A Low-Complexity R-Peak Detection Algorithm with Adaptive Thresholding for Wearable Devices
Tiago Rodrigues,
Hugo Plácido Da Silva,
Ana Luisa Nobre Fred,
Sirisack Samoutphonh

Auto-TLDR; Real-Time and Low-Complexity R-peak Detection for Single Lead ECG Signals
Similar papers
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
Multi-Scale and Attention Based ResNet for Heartbeat Classification
Haojie Zhang, Gongping Yang, Yuwen Huang, Feng Yuan, Yilong Yin

Auto-TLDR; A Multi-Scale and Attention based ResNet for ECG heartbeat classification in intra-patient and inter-patient paradigms
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
CardioGAN: An Attention-Based Generative Adversarial Network for Generation of Electrocardiograms
Subhrajyoti Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; CardioGAN: Generative Adversarial Network for Synthetic Electrocardiogram Signals
Abstract Slides Poster Similar
Feature Engineering and Stacked Echo State Networks for Musical Onset Detection
Peter Steiner, Azarakhsh Jalalvand, Simon Stone, Peter Birkholz

Auto-TLDR; Echo State Networks for Onset Detection in Music Analysis
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
From Human Pose to On-Body Devices for Human-Activity Recognition
Fernando Moya Rueda, Gernot Fink
Auto-TLDR; Transfer Learning from Human Pose Estimation for Human Activity Recognition using Inertial Measurements from On-Body Devices
Abstract Slides Poster Similar
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Hybrid Network for End-To-End Text-Independent Speaker Identification
Wajdi Ghezaiel, Luc Brun, Olivier Lezoray

Auto-TLDR; Text-Independent Speaker Identification with Scattering Wavelet Network and Convolutional Neural Networks
Abstract Slides Poster Similar
Which are the factors affecting the performance of audio surveillance systems?
Antonio Greco, Antonio Roberto, Alessia Saggese, Mario Vento

Auto-TLDR; Sound Event Recognition Using Convolutional Neural Networks and Visual Representations on MIVIA Audio Events
Epileptic Seizure Prediction: A Semi-Dilated Convolutional Neural Network Architecture
Ramy Hussein, Rabab K. Ward, Soojin Lee, Martin Mckeown

Auto-TLDR; Semi-Dilated Convolutional Network for Seizure Prediction using EEG Scalograms
RONELD: Robust Neural Network Output Enhancement for Active Lane Detection
Zhe Ming Chng, Joseph Mun Hung Lew, Jimmy Addison Lee

Auto-TLDR; Real-Time Robust Neural Network Output Enhancement for Active Lane Detection
Abstract Slides Poster Similar
Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das, K.C. Santosh, Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Abstract Slides Poster Similar
Digit Recognition Applied to Reconstructed Audio Signals Using Deep Learning
Anastasia-Sotiria Toufa, Constantine Kotropoulos

Auto-TLDR; Compressed Sensing for Digit Recognition in Audio Reconstruction
Video Analytics Gait Trend Measurement for Fall Prevention and Health Monitoring
Lawrence O'Gorman, Xinyi Liu, Md Imran Sarker, Mariofanna Milanova

Auto-TLDR; Towards Health Monitoring of Gait with Deep Learning
Abstract Slides Poster Similar
Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors
Fredrik Svanström, Cristofer Englund, Fernando Alonso-Fernandez

Auto-TLDR; Automatic multi-sensor drone detection using sensor fusion
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Fully Convolutional Neural Networks for Raw Eye Tracking Data Segmentation, Generation, and Reconstruction
Wolfgang Fuhl, Yao Rong, Enkelejda Kasneci

Auto-TLDR; Semantic Segmentation of Eye Tracking Data with Fully Convolutional Neural Networks
Abstract Slides Poster Similar
TGCRBNW: A Dataset for Runner Bib Number Detection (and Recognition) in the Wild
Pablo Hernández-Carrascosa, Adrian Penate-Sanchez, Javier Lorenzo, David Freire Obregón, Modesto Castrillon

Auto-TLDR; Racing Bib Number Detection and Recognition in the Wild Using Faster R-CNN
Abstract Slides Poster Similar
XGBoost to Interpret the Opioid Patients’ StateBased on Cognitive and Physiological Measures
Arash Shokouhmand, Omid Dehzangi, Jad Ramadan, Victor Finomore, Nasser M. Nasarabadi, Ali Rezai
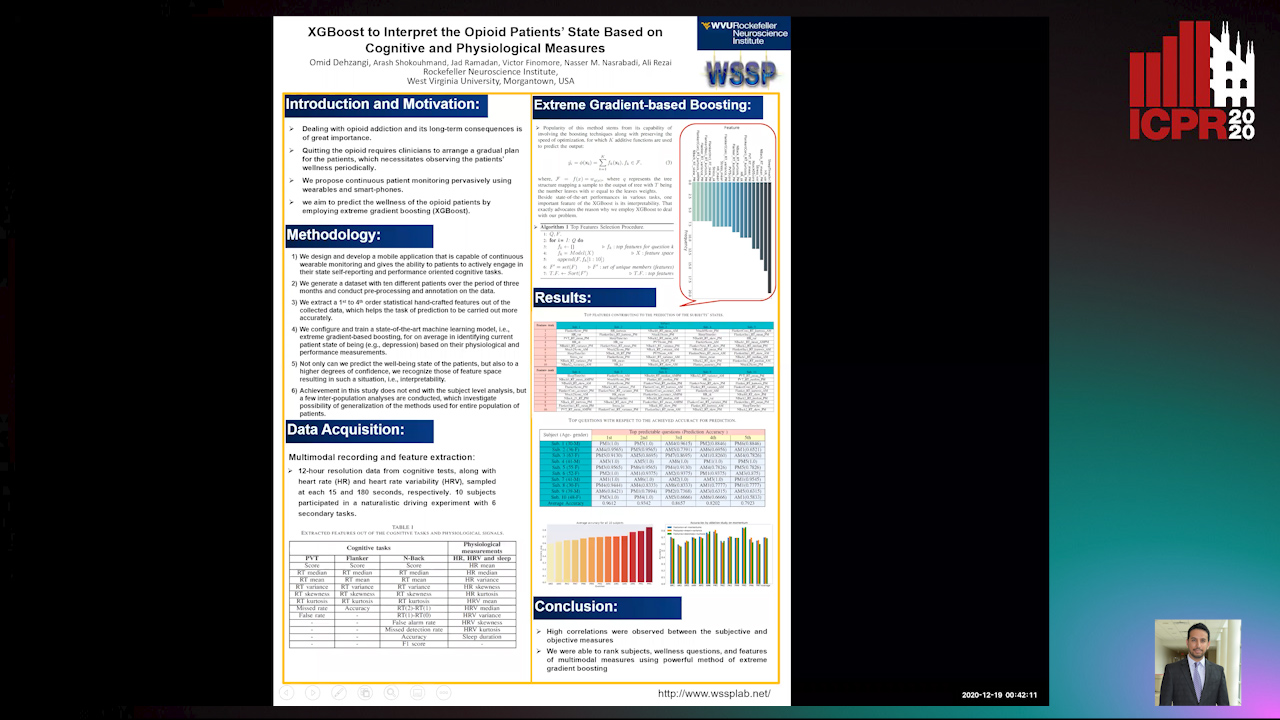
Auto-TLDR; Predicting the Wellness of Opioid Addictions Using Multi-modal Sensor Data
CARRADA Dataset: Camera and Automotive Radar with Range-Angle-Doppler Annotations
Arthur Ouaknine, Alasdair Newson, Julien Rebut, Florence Tupin, Patrick Pérez

Auto-TLDR; CARRADA: A dataset of synchronized camera and radar recordings with range-angle-Doppler annotations for autonomous driving
Abstract Slides Poster Similar
IPT: A Dataset for Identity Preserved Tracking in Closed Domains
Thomas Heitzinger, Martin Kampel

Auto-TLDR; Identity Preserved Tracking Using Depth Data for Privacy and Privacy
Abstract Slides Poster Similar
Dynamic Resource-Aware Corner Detection for Bio-Inspired Vision Sensors
Sherif Abdelmonem Sayed Mohamed, Jawad Yasin, Mohammad-Hashem Haghbayan, Antonio Miele, Jukka Veikko Heikkonen, Hannu Tenhunen, Juha Plosila

Auto-TLDR; Three Layer Filtering-Harris Algorithm for Event-based Cameras in Real-Time
Radar Image Reconstruction from Raw ADC Data Using Parametric Variational Autoencoder with Domain Adaptation
Michael Stephan, Thomas Stadelmayer, Avik Santra, Georg Fischer, Robert Weigel, Fabian Lurz

Auto-TLDR; Parametric Variational Autoencoder-based Human Target Detection and Localization for Frequency Modulated Continuous Wave Radar
Abstract Slides Poster Similar
DenseRecognition of Spoken Languages
Jaybrata Chakraborty, Bappaditya Chakraborty, Ujjwal Bhattacharya

Auto-TLDR; DenseNet: A Dense Convolutional Network Architecture for Speech Recognition in Indian Languages
Abstract Slides Poster Similar
Vesselness Filters: A Survey with Benchmarks Applied to Liver Imaging
Jonas Lamy, Odyssée Merveille, Bertrand Kerautret, Nicolas Passat, Antoine Vacavant

Auto-TLDR; Comparison of Vessel Enhancement Filters for Liver Vascular Network Segmentation
Abstract Slides Poster Similar
Translation Resilient Opportunistic WiFi Sensing
Mohammud Junaid Bocus, Wenda Li, Jonas Paulavičius, Ryan Mcconville, Raul Santos-Rodriguez, Kevin Chetty, Robert Piechocki

Auto-TLDR; Activity Recognition using Fine-Grained WiFi Channel State Information using WiFi CSI
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Handwritten Signature and Text Based User Verification Using Smartwatch
Raghavendra Ramachandra, Sushma Venkatesh, Raja Kiran, Christoph Busch
Auto-TLDR; A novel technique for user verification using a smartwatch based on writing pattern or signing pattern
Abstract Slides Poster Similar
Fingerprints, Forever Young?
Roman Kessler, Olaf Henniger, Christoph Busch

Auto-TLDR; Mated Similarity Scores for Fingerprint Recognition: A Hierarchical Linear Model
Abstract Slides Poster Similar
Ballroom Dance Recognition from Audio Recordings
Tomas Pavlin, Jan Cech, Jiri Matas

Auto-TLDR; A CNN-based approach to classify ballroom dances given audio recordings
Abstract Slides Poster Similar
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Deep Learning on Active Sonar Data Using Bayesian Optimization for Hyperparameter Tuning
Henrik Berg, Karl Thomas Hjelmervik

Auto-TLDR; Bayesian Optimization for Sonar Operations in Littoral Environments
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
Feasibility Study of Using MyoBand for Learning Electronic Keyboard

Auto-TLDR; Autonomous Finger-Based Music Instrument Learning using Electromyography Using MyoBand and Machine Learning
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Graph-Based Image Decoding for Multiplexed in Situ RNA Detection
Gabriele Partel, Carolina Wahlby
Auto-TLDR; A Graph-based Decoding Approach for Multiplexed In situ RNA Detection
Detecting Anomalies from Video-Sequences: A Novel Descriptor
Giulia Orrù, Davide Ghiani, Maura Pintor, Gian Luca Marcialis, Fabio Roli

Auto-TLDR; Trit-based Measurement of Group Dynamics for Crowd Behavior Analysis and Anomaly Detection
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
End-To-End Training of a Two-Stage Neural Network for Defect Detection
Jakob Božič, Domen Tabernik, Danijel Skocaj

Auto-TLDR; End-to-End Training of Segmentation-based Neural Network for Surface Defect Detection
Abstract Slides Poster Similar
Street-Map Based Validation of Semantic Segmentation in Autonomous Driving
Laura Von Rueden, Tim Wirtz, Fabian Hueger, Jan David Schneider, Nico Piatkowski, Christian Bauckhage

Auto-TLDR; Semantic Segmentation Mask Validation Using A-priori Knowledge from Street Maps
Abstract Slides Poster Similar
Automatic Annotation of Corpora for Emotion Recognition through Facial Expressions Analysis
Alex Mircoli, Claudia Diamantini, Domenico Potena, Emanuele Storti

Auto-TLDR; Automatic annotation of video subtitles on the basis of facial expressions using machine learning algorithms
Abstract Slides Poster Similar