Olivier Lezoray
Papers from this author
Graph Signal Active Contours

Auto-TLDR; Adaptation of Active Contour Without Edges for Graph Signal Processing
Hybrid Network for End-To-End Text-Independent Speaker Identification
Wajdi Ghezaiel, Luc Brun, Olivier Lezoray

Auto-TLDR; Text-Independent Speaker Identification with Scattering Wavelet Network and Convolutional Neural Networks
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
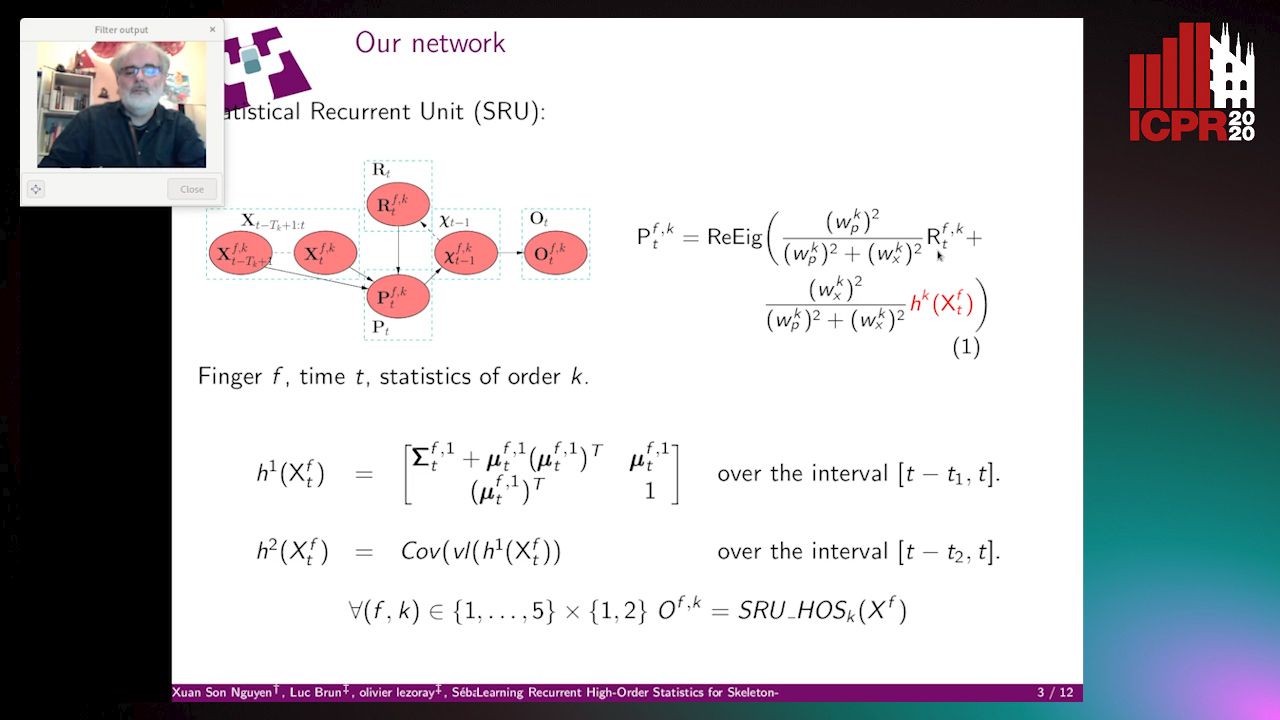
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition