Combined Invariants to Gaussian Blur and Affine Transformation
Jitka Kostkova,
Jan Flusser,
Matteo Pedone

Auto-TLDR; A new theory of combined moment invariants to Gaussian blur and spatial affine transformation
Similar papers
Understanding When Spatial Transformer Networks Do Not Support Invariance, and What to Do about It
Lukas Finnveden, Ylva Jansson, Tony Lindeberg

Auto-TLDR; Spatial Transformer Networks are unable to support invariance when transforming CNN feature maps
Abstract Slides Poster Similar
DCT/IDCT Filter Design for Ultrasound Image Filtering
Barmak Honarvar Shakibaei Asli, Jan Flusser, Yifan Zhao, John Ahmet Erkoyuncu, Rajkumar Roy

Auto-TLDR; Finite impulse response digital filter using DCT-II and inverse DCT
Abstract Slides Poster Similar
Exploring the Ability of CNNs to Generalise to Previously Unseen Scales Over Wide Scale Ranges

Auto-TLDR; A theoretical analysis of invariance and covariance properties of scale channel networks
Abstract Slides Poster Similar
A Globally Optimal Method for the PnP Problem with MRP Rotation Parameterization
Manolis Lourakis, George Terzakis

Auto-TLDR; A Direct least squares, algebraic PnP solver with modified Rodrigues parameters
Fast Blending of Planar Shapes Based on Invariant Invertible and Stable Descriptors
Emna Ghorbel, Faouzi Ghorbel, Ines Sakly, Slim Mhiri

Auto-TLDR; Fined-Fourier-based Invariant Descriptor for Planar Shape Blending
Abstract Slides Poster Similar
Chebyshev-Harmonic-Fourier-Moments and Deep CNNs for Detecting Forged Handwriting
Lokesh Nandanwar, Shivakumara Palaiahnakote, Kundu Sayani, Umapada Pal, Tong Lu, Daniel Lopresti

Auto-TLDR; Chebyshev-Harmonic-Fourier-Moments and Deep Convolutional Neural Networks for forged handwriting detection
Abstract Slides Poster Similar
Stabilized Calculation of Gaussian Smoothing and Its Differentials Using Attenuated Sliding Fourier Transform
Yukihiko Yamashita, Toru Wakahara

Auto-TLDR; An attenuated SFT for Gaussian smoothing
Abstract Slides Poster Similar
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
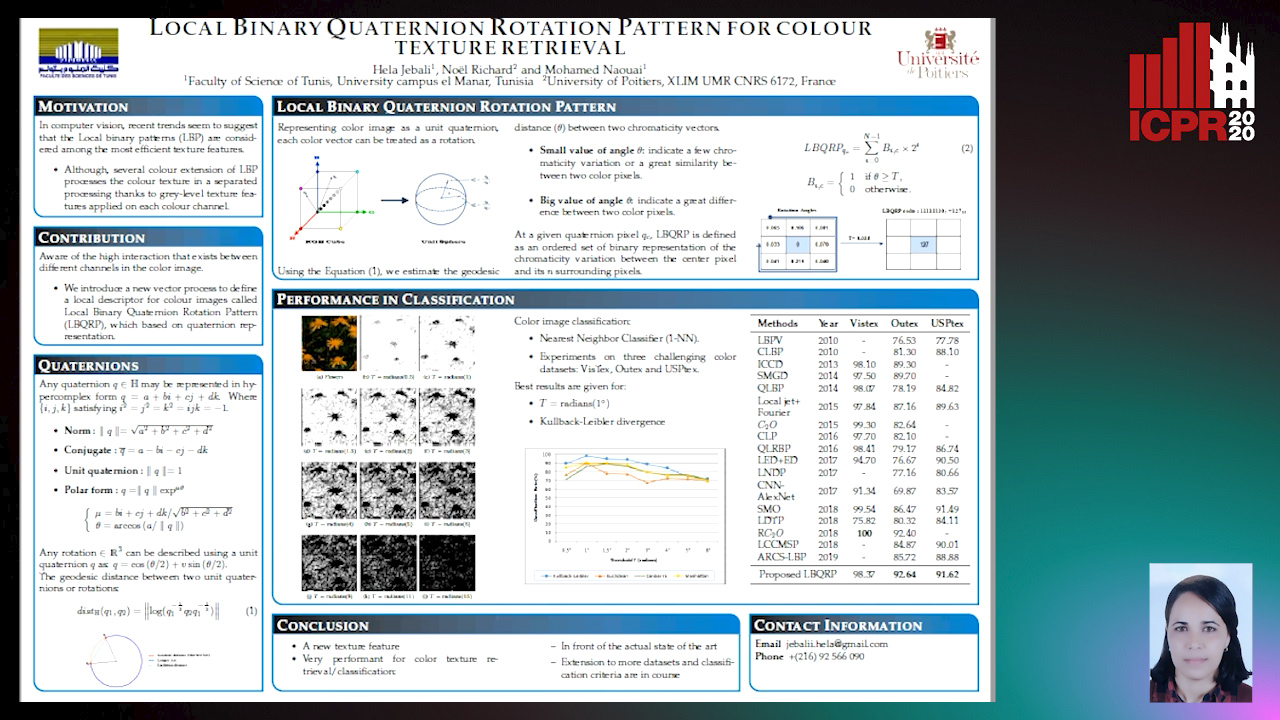
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Gaussian Convolution Angles: Invariant Vein and Texture Descriptors for Butterfly Species Identification
Xin Chen, Bin Wang, Yongsheng Gao

Auto-TLDR; Gaussian convolution angle for butterfly species classification
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Minimal Solvers for Indoor UAV Positioning
Marcus Valtonen Örnhag, Patrik Persson, Mårten Wadenbäck, Kalle Åström, Anders Heyden

Auto-TLDR; Relative Pose Solvers for Visual Indoor UAV Navigation
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
D3Net: Joint Demosaicking, Deblurring and Deringing
Tomas Kerepecky, Filip Sroubek

Auto-TLDR; Joint demosaicking deblurring and deringing network with light-weight architecture inspired by the alternating direction method of multipliers
Bayesian Active Learning for Maximal Information Gain on Model Parameters
Kasra Arnavaz, Aasa Feragen, Oswin Krause, Marco Loog

Auto-TLDR; Bayesian assumptions for Bayesian classification
Abstract Slides Poster Similar
Graph Signal Active Contours

Auto-TLDR; Adaptation of Active Contour Without Edges for Graph Signal Processing
Multi-Scale Keypoint Matching

Auto-TLDR; Multi-Scale Keypoint Matching Using Multi-Scale Information
Abstract Slides Poster Similar
Ultrasound Image Restoration Using Weighted Nuclear Norm Minimization
Hanmei Yang, Ye Luo, Jianwei Lu, Jian Lu

Auto-TLDR; A Nonconvex Low-Rank Matrix Approximation Model for Ultrasound Images Restoration
Phase Retrieval Using Conditional Generative Adversarial Networks
Tobias Uelwer, Alexander Oberstraß, Stefan Harmeling

Auto-TLDR; Conditional Generative Adversarial Networks for Phase Retrieval
Abstract Slides Poster Similar
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
Revisiting Graph Neural Networks: Graph Filtering Perspective
Hoang Nguyen-Thai, Takanori Maehara, Tsuyoshi Murata

Auto-TLDR; Two-Layers Graph Convolutional Network with Graph Filters Neural Network
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
GraphBGS: Background Subtraction Via Recovery of Graph Signals
Jhony Heriberto Giraldo Zuluaga, Thierry Bouwmans

Auto-TLDR; Graph BackGround Subtraction using Graph Signals
Abstract Slides Poster Similar
Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Abstract Slides Poster Similar
Learning Stable Deep Predictive Coding Networks with Weight Norm Supervision

Auto-TLDR; Stability of Predictive Coding Network with Weight Norm Supervision
Abstract Slides Poster Similar
PointSpherical: Deep Shape Context for Point Cloud Learning in Spherical Coordinates
Hua Lin, Bin Fan, Yongcheng Liu, Yirong Yang, Zheng Pan, Jianbo Shi, Chunhong Pan, Huiwen Xie

Auto-TLDR; Spherical Hierarchical Modeling of 3D Point Cloud
Abstract Slides Poster Similar
2D Discrete Mirror Transform for Image Non-Linear Approximation
Alessandro Gnutti, Fabrizio Guerrini, Riccardo Leonardi

Auto-TLDR; Discrete Mirror Transform (DMT)
Abstract Slides Poster Similar
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
Localization and Transformation Reconstruction of Image Regions: An Extended Congruent Triangles Approach
Afra'A Ahmad Alyosef, Christian Elias, Andreas Nürnberger

Auto-TLDR; Outlier Filtering of Sub-Image Relations using Geometrical Information
Abstract Slides Poster Similar
Batch-Incremental Triplet Sampling for Training Triplet Networks Using Bayesian Updating Theorem
Milad Sikaroudi, Benyamin Ghojogh, Fakhri Karray, Mark Crowley, Hamid Reza Tizhoosh

Auto-TLDR; Bayesian Updating Triplet Mining with Bayesian updating
Abstract Slides Poster Similar
HP2IFS: Head Pose Estimation Exploiting Partitioned Iterated Function Systems
Carmen Bisogni, Michele Nappi, Chiara Pero, Stefano Ricciardi

Auto-TLDR; PIFS based head pose estimation using fractal coding theory and Partitioned Iterated Function Systems
Abstract Slides Poster Similar
Generalized Conics: Properties and Applications
Aysylu Gabdulkhakova, Walter Kropatsch

Auto-TLDR; A Generalized Conic Representation for Distance Fields
Abstract Slides Poster Similar
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
3D Pots Configuration System by Optimizing Over Geometric Constraints
Jae Eun Kim, Muhammad Zeeshan Arshad, Seong Jong Yoo, Je Hyeong Hong, Jinwook Kim, Young Min Kim

Auto-TLDR; Optimizing 3D Configurations for Stable Pottery Restoration from irregular and noisy evidence
Abstract Slides Poster Similar
Total Whitening for Online Signature Verification Based on Deep Representation
Xiaomeng Wu, Akisato Kimura, Kunio Kashino, Seiichi Uchida

Auto-TLDR; Total Whitening for Online Signature Verification
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Graph Convolutional Neural Networks for Power Line Outage Identification

Auto-TLDR; Graph Convolutional Networks for Power Line Outage Identification
Interpolation in Auto Encoders with Bridge Processes
Carl Ringqvist, Henrik Hult, Judith Butepage, Hedvig Kjellstrom

Auto-TLDR; Stochastic interpolations from auto encoders trained on flattened sequences
Abstract Slides Poster Similar
Force Banner for the Recognition of Spatial Relations
Robin Deléarde, Camille Kurtz, Laurent Wendling, Philippe Dejean

Auto-TLDR; Spatial Relation Recognition using Force Banners
Calibration and Absolute Pose Estimation of Trinocular Linear Camera Array for Smart City Applications
Martin Ahrnbom, Mikael Nilsson, Håkan Ardö, Kalle Åström, Oksana Yastremska-Kravchenko, Aliaksei Laureshyn

Auto-TLDR; Trinocular Linear Camera Array Calibration for Traffic Surveillance Applications
Abstract Slides Poster Similar
3CS Algorithm for Efficient Gaussian Process Model Retrieval
Fabian Berns, Kjeld Schmidt, Ingolf Bracht, Christian Beecks

Auto-TLDR; Efficient retrieval of Gaussian Process Models for large-scale data using divide-&-conquer-based approach
Abstract Slides Poster Similar
Computing Stable Resultant-Based Minimal Solvers by Hiding a Variable
Snehal Bhayani, Zuzana Kukelova, Janne Heikkilä

Auto-TLDR; Sparse Permian-Based Method for Solving Minimal Systems of Polynomial Equations
Transferable Model for Shape Optimization subject to Physical Constraints
Lukas Harsch, Johannes Burgbacher, Stefan Riedelbauch

Auto-TLDR; U-Net with Spatial Transformer Network for Flow Simulations
Abstract Slides Poster Similar
A Multilinear Sampling Algorithm to Estimate Shapley Values

Auto-TLDR; A sampling method for Shapley values for multilayer Perceptrons
Abstract Slides Poster Similar
A Hierarchical Framework for Leaf Instance Segmentation: Application to Plant Phenotyping
Swati Bhugra, Kanish Garg, Santanu Chaudhury, Brejesh Lall

Auto-TLDR; Under-segmentation of plant image using a graph based formulation to extract leaf shape knowledge for the task of leaf instance segmentation
Abstract Slides Poster Similar
T-SVD Based Non-Convex Tensor Completion and Robust Principal Component Analysis

Auto-TLDR; Non-Convex tensor rank surrogate function and non-convex sparsity measure for tensor recovery
Abstract Slides Poster Similar