Multi-Scale and Attention Based ResNet for Heartbeat Classification
Haojie Zhang,
Gongping Yang,
Yuwen Huang,
Feng Yuan,
Yilong Yin

Auto-TLDR; A Multi-Scale and Attention based ResNet for ECG heartbeat classification in intra-patient and inter-patient paradigms
Similar papers
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation
Changlu Guo, Marton Szemenyei, Yugen Yi, Wenle Wang, Buer Chen, Changqi Fan

Auto-TLDR; Spatial Attention U-Net for Segmentation of Retinal Blood Vessels
Abstract Slides Poster Similar
Epileptic Seizure Prediction: A Semi-Dilated Convolutional Neural Network Architecture
Ramy Hussein, Rabab K. Ward, Soojin Lee, Martin Mckeown

Auto-TLDR; Semi-Dilated Convolutional Network for Seizure Prediction using EEG Scalograms
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Skin Lesion Classification Using Weakly-Supervised Fine-Grained Method
Xi Xue, Sei-Ichiro Kamata, Daming Luo

Auto-TLDR; Different Region proposal module for skin lesion classification
Abstract Slides Poster Similar
CardioGAN: An Attention-Based Generative Adversarial Network for Generation of Electrocardiograms
Subhrajyoti Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; CardioGAN: Generative Adversarial Network for Synthetic Electrocardiogram Signals
Abstract Slides Poster Similar
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das, K.C. Santosh, Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
A Low-Complexity R-Peak Detection Algorithm with Adaptive Thresholding for Wearable Devices
Tiago Rodrigues, Hugo Plácido Da Silva, Ana Luisa Nobre Fred, Sirisack Samoutphonh

Auto-TLDR; Real-Time and Low-Complexity R-peak Detection for Single Lead ECG Signals
Abstract Slides Poster Similar
Selective Kernel and Motion-Emphasized Loss Based Attention-Guided Network for HDR Imaging of Dynamic Scenes
Yipeng Deng, Qin Liu, Takeshi Ikenaga

Auto-TLDR; SK-AHDRNet: A Deep Network with attention module and motion-emphasized loss function to produce ghost-free HDR images
Abstract Slides Poster Similar
BCAU-Net: A Novel Architecture with Binary Channel Attention Module for MRI Brain Segmentation
Yongpei Zhu, Zicong Zhou, Guojun Liao, Kehong Yuan

Auto-TLDR; BCAU-Net: Binary Channel Attention U-Net for MRI brain segmentation
Abstract Slides Poster Similar
Accurate Cell Segmentation in Digital Pathology Images Via Attention Enforced Networks
Zeyi Yao, Kaiqi Li, Guanhong Zhang, Yiwen Luo, Xiaoguang Zhou, Muyi Sun

Auto-TLDR; AENet: Attention Enforced Network for Automatic Cell Segmentation
Abstract Slides Poster Similar
PCANet: Pyramid Context-Aware Network for Retinal Vessel Segmentation
Yi Zhang, Yixuan Chen, Kai Zhang

Auto-TLDR; PCANet: Adaptive Context-Aware Network for Automated Retinal Vessel Segmentation
Abstract Slides Poster Similar
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
An Improved Bilinear Pooling Method for Image-Based Action Recognition

Auto-TLDR; An improved bilinear pooling method for image-based action recognition
Abstract Slides Poster Similar
3D Medical Multi-Modal Segmentation Network Guided by Multi-Source Correlation Constraint
Tongxue Zhou, Stéphane Canu, Pierre Vera, Su Ruan

Auto-TLDR; Multi-modality Segmentation with Correlation Constrained Network
Abstract Slides Poster Similar
CSpA-DN: Channel and Spatial Attention Dense Network for Fusing PET and MRI Images
Bicao Li, Zhoufeng Liu, Shan Gao, Jenq-Neng Hwang, Jun Sun, Zongmin Wang

Auto-TLDR; CSpA-DN: Unsupervised Fusion of PET and MR Images with Channel and Spatial Attention
Abstract Slides Poster Similar
Do Not Treat Boundaries and Regions Differently: An Example on Heart Left Atrial Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; Attention Full Convolutional Network for Atrial Segmentation using ResNet-101 Architecture
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
CT-UNet: An Improved Neural Network Based on U-Net for Building Segmentation in Remote Sensing Images
Huanran Ye, Sheng Liu, Kun Jin, Haohao Cheng

Auto-TLDR; Context-Transfer-UNet: A UNet-based Network for Building Segmentation in Remote Sensing Images
Abstract Slides Poster Similar
Using Machine Learning to Refer Patients with Chronic Kidney Disease to Secondary Care
Lee Au-Yeung, Xianghua Xie, Timothy Marcus Scale, James Anthony Chess

Auto-TLDR; A Machine Learning Approach for Chronic Kidney Disease Prediction using Blood Test Data
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Attention Based Multi-Instance Thyroid Cytopathological Diagnosis with Multi-Scale Feature Fusion
Shuhao Qiu, Yao Guo, Chuang Zhu, Wenli Zhou, Huang Chen

Auto-TLDR; A weakly supervised multi-instance learning framework based on attention mechanism with multi-scale feature fusion for thyroid cytopathological diagnosis
Abstract Slides Poster Similar
Attack-Agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
Matthew Watson, Noura Al Moubayed

Auto-TLDR; Explainability-based Detection of Adversarial Samples on EHR and Chest X-Ray Data
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Arbitrary Style Transfer with Parallel Self-Attention
Tiange Zhang, Ying Gao, Feng Gao, Lin Qi, Junyu Dong

Auto-TLDR; Self-Attention-Based Arbitrary Style Transfer Using Adaptive Instance Normalization
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
PC-Net: A Deep Network for 3D Point Clouds Analysis
Zhuo Chen, Tao Guan, Yawei Luo, Yuesong Wang

Auto-TLDR; PC-Net: A Hierarchical Neural Network for 3D Point Clouds Analysis
Abstract Slides Poster Similar
MANet: Multimodal Attention Network Based Point-View Fusion for 3D Shape Recognition
Yaxin Zhao, Jichao Jiao, Ning Li

Auto-TLDR; Fusion Network for 3D Shape Recognition based on Multimodal Attention Mechanism
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
Facial Expression Recognition Using Residual Masking Network
Luan Pham, Vu Huynh, Tuan Anh Tran

Auto-TLDR; Deep Residual Masking for Automatic Facial Expression Recognition
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Spatial-Related and Scale-Aware Network for Crowd Counting
Lei Li, Yuan Dong, Hongliang Bai

Auto-TLDR; Spatial Attention for Crowd Counting
Abstract Slides Poster Similar
TSMSAN: A Three-Stream Multi-Scale Attentive Network for Video Saliency Detection
Jingwen Yang, Guanwen Zhang, Wei Zhou

Auto-TLDR; Three-stream Multi-scale attentive network for video saliency detection in dynamic scenes
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
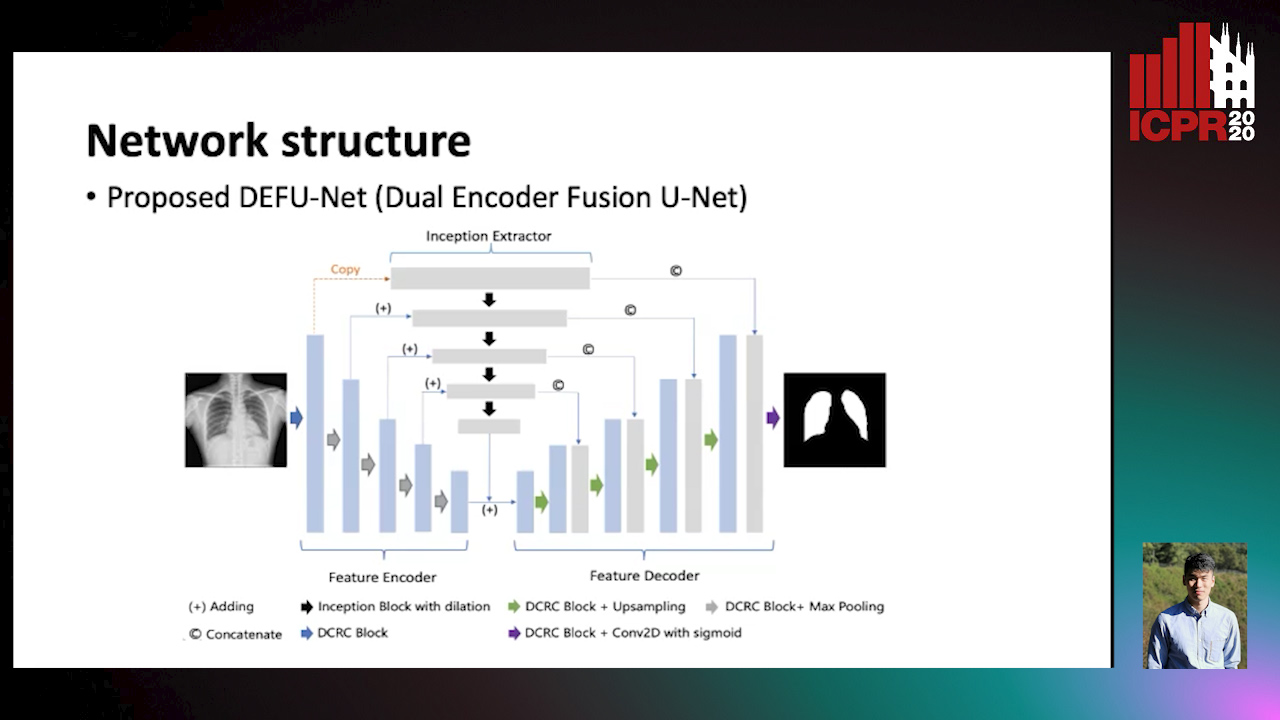
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar