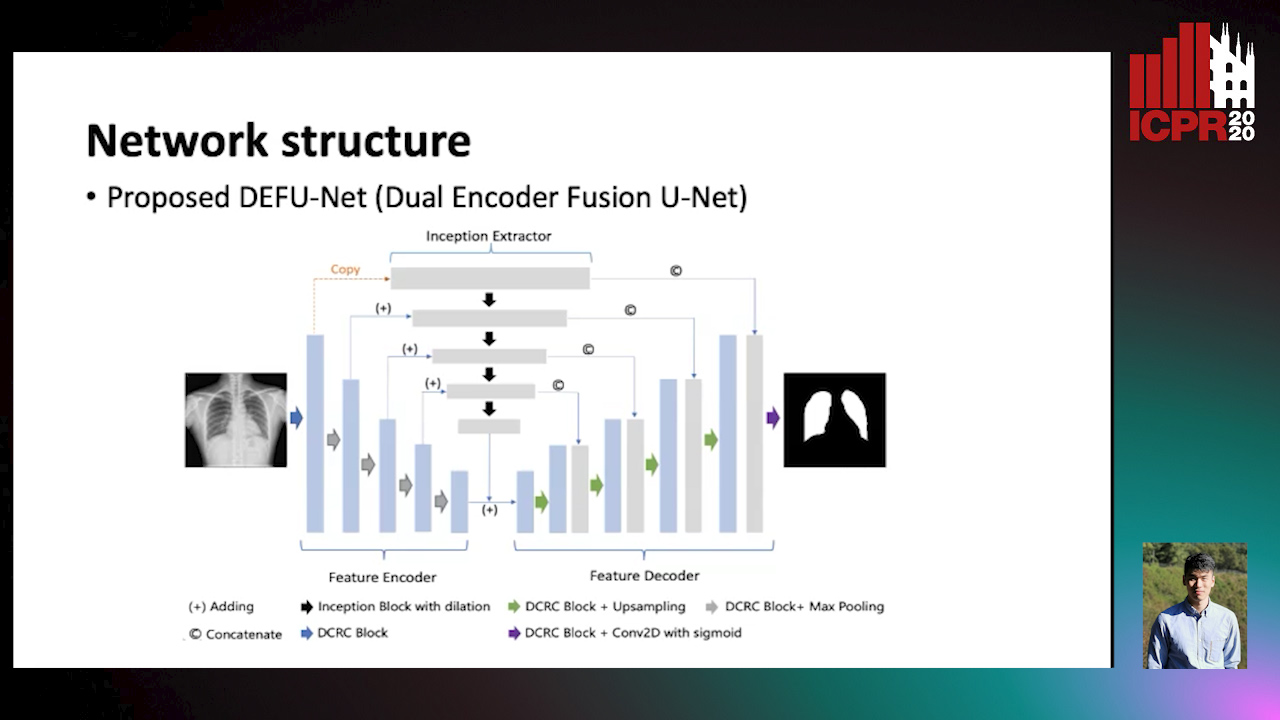
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
DenseRecognition of Spoken Languages
Jaybrata Chakraborty, Bappaditya Chakraborty, Ujjwal Bhattacharya

Auto-TLDR; DenseNet: A Dense Convolutional Network Architecture for Speech Recognition in Indian Languages
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Which are the factors affecting the performance of audio surveillance systems?
Antonio Greco, Antonio Roberto, Alessia Saggese, Mario Vento

Auto-TLDR; Sound Event Recognition Using Convolutional Neural Networks and Visual Representations on MIVIA Audio Events
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Mehak Gupta, Vishal Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh

Auto-TLDR; MVNet: A Deep Learning-based PAD Network for Iris Recognition against Presentation Attacks
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
PCANet: Pyramid Context-Aware Network for Retinal Vessel Segmentation
Yi Zhang, Yixuan Chen, Kai Zhang

Auto-TLDR; PCANet: Adaptive Context-Aware Network for Automated Retinal Vessel Segmentation
Abstract Slides Poster Similar
GazeMAE: General Representations of Eye Movements Using a Micro-Macro Autoencoder
Louise Gillian C. Bautista, Prospero Naval

Auto-TLDR; Fast and Slow Eye Movement Representations for Sentiment-agnostic Eye Tracking
Abstract Slides Poster Similar
Dealing with Scarce Labelled Data: Semi-Supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-Ray Images
Saúl Calderón Ramirez, Raghvendra Giri, Shengxiang Yang, Armaghan Moemeni, Mario Umaña, David Elizondo, Jordina Torrents-Barrena, Miguel A. Molina-Cabello

Auto-TLDR; Semi-supervised Deep Learning for Covid-19 Detection using Chest X-rays
Abstract Slides Poster Similar
Tensor Factorization of Brain Structural Graph for Unsupervised Classification in Multiple Sclerosis
Berardino Barile, Marzullo Aldo, Claudio Stamile, Françoise Durand-Dubief, Dominique Sappey-Marinier

Auto-TLDR; A Fully Automated Tensor-based Algorithm for Multiple Sclerosis Classification based on Structural Connectivity Graph of the White Matter Network
Abstract Slides Poster Similar
3D Medical Multi-Modal Segmentation Network Guided by Multi-Source Correlation Constraint
Tongxue Zhou, Stéphane Canu, Pierre Vera, Su Ruan

Auto-TLDR; Multi-modality Segmentation with Correlation Constrained Network
Abstract Slides Poster Similar
Fast and Accurate Real-Time Semantic Segmentation with Dilated Asymmetric Convolutions
Leonel Rosas-Arias, Gibran Benitez-Garcia, Jose Portillo-Portillo, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; FASSD-Net: Dilated Asymmetric Pyramidal Fusion for Real-Time Semantic Segmentation
Abstract Slides Poster Similar