Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali,
Noel Richard,
Mohamed Naouai
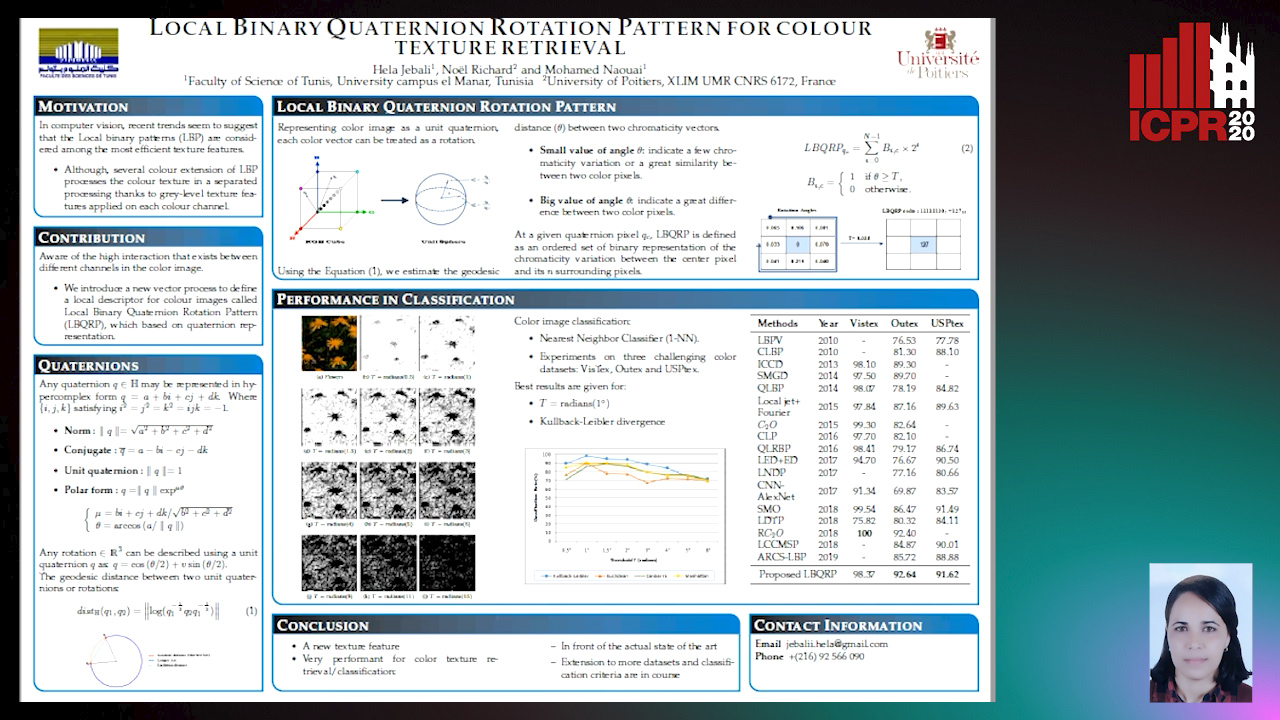
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
Similar papers
Color Texture Description Based on Holistic and Hierarchical Order-Encoding Patterns
Tiecheng Song, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; Holistic and Hierarchical Order-Encoding Patterns for Color Texture Classification
Abstract Slides Poster Similar
Local Grouped Invariant Order Pattern for Grayscale-Inversion and Rotation Invariant Texture Classification
Yankai Huang, Tiecheng Song, Shuang Li, Yuanjing Han

Auto-TLDR; Local grouped invariant order pattern for grayscale-inversion and rotation invariant texture classification
Abstract Slides Poster Similar
First and Second-Order Sorted Local Binary Pattern Features for Grayscale-Inversion and Rotation Invariant Texture Classification
Tiecheng Song, Yuanjing Han, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; First- and Secondorder Sorted Local Binary Pattern for texture classification under inverse grayscale changes and image rotation
Abstract Slides Poster Similar
Gaussian Convolution Angles: Invariant Vein and Texture Descriptors for Butterfly Species Identification
Xin Chen, Bin Wang, Yongsheng Gao

Auto-TLDR; Gaussian convolution angle for butterfly species classification
Abstract Slides Poster Similar
Graph Signal Active Contours

Auto-TLDR; Adaptation of Active Contour Without Edges for Graph Signal Processing
Face Anti-Spoofing Based on Dynamic Color Texture Analysis Using Local Directional Number Pattern
Junwei Zhou, Ke Shu, Peng Liu, Jianwen Xiang, Shengwu Xiong

Auto-TLDR; LDN-TOP Representation followed by ProCRC Classification for Face Anti-Spoofing
Abstract Slides Poster Similar
A Distinct Discriminant Canonical Correlation Analysis Network Based Deep Information Quality Representation for Image Classification
Lei Gao, Zheng Guo, Ling Guan Ling Guan

Auto-TLDR; DDCCANet: Deep Information Quality Representation for Image Classification
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Feature Extraction by Joint Robust Discriminant Analysis and Inter-Class Sparsity

Auto-TLDR; Robust Discriminant Analysis with Feature Selection and Inter-class Sparsity (RDA_FSIS)
Magnifying Spontaneous Facial Micro Expressions for Improved Recognition
Pratikshya Sharma, Sonya Coleman, Pratheepan Yogarajah, Laurence Taggart, Pradeepa Samarasinghe

Auto-TLDR; Eulerian Video Magnification for Micro Expression Recognition
Abstract Slides Poster Similar
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Feature Extraction and Selection Via Robust Discriminant Analysis and Class Sparsity

Auto-TLDR; Hybrid Linear Discriminant Embedding for supervised multi-class classification
Abstract Slides Poster Similar
Force Banner for the Recognition of Spatial Relations
Robin Deléarde, Camille Kurtz, Laurent Wendling, Philippe Dejean

Auto-TLDR; Spatial Relation Recognition using Force Banners
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
A Globally Optimal Method for the PnP Problem with MRP Rotation Parameterization
Manolis Lourakis, George Terzakis

Auto-TLDR; A Direct least squares, algebraic PnP solver with modified Rodrigues parameters
Quaternion Capsule Networks
Barış Özcan, Furkan Kınlı, Mustafa Furkan Kirac

Auto-TLDR; Quaternion Capsule Networks for Object Recognition
Abstract Slides Poster Similar
Multi-Scale Keypoint Matching

Auto-TLDR; Multi-Scale Keypoint Matching Using Multi-Scale Information
Abstract Slides Poster Similar
Combined Invariants to Gaussian Blur and Affine Transformation
Jitka Kostkova, Jan Flusser, Matteo Pedone

Auto-TLDR; A new theory of combined moment invariants to Gaussian blur and spatial affine transformation
Abstract Slides Poster Similar
Improved Time-Series Clustering with UMAP Dimension Reduction Method
Clément Pealat, Vincent Cheutet, Guillaume Bouleux

Auto-TLDR; Time Series Clustering with UMAP as a Pre-processing Step
Abstract Slides Poster Similar
Generalized Shortest Path-Based Superpixels for Accurate Segmentation of Spherical Images
Rémi Giraud, Rodrigo Borba Pinheiro, Yannick Berthoumieu

Auto-TLDR; SPS: Spherical Shortest Path-based Superpixels
Abstract Slides Poster Similar
HP2IFS: Head Pose Estimation Exploiting Partitioned Iterated Function Systems
Carmen Bisogni, Michele Nappi, Chiara Pero, Stefano Ricciardi

Auto-TLDR; PIFS based head pose estimation using fractal coding theory and Partitioned Iterated Function Systems
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin, Valsasina Paola, Michael Dayan, Sebastiano Vascon, Tessadori Jacopo, Filippi Massimo, Vittorio Murino, A Rocca Maria, Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Abstract Slides Poster Similar
Quality-Based Representation for Unconstrained Face Recognition
Nelson Méndez-Llanes, Katy Castillo-Rosado, Heydi Mendez-Vazquez, Massimo Tistarelli

Auto-TLDR; activation map for face recognition in unconstrained environments
A Local Descriptor with Physiological Characteristic for Finger Vein Recognition
Liping Zhang, Weijun Li, Ning Xin

Auto-TLDR; Finger vein-specific local feature descriptors based physiological characteristic of finger vein patterns
Abstract Slides Poster Similar
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
On Morphological Hierarchies for Image Sequences
Caglayan Tuna, Alain Giros, François Merciol, Sébastien Lefèvre

Auto-TLDR; Comparison of Hierarchies for Image Sequences
Abstract Slides Poster Similar
Probabilistic Word Embeddings in Kinematic Space
Adarsh Jamadandi, Rishabh Tigadoli, Ramesh Ashok Tabib, Uma Mudenagudi

Auto-TLDR; Kinematic Space for Hierarchical Representation Learning
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Hyunseung Chung, Woo-Jeoung Nam, Seong-Whan Lee

Auto-TLDR; Robust Remote Sensing Image Retrieval Using Group Convolution with Attention Mechanism and Metric Learning
Abstract Slides Poster Similar
Finger Vein Recognition and Intra-Subject Similarity Evaluation of Finger Veins Using the CNN Triplet Loss
Georg Wimmer, Bernhard Prommegger, Andreas Uhl

Auto-TLDR; Finger vein recognition using CNNs and hard triplet online selection
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
Directional Graph Networks with Hard Weight Assignments
Miguel Dominguez, Raymond Ptucha

Auto-TLDR; Hard Directional Graph Networks for Point Cloud Analysis
Abstract Slides Poster Similar
A Hierarchical Framework for Leaf Instance Segmentation: Application to Plant Phenotyping
Swati Bhugra, Kanish Garg, Santanu Chaudhury, Brejesh Lall

Auto-TLDR; Under-segmentation of plant image using a graph based formulation to extract leaf shape knowledge for the task of leaf instance segmentation
Abstract Slides Poster Similar
GraphBGS: Background Subtraction Via Recovery of Graph Signals
Jhony Heriberto Giraldo Zuluaga, Thierry Bouwmans

Auto-TLDR; Graph BackGround Subtraction using Graph Signals
Abstract Slides Poster Similar
Fixed Simplex Coordinates for Angular Margin Loss in CapsNet
Rita Pucci, Christian Micheloni, Gian Luca Foresti, Niki Martinel

Auto-TLDR; angular margin loss for capsule networks
Abstract Slides Poster Similar
Surface IR Reflectance Estimation and Material Recognition Using ToF Camera

Auto-TLDR; Material Type Recognition Using IR Reflectance Based Material Type Recognitions
Abstract Slides Poster Similar
Exploiting Local Indexing and Deep Feature Confidence Scores for Fast Image-To-Video Search
Savas Ozkan, Gözde Bozdağı Akar

Auto-TLDR; Fast and Robust Image-to-Video Retrieval Using Local and Global Descriptors
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
3D Point Cloud Registration Based on Cascaded Mutual Information Attention Network

Auto-TLDR; Cascaded Mutual Information Attention Network for 3D Point Cloud Registration
Abstract Slides Poster Similar
ESResNet: Environmental Sound Classification Based on Visual Domain Models
Andrey Guzhov, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Environmental Sound Classification with Short-Time Fourier Transform Spectrograms
Abstract Slides Poster Similar