Graph Signal Active Contours

Auto-TLDR; Adaptation of Active Contour Without Edges for Graph Signal Processing
Similar papers
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Facetwise Mesh Refinement for Multi-View Stereo
Andrea Romanoni, Matteo Matteucci

Auto-TLDR; Facetwise Refinement of Multi-View Stereo using Delaunay Triangulations
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
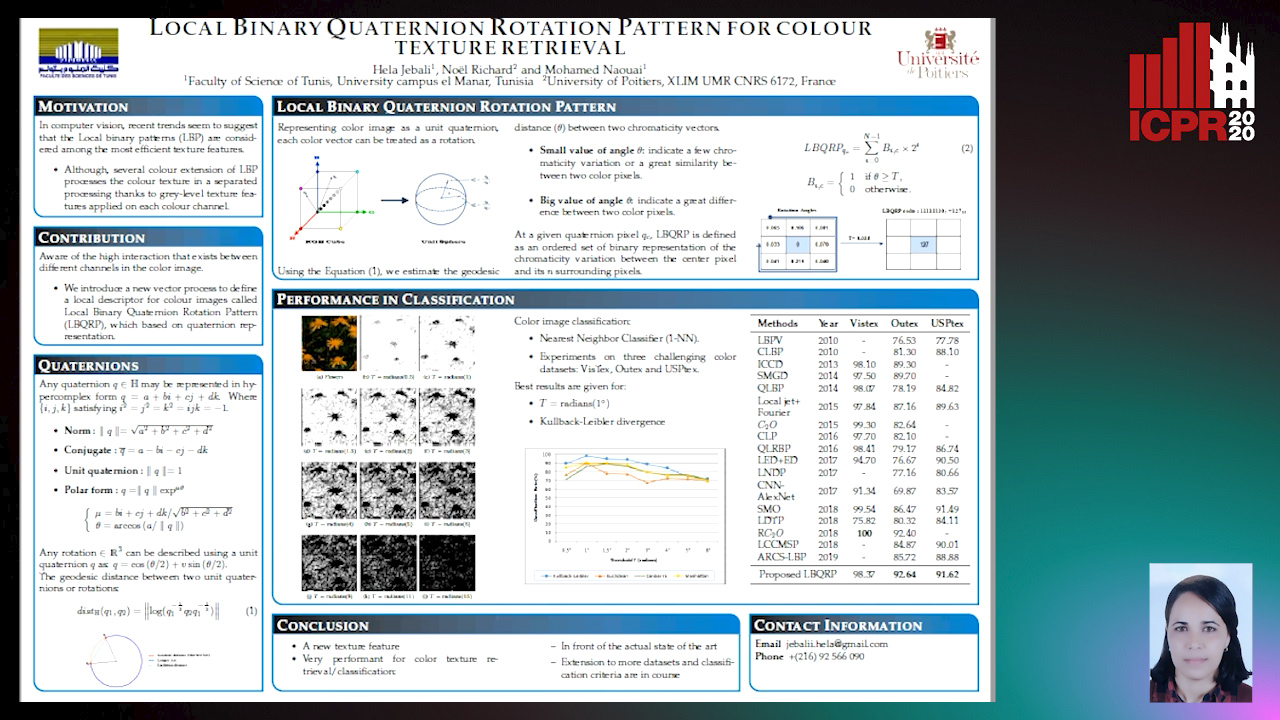
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
On Morphological Hierarchies for Image Sequences
Caglayan Tuna, Alain Giros, François Merciol, Sébastien Lefèvre

Auto-TLDR; Comparison of Hierarchies for Image Sequences
Abstract Slides Poster Similar
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
Classification and Feature Selection Using a Primal-Dual Method and Projections on Structured Constraints
Michel Barlaud, Antonin Chambolle, Jean_Baptiste Caillau

Auto-TLDR; A Constrained Primal-dual Method for Structured Feature Selection on High Dimensional Data
Abstract Slides Poster Similar
Graph Approximations to Geodesics on Metric Graphs
Robin Vandaele, Yvan Saeys, Tijl De Bie

Auto-TLDR; Topological Pattern Recognition of Metric Graphs Using Proximity Graphs
Abstract Slides Poster Similar
Directional Graph Networks with Hard Weight Assignments
Miguel Dominguez, Raymond Ptucha

Auto-TLDR; Hard Directional Graph Networks for Point Cloud Analysis
Abstract Slides Poster Similar
Generalized Shortest Path-Based Superpixels for Accurate Segmentation of Spherical Images
Rémi Giraud, Rodrigo Borba Pinheiro, Yannick Berthoumieu

Auto-TLDR; SPS: Spherical Shortest Path-based Superpixels
Abstract Slides Poster Similar
Offset Curves Loss for Imbalanced Problem in Medical Segmentation
Ngan Le, Duc Toan Bui, Khoa Luu, Marios Savvides

Auto-TLDR; Offset Curves Loss for Medical Image Segmentation
GraphBGS: Background Subtraction Via Recovery of Graph Signals
Jhony Heriberto Giraldo Zuluaga, Thierry Bouwmans

Auto-TLDR; Graph BackGround Subtraction using Graph Signals
Abstract Slides Poster Similar
Graph Discovery for Visual Test Generation
Neil Hallonquist, Laurent Younes, Donald Geman

Auto-TLDR; Visual Question Answering over Graphs: A Probabilistic Framework for VQA
Abstract Slides Poster Similar
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
3D Semantic Labeling of Photogrammetry Meshes Based on Active Learning
Mengqi Rong, Shuhan Shen, Zhanyi Hu

Auto-TLDR; 3D Semantic Expression of Urban Scenes Based on Active Learning
Abstract Slides Poster Similar
Learning Sign-Constrained Support Vector Machines
Kenya Tajima, Kouhei Tsuchida, Esmeraldo Ronnie Rey Zara, Naoya Ohta, Tsuyoshi Kato

Auto-TLDR; Constrained Sign Constraints for Learning Linear Support Vector Machine
Fast Blending of Planar Shapes Based on Invariant Invertible and Stable Descriptors
Emna Ghorbel, Faouzi Ghorbel, Ines Sakly, Slim Mhiri

Auto-TLDR; Fined-Fourier-based Invariant Descriptor for Planar Shape Blending
Abstract Slides Poster Similar
Incorporating a Graph-Matching Algorithm into a Muscle Mechanics Model
Jose Luis Santacruz Muñoz, Francesc Serratosa

Auto-TLDR; Recomputing the Mesh Grid for Differential Models of the Muscle Mechanics
Abstract Slides Poster Similar
Generalized Conics: Properties and Applications
Aysylu Gabdulkhakova, Walter Kropatsch

Auto-TLDR; A Generalized Conic Representation for Distance Fields
Abstract Slides Poster Similar
Hcore-Init: Neural Network Initialization Based on Graph Degeneracy
Stratis Limnios, George Dasoulas, Dimitrios Thilikos, Michalis Vazirgiannis

Auto-TLDR; K-hypercore: Graph Mining for Deep Neural Networks
Abstract Slides Poster Similar
Revisiting Graph Neural Networks: Graph Filtering Perspective
Hoang Nguyen-Thai, Takanori Maehara, Tsuyoshi Murata

Auto-TLDR; Two-Layers Graph Convolutional Network with Graph Filters Neural Network
Abstract Slides Poster Similar
Unveiling Groups of Related Tasks in Multi-Task Learning
Jordan Frecon, Saverio Salzo, Massimiliano Pontil

Auto-TLDR; Continuous Bilevel Optimization for Multi-Task Learning
Abstract Slides Poster Similar
Graph Convolutional Neural Networks for Power Line Outage Identification

Auto-TLDR; Graph Convolutional Networks for Power Line Outage Identification
Unconstrained Vision Guided UAV Based Safe Helicopter Landing
Arindam Sikdar, Abhimanyu Sahu, Debajit Sen, Rohit Mahajan, Ananda Chowdhury

Auto-TLDR; Autonomous Helicopter Landing in Hazardous Environments from Unmanned Aerial Images Using Constrained Graph Clustering
Abstract Slides Poster Similar
Soft Label and Discriminant Embedding Estimation for Semi-Supervised Classification
Fadi Dornaika, Abdullah Baradaaji, Youssof El Traboulsi

Auto-TLDR; Semi-supervised Semi-Supervised Learning for Linear Feature Extraction and Label Propagation
Abstract Slides Poster Similar
Feature Extraction by Joint Robust Discriminant Analysis and Inter-Class Sparsity

Auto-TLDR; Robust Discriminant Analysis with Feature Selection and Inter-class Sparsity (RDA_FSIS)
Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin, Valsasina Paola, Michael Dayan, Sebastiano Vascon, Tessadori Jacopo, Filippi Massimo, Vittorio Murino, A Rocca Maria, Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Probabilistic Word Embeddings in Kinematic Space
Adarsh Jamadandi, Rishabh Tigadoli, Ramesh Ashok Tabib, Uma Mudenagudi

Auto-TLDR; Kinematic Space for Hierarchical Representation Learning
Abstract Slides Poster Similar
On the Global Self-attention Mechanism for Graph Convolutional Networks

Auto-TLDR; Global Self-Attention Mechanism for Graph Convolutional Networks
Graph-Based Interpolation of Feature Vectors for Accurate Few-Shot Classification
Yuqing Hu, Vincent Gripon, Stéphane Pateux

Auto-TLDR; Transductive Learning for Few-Shot Classification using Graph Neural Networks
Abstract Slides Poster Similar
Improved Time-Series Clustering with UMAP Dimension Reduction Method
Clément Pealat, Vincent Cheutet, Guillaume Bouleux

Auto-TLDR; Time Series Clustering with UMAP as a Pre-processing Step
Abstract Slides Poster Similar
Fast Subspace Clustering Based on the Kronecker Product
Lei Zhou, Xiao Bai, Liang Zhang, Jun Zhou, Edwin Hancock

Auto-TLDR; Subspace Clustering with Kronecker Product for Large Scale Datasets
Abstract Slides Poster Similar
Learning Sparse Deep Neural Networks Using Efficient Structured Projections on Convex Constraints for Green AI
Michel Barlaud, Frederic Guyard

Auto-TLDR; Constrained Deep Neural Network with Constrained Splitting Projection
Abstract Slides Poster Similar
2D Discrete Mirror Transform for Image Non-Linear Approximation
Alessandro Gnutti, Fabrizio Guerrini, Riccardo Leonardi

Auto-TLDR; Discrete Mirror Transform (DMT)
Abstract Slides Poster Similar
Combined Invariants to Gaussian Blur and Affine Transformation
Jitka Kostkova, Jan Flusser, Matteo Pedone

Auto-TLDR; A new theory of combined moment invariants to Gaussian blur and spatial affine transformation
Abstract Slides Poster Similar
Sketch-Based Community Detection Via Representative Node Sampling
Mahlagha Sedghi, Andre Beckus, George Atia

Auto-TLDR; Sketch-based Clustering of Community Detection Using a Small Sketch
Abstract Slides Poster Similar
Content-Sensitive Superpixels Based on Adaptive Regrowth

Auto-TLDR; Adaptive Regrowth for Content-Sensitive Superpixels
Abstract Slides Poster Similar
Learning Connectivity with Graph Convolutional Networks

Auto-TLDR; Learning Graph Convolutional Networks Using Topological Properties of Graphs
Abstract Slides Poster Similar
Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Abstract Slides Poster Similar
Anime Sketch Colorization by Component-Based Matching Using Deep Appearance Features and Graph Representation
Thien Do, Pham Van, Anh Nguyen, Trung Dang, Quoc Nguyen, Bach Hoang, Giao Nguyen

Auto-TLDR; Combining Deep Learning and Graph Representation for Sketch Colorization
Abstract Slides Poster Similar
Classification of Intestinal Gland Cell-Graphs Using Graph Neural Networks
Linda Studer, Jannis Wallau, Heather Dawson, Inti Zlobec, Andreas Fischer

Auto-TLDR; Graph Neural Networks for Classification of Dysplastic Gland Glands using Graph Neural Networks
Abstract Slides Poster Similar
Force Banner for the Recognition of Spatial Relations
Robin Deléarde, Camille Kurtz, Laurent Wendling, Philippe Dejean

Auto-TLDR; Spatial Relation Recognition using Force Banners
Cluster-Size Constrained Network Partitioning
Maksim Mironov, Konstantin Avrachenkov

Auto-TLDR; Unsupervised Graph Clustering with Stochastic Block Model
Abstract Slides Poster Similar
Supervised Classification Using Graph-Based Space Partitioning for Multiclass Problems
Nicola Yanev, Ventzeslav Valev, Adam Krzyzak, Karima Ben Suliman

Auto-TLDR; Box Classifier for Multiclass Classification
Abstract Slides Poster Similar
A Riemannian Framework for Detecting Stimulus-Relevant Fiber Pathways
Jingyong Su, Linlin Tang, Zhipeng Yang, Mengmeng Guo

Auto-TLDR; Clustering Task-Specific Fiber Pathways in Functional MRI using BOLD Signals
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar