Gaussian Convolution Angles: Invariant Vein and Texture Descriptors for Butterfly Species Identification
Xin Chen,
Bin Wang,
Yongsheng Gao

Auto-TLDR; Gaussian convolution angle for butterfly species classification
Similar papers
Color Texture Description Based on Holistic and Hierarchical Order-Encoding Patterns
Tiecheng Song, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; Holistic and Hierarchical Order-Encoding Patterns for Color Texture Classification
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
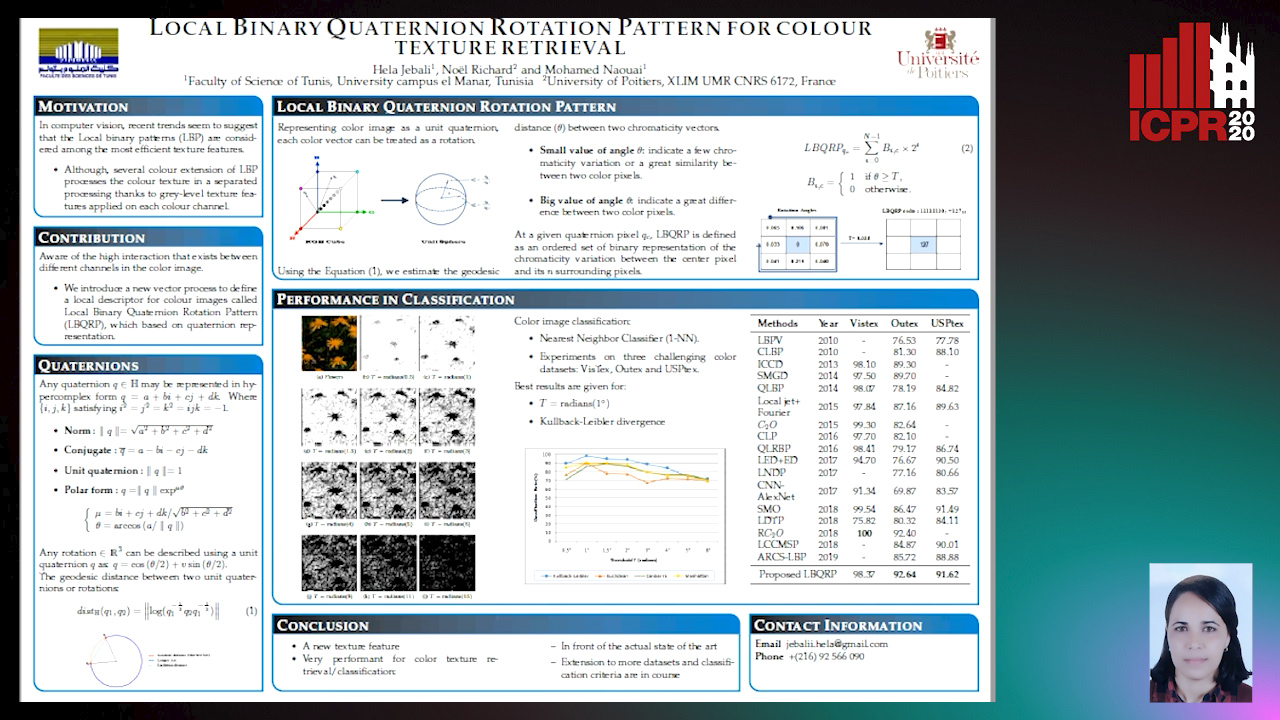
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
First and Second-Order Sorted Local Binary Pattern Features for Grayscale-Inversion and Rotation Invariant Texture Classification
Tiecheng Song, Yuanjing Han, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; First- and Secondorder Sorted Local Binary Pattern for texture classification under inverse grayscale changes and image rotation
Abstract Slides Poster Similar
Local Grouped Invariant Order Pattern for Grayscale-Inversion and Rotation Invariant Texture Classification
Yankai Huang, Tiecheng Song, Shuang Li, Yuanjing Han

Auto-TLDR; Local grouped invariant order pattern for grayscale-inversion and rotation invariant texture classification
Abstract Slides Poster Similar
A Local Descriptor with Physiological Characteristic for Finger Vein Recognition
Liping Zhang, Weijun Li, Ning Xin

Auto-TLDR; Finger vein-specific local feature descriptors based physiological characteristic of finger vein patterns
Abstract Slides Poster Similar
Combined Invariants to Gaussian Blur and Affine Transformation
Jitka Kostkova, Jan Flusser, Matteo Pedone

Auto-TLDR; A new theory of combined moment invariants to Gaussian blur and spatial affine transformation
Abstract Slides Poster Similar
3D Dental Biometrics: Automatic Pose-Invariant Dental Arch Extraction and Matching

Auto-TLDR; Automatic Dental Arch Extraction and Matching for 3D Dental Identification using Laser-Scanned Plasters
Abstract Slides Poster Similar
Rotation Detection in Finger Vein Biometrics Using CNNs
Bernhard Prommegger, Georg Wimmer, Andreas Uhl

Auto-TLDR; A CNN based rotation detector for finger vein recognition
Abstract Slides Poster Similar
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
Face Anti-Spoofing Based on Dynamic Color Texture Analysis Using Local Directional Number Pattern
Junwei Zhou, Ke Shu, Peng Liu, Jianwen Xiang, Shengwu Xiong

Auto-TLDR; LDN-TOP Representation followed by ProCRC Classification for Face Anti-Spoofing
Abstract Slides Poster Similar
PointSpherical: Deep Shape Context for Point Cloud Learning in Spherical Coordinates
Hua Lin, Bin Fan, Yongcheng Liu, Yirong Yang, Zheng Pan, Jianbo Shi, Chunhong Pan, Huiwen Xie

Auto-TLDR; Spherical Hierarchical Modeling of 3D Point Cloud
Abstract Slides Poster Similar
Modeling Extent-Of-Texture Information for Ground Terrain Recognition
Shuvozit Ghose, Pinaki Nath Chowdhury, Partha Pratim Roy, Umapada Pal

Auto-TLDR; Extent-of-Texture Guided Inter-domain Message Passing for Ground Terrain Recognition
Abstract Slides Poster Similar
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Hyunseung Chung, Woo-Jeoung Nam, Seong-Whan Lee

Auto-TLDR; Robust Remote Sensing Image Retrieval Using Group Convolution with Attention Mechanism and Metric Learning
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Multi-Scale Keypoint Matching

Auto-TLDR; Multi-Scale Keypoint Matching Using Multi-Scale Information
Abstract Slides Poster Similar
A Hierarchical Framework for Leaf Instance Segmentation: Application to Plant Phenotyping
Swati Bhugra, Kanish Garg, Santanu Chaudhury, Brejesh Lall

Auto-TLDR; Under-segmentation of plant image using a graph based formulation to extract leaf shape knowledge for the task of leaf instance segmentation
Abstract Slides Poster Similar
Force Banner for the Recognition of Spatial Relations
Robin Deléarde, Camille Kurtz, Laurent Wendling, Philippe Dejean

Auto-TLDR; Spatial Relation Recognition using Force Banners
Quantization in Relative Gradient Angle Domain for Building Polygon Estimation
Yuhao Chen, Yifan Wu, Linlin Xu, Alexander Wong

Auto-TLDR; Relative Gradient Angle Transform for Building Footprint Extraction from Remote Sensing Data
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Visual Saliency Oriented Vehicle Scale Estimation
Qixin Chen, Tie Liu, Jiali Ding, Zejian Yuan, Yuanyuan Shang

Auto-TLDR; Regularized Intensity Matching for Vehicle Scale Estimation with salient object detection
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
Walk the Lines: Object Contour Tracing CNN for Contour Completion of Ships

Auto-TLDR; Walk the Lines: A Convolutional Neural Network trained to follow object contours
Abstract Slides Poster Similar
Fast Blending of Planar Shapes Based on Invariant Invertible and Stable Descriptors
Emna Ghorbel, Faouzi Ghorbel, Ines Sakly, Slim Mhiri

Auto-TLDR; Fined-Fourier-based Invariant Descriptor for Planar Shape Blending
Abstract Slides Poster Similar
Three-Dimensional Lip Motion Network for Text-Independent Speaker Recognition
Jianrong Wang, Tong Wu, Shanyu Wang, Mei Yu, Qiang Fang, Ju Zhang, Li Liu

Auto-TLDR; Lip Motion Network for Text-Independent and Text-Dependent Speaker Recognition
Abstract Slides Poster Similar
Object Classification of Remote Sensing Images Based on Optimized Projection Supervised Discrete Hashing
Qianqian Zhang, Yazhou Liu, Quansen Sun

Auto-TLDR; Optimized Projection Supervised Discrete Hashing for Large-Scale Remote Sensing Image Object Classification
Abstract Slides Poster Similar
Multi-Attribute Regression Network for Face Reconstruction

Auto-TLDR; A Multi-Attribute Regression Network for Face Reconstruction
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
On Identification and Retrieval of Near-Duplicate Biological Images: A New Dataset and Protocol
Thomas E. Koker, Sai Spandana Chintapalli, San Wang, Blake A. Talbot, Daniel Wainstock, Marcelo Cicconet, Mary C. Walsh

Auto-TLDR; BINDER: Bio-Image Near-Duplicate Examples Repository for Image Identification and Retrieval
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Localization and Transformation Reconstruction of Image Regions: An Extended Congruent Triangles Approach
Afra'A Ahmad Alyosef, Christian Elias, Andreas Nürnberger

Auto-TLDR; Outlier Filtering of Sub-Image Relations using Geometrical Information
Abstract Slides Poster Similar
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Dongfang Liu, Yiming Cui, Xiaolei Guo, Wei Ding, Baijian Yang, Yingjie Chen

Auto-TLDR; Feature Voting for Robust Visual Localization in Urban Settings
Abstract Slides Poster Similar
Finger Vein Recognition and Intra-Subject Similarity Evaluation of Finger Veins Using the CNN Triplet Loss
Georg Wimmer, Bernhard Prommegger, Andreas Uhl

Auto-TLDR; Finger vein recognition using CNNs and hard triplet online selection
Abstract Slides Poster Similar
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
A Multi-Focus Image Fusion Method Based on Fractal Dimension and Guided Filtering
Nikoo Dehghani, Ehsanollah Kabir

Auto-TLDR; Fractal Dimension-based Multi-focus Image Fusion with Guide Filtering
Abstract Slides Poster Similar
Generalized Shortest Path-Based Superpixels for Accurate Segmentation of Spherical Images
Rémi Giraud, Rodrigo Borba Pinheiro, Yannick Berthoumieu

Auto-TLDR; SPS: Spherical Shortest Path-based Superpixels
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Detecting Marine Species in Echograms Via Traditional, Hybrid, and Deep Learning Frameworks
Porto Marques Tunai, Alireza Rezvanifar, Melissa Cote, Alexandra Branzan Albu, Kaan Ersahin, Todd Mudge, Stephane Gauthier

Auto-TLDR; End-to-End Deep Learning for Echogram Interpretation of Marine Species in Echograms
Abstract Slides Poster Similar
HP2IFS: Head Pose Estimation Exploiting Partitioned Iterated Function Systems
Carmen Bisogni, Michele Nappi, Chiara Pero, Stefano Ricciardi

Auto-TLDR; PIFS based head pose estimation using fractal coding theory and Partitioned Iterated Function Systems
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Chebyshev-Harmonic-Fourier-Moments and Deep CNNs for Detecting Forged Handwriting
Lokesh Nandanwar, Shivakumara Palaiahnakote, Kundu Sayani, Umapada Pal, Tong Lu, Daniel Lopresti

Auto-TLDR; Chebyshev-Harmonic-Fourier-Moments and Deep Convolutional Neural Networks for forged handwriting detection
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Improving Image Matching with Varied Illumination

Auto-TLDR; Optimizing Feature Matching for Stereo Image Pairs by Stereo Illumination
Abstract Slides Poster Similar
RSINet: Rotation-Scale Invariant Network for Online Visual Tracking
Yang Fang, Geunsik Jo, Chang-Hee Lee

Auto-TLDR; RSINet: Rotation-Scale Invariant Network for Adaptive Tracking
Abstract Slides Poster Similar
SIMCO: SIMilarity-Based Object COunting
Marco Godi, Christian Joppi, Andrea Giachetti, Marco Cristani

Auto-TLDR; SIMCO: An Unsupervised Multi-class Object Counting Approach on InShape
Abstract Slides Poster Similar